Potrebbero piacerti anche
- NewboldDocumento45 pagineNewboldDino NotaNessuna valutazione finora
- Pendolo DoppioDocumento7 paginePendolo DoppioFrancesco Ficara0% (1)
- Relazione Chiodi e BulloniDocumento12 pagineRelazione Chiodi e Bullonigiulio141091Nessuna valutazione finora
- Cap 06 5edDocumento17 pagineCap 06 5edLAURA SERATONINessuna valutazione finora
- Cap 07 5edDocumento14 pagineCap 07 5edLAURA SERATONINessuna valutazione finora
- Logit Probit PDFDocumento31 pagineLogit Probit PDFDaniele PannunziNessuna valutazione finora
- Esercizi Calcolo Numerico UnipdDocumento44 pagineEsercizi Calcolo Numerico UnipdMattia NeseNessuna valutazione finora
- Progetto StatisticaDocumento21 pagineProgetto StatisticaPeroNessuna valutazione finora
- La VariabilitaDocumento16 pagineLa Variabilitablanc.emmeNessuna valutazione finora
- Test Diagnostici DicotomiciDocumento93 pagineTest Diagnostici Dicotomicisilvano andornoNessuna valutazione finora
- Pre Tarea Juana BDocumento20 paginePre Tarea Juana Bximena suarezNessuna valutazione finora
- 02 Fondamenti Di Analisi StatisticaDocumento34 pagine02 Fondamenti Di Analisi Statisticaemanueledesantis201Nessuna valutazione finora
- Diffrazione 2Documento9 pagineDiffrazione 2Tirton 701Nessuna valutazione finora
- Carta Di Controllo Per VariabiliDocumento53 pagineCarta Di Controllo Per VariabiliGarden005Nessuna valutazione finora
- G. Occhetta - Introduzione Alla Geometria DifferenzialeDocumento114 pagineG. Occhetta - Introduzione Alla Geometria DifferenzialeMatteo Grimaldi100% (1)
- Back Step PDFDocumento18 pagineBack Step PDFDaniele PannunziNessuna valutazione finora
- Analisi Statistica Di Dati BiomediciDocumento37 pagineAnalisi Statistica Di Dati BiomediciMANessuna valutazione finora
- Cap 05 5edDocumento19 pagineCap 05 5edLAURA SERATONINessuna valutazione finora
- Fuoco LentiDocumento9 pagineFuoco LentiTirton 701Nessuna valutazione finora
- Statistica DescrittivaDocumento58 pagineStatistica DescrittivaAeneaKeatsNessuna valutazione finora
- 4 - Regressione LineareDocumento44 pagine4 - Regressione LinearelippimargheritaNessuna valutazione finora
- 280313Documento4 pagine280313Matteo AnzanoNessuna valutazione finora
- DiffrazioneDocumento8 pagineDiffrazioneTirton 701Nessuna valutazione finora
- Trattamento Dei Dati AnaliticiDocumento52 pagineTrattamento Dei Dati Analiticibiagio castronovoNessuna valutazione finora
- Fisica MedicaDocumento222 pagineFisica Medicaeliatan86Nessuna valutazione finora
- Analisi Matematica II Esercizi e Soluzioni (Cicognani)Documento163 pagineAnalisi Matematica II Esercizi e Soluzioni (Cicognani)kylgoreNessuna valutazione finora
- Dinamica e Modellistica Della Turbolenza - Esercitazioni Del CorsoDocumento24 pagineDinamica e Modellistica Della Turbolenza - Esercitazioni Del CorsoAlfredo PatriziNessuna valutazione finora
- Analisi Di RegressioneDocumento131 pagineAnalisi Di Regressioneappuntiricerche50% (2)
- Esercizi Di StatisticaDocumento41 pagineEsercizi Di StatisticaMatteo GaioNessuna valutazione finora
- Indicazioni Analisi DatiDocumento20 pagineIndicazioni Analisi Datilorenz_rossatoNessuna valutazione finora
- Indici Di Variabilità e Di FormaDocumento19 pagineIndici Di Variabilità e Di FormaannaNessuna valutazione finora
- Picket Manual Part 4Documento4 paginePicket Manual Part 4Albino AntonioNessuna valutazione finora
- Relazione Dell'esperienza in Laboratorio Di Fisica: Il Pendolo Semplice.Documento10 pagineRelazione Dell'esperienza in Laboratorio Di Fisica: Il Pendolo Semplice.Giorgio GulloneNessuna valutazione finora
- GravitazioneDocumento15 pagineGravitazioneTirton 701Nessuna valutazione finora
- Econometria II - Laboratorio 2Documento6 pagineEconometria II - Laboratorio 2خورخي لويسNessuna valutazione finora
- Grafico X-R DiapositivasDocumento16 pagineGrafico X-R DiapositivasGeraldina RodriguezNessuna valutazione finora
- Strutture Deformabili TorsionalmenteDocumento11 pagineStrutture Deformabili TorsionalmenteAleksiey PellicciaNessuna valutazione finora
- 22 Acciaio Verifica Colonne Secondo EC3 - NTC PDFDocumento29 pagine22 Acciaio Verifica Colonne Secondo EC3 - NTC PDFr_zoro87Nessuna valutazione finora
- Forex-Analisi Delle Serie Storiche 1Documento41 pagineForex-Analisi Delle Serie Storiche 1Plutone CataniaNessuna valutazione finora
- Regressione Lineare Multivariata Con RDocumento5 pagineRegressione Lineare Multivariata Con RRaffaella BenettiNessuna valutazione finora
- Non Line AreDocumento14 pagineNon Line AregregoriopiccoliNessuna valutazione finora
- Eserciziario - Analisi 2Documento69 pagineEserciziario - Analisi 2dinobiagNessuna valutazione finora
- Preprocessamento Dei DatiDocumento17 paginePreprocessamento Dei Datipablo_escobar2Nessuna valutazione finora
- Incertezza Di MisuraDocumento11 pagineIncertezza Di MisuraAlw MmmNessuna valutazione finora
- Beta RegressionDocumento63 pagineBeta RegressionDevonNessuna valutazione finora
- ESTADISTICADocumento5 pagineESTADISTICAAbner Cilis Rebaza GuzmanNessuna valutazione finora
- Notes RobustDocumento40 pagineNotes RobustNICONessuna valutazione finora
- TraveComp-1 0Documento35 pagineTraveComp-1 0Nicola GambettiNessuna valutazione finora
- 01pendolosemplice PDFDocumento7 pagine01pendolosemplice PDFShervin RajabiNessuna valutazione finora
- RUOTE DENTATE - Esempio Di Calcolo - 1Documento10 pagineRUOTE DENTATE - Esempio Di Calcolo - 1Ane CorralNessuna valutazione finora
- EstensimetriDocumento48 pagineEstensimetriemanueledesantis201Nessuna valutazione finora
- es3Documento7 paginees3ppk5sgftvbNessuna valutazione finora
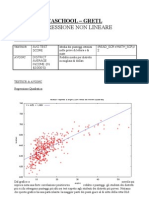
- Gretl - Caschool Nonlinear)Documento5 pagineGretl - Caschool Nonlinear)Roberta BarbiNessuna valutazione finora
- Portafoglio TitoliDocumento61 paginePortafoglio TitoliFilippo DolcettaNessuna valutazione finora
- Lab1 2019 13 PDFDocumento58 pagineLab1 2019 13 PDFKim DamianiNessuna valutazione finora
- 190913Documento2 pagine190913Matteo AnzanoNessuna valutazione finora
- Esercizi di matematica: funzioni reali a più variabiliDa EverandEsercizi di matematica: funzioni reali a più variabiliNessuna valutazione finora
- Esercizi di matematica: studio di funzioni a variabile realeDa EverandEsercizi di matematica: studio di funzioni a variabile realeNessuna valutazione finora
- Domini di resistenza in pressoflessione deviata per sezioni in c.a.: procedura parametrica per il tracciamento e confronti con formulazioni semplificateDa EverandDomini di resistenza in pressoflessione deviata per sezioni in c.a.: procedura parametrica per il tracciamento e confronti con formulazioni semplificateNessuna valutazione finora
- Esercizi di matematica: integrali di linea, di superficie e di volumeDa EverandEsercizi di matematica: integrali di linea, di superficie e di volumeValutazione: 4 su 5 stelle4/5 (2)