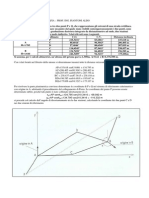
Potrebbero piacerti anche
- Esercizi SvoltiDocumento20 pagineEsercizi Svoltipeter_rungaldienNessuna valutazione finora
- Esercizi Svolti - Circuiti in Corrente AlternataDocumento9 pagineEsercizi Svolti - Circuiti in Corrente AlternataFlavia IserniaNessuna valutazione finora
- Esercizi - I VettoriDocumento10 pagineEsercizi - I Vettorivin_hiworldNessuna valutazione finora
- DIM. ALBERO Solo FaticaDocumento8 pagineDIM. ALBERO Solo FaticaAne CorralNessuna valutazione finora
- Esercizi Ec2 Sedra SmithDocumento51 pagineEsercizi Ec2 Sedra SmithLudovica AcciaiNessuna valutazione finora
- Quaderno 2 PDFDocumento47 pagineQuaderno 2 PDFGianluca de RisiNessuna valutazione finora
- Esercizi Di Progetto Di ElettronicaDocumento20 pagineEsercizi Di Progetto Di ElettronicaGiovanni ViciconteNessuna valutazione finora
- Relazione Tecnica Di Verifica Di Componenti Di Un MotoriduttoreDocumento38 pagineRelazione Tecnica Di Verifica Di Componenti Di Un MotoriduttoreFabio MoramarcoNessuna valutazione finora
- Principal Component AnalysisDocumento52 paginePrincipal Component AnalysisvillettaNessuna valutazione finora
- Formulario Acquedotti e FognatureDocumento11 pagineFormulario Acquedotti e FognatureSevero StocolaNessuna valutazione finora
- Proiect EconometrieDocumento12 pagineProiect EconometrieElisabeta Alexandra GologanNessuna valutazione finora
- Gretl - Caschool (Logaritmica)Documento4 pagineGretl - Caschool (Logaritmica)Roberta BarbiNessuna valutazione finora
- Gretl - Caschool (Multipla)Documento9 pagineGretl - Caschool (Multipla)Silvia BoscatoNessuna valutazione finora
- Newbold Solved ExercisesDocumento12 pagineNewbold Solved ExercisesFlora Triolo100% (2)
- Gretl - CaschoolDocumento4 pagineGretl - CaschoolRoberta BarbiNessuna valutazione finora
- Cap 07 5edDocumento14 pagineCap 07 5edLAURA SERATONINessuna valutazione finora
- Calcolo Del Trasformatore 50 KVADocumento5 pagineCalcolo Del Trasformatore 50 KVAGianfranco RuggieroNessuna valutazione finora
- Antonio Rizzi - (N.5) Relazione ElettronicaDocumento10 pagineAntonio Rizzi - (N.5) Relazione ElettronicaStefano SecciaNessuna valutazione finora
- Anova PDFDocumento18 pagineAnova PDFDaniele PannunziNessuna valutazione finora
- Muestreo Parte 3Documento12 pagineMuestreo Parte 3Martha IsteNessuna valutazione finora
- Progetto StatisticaDocumento21 pagineProgetto StatisticaPeroNessuna valutazione finora
- NewboldDocumento45 pagineNewboldDino NotaNessuna valutazione finora
- Relazione Chiodi e BulloniDocumento12 pagineRelazione Chiodi e Bullonigiulio141091Nessuna valutazione finora
- Regressione Lineare Multivariata Con RDocumento5 pagineRegressione Lineare Multivariata Con RRaffaella BenettiNessuna valutazione finora
- Cap 06 5edDocumento17 pagineCap 06 5edLAURA SERATONINessuna valutazione finora
- I 14 Esp2Documento15 pagineI 14 Esp2Federico RossiNessuna valutazione finora
- 1.1 Rete Di AdduzioneDocumento10 pagine1.1 Rete Di Adduzionelucat89Nessuna valutazione finora
- Tesina Circuiti Per L'elaborazione Dei SegnaliDocumento15 pagineTesina Circuiti Per L'elaborazione Dei SegnaliCarloGuarnieriNessuna valutazione finora
- Cap 05 5edDocumento19 pagineCap 05 5edLAURA SERATONINessuna valutazione finora
- JuanMontoya ControlADocumento14 pagineJuanMontoya ControlAadrianfeliperioscarmona686Nessuna valutazione finora
- Scilab - BodeDocumento14 pagineScilab - BodeDamiano ZitoNessuna valutazione finora
- Amplificatore Di Bassa Frequenza A BJTDocumento11 pagineAmplificatore Di Bassa Frequenza A BJTCenci SimoneNessuna valutazione finora
- Dominio Resistenza PilastroDocumento7 pagineDominio Resistenza PilastromenoveroliberoNessuna valutazione finora
- 1 Ejercicio Examen Final L.R.M.TDocumento4 pagine1 Ejercicio Examen Final L.R.M.TTITO FRANCISCO CARITA BUSTILLONessuna valutazione finora
- EsercitazioneDocumento12 pagineEsercitazioneLeonardoNessuna valutazione finora
- Professionali 2011Documento9 pagineProfessionali 2011Ortensia Del LagoNessuna valutazione finora
- Esercitazione 4Documento9 pagineEsercitazione 4LeonardoNessuna valutazione finora
- Ana2013 Der SolDocumento6 pagineAna2013 Der SolOsama BafiliNessuna valutazione finora
- Lab 49 Prob CertDocumento4 pagineLab 49 Prob CertGiannaFiloNessuna valutazione finora
- Esercizi: Metodo Delle ForzeDocumento21 pagineEsercizi: Metodo Delle ForzeAngelo LavinoNessuna valutazione finora
- Verifica A Fatica Dei Cuscinetti LucaDocumento4 pagineVerifica A Fatica Dei Cuscinetti LucaWilliam MoscaNessuna valutazione finora
- CP 6 - FiltriDocumento19 pagineCP 6 - FiltriAngela AmeruosoNessuna valutazione finora
- TentativiDocumento7 pagineTentativiNoemi SkizzataNessuna valutazione finora
- BootstrapDocumento5 pagineBootstrapPaolo RossiNessuna valutazione finora
- Esercitazione Controlli Automatici N°3Documento13 pagineEsercitazione Controlli Automatici N°3Alessandro PilloniNessuna valutazione finora
- BJT Collettore ComuneDocumento8 pagineBJT Collettore ComunePaolo RossiNessuna valutazione finora
- Eserciziario Stima IntervallareDocumento16 pagineEserciziario Stima IntervallareVictor MarcuNessuna valutazione finora
- Fuoco LentiDocumento9 pagineFuoco LentiTirton 701Nessuna valutazione finora
- Esercitazioni ImpiantiDocumento33 pagineEsercitazioni Impiantiannalisa_bracco9764Nessuna valutazione finora
- BJT Base ComuneDocumento7 pagineBJT Base ComunePaolo RossiNessuna valutazione finora
- Esercizi Di TopografiaDocumento23 pagineEsercizi Di TopografiaGiulia100% (2)
- Analisi Statistica Di Dati BiomediciDocumento37 pagineAnalisi Statistica Di Dati BiomediciMANessuna valutazione finora
- 01pendolosemplice PDFDocumento7 pagine01pendolosemplice PDFShervin RajabiNessuna valutazione finora
- Picket Manual Part 4Documento4 paginePicket Manual Part 4Albino AntonioNessuna valutazione finora
- Exac02 Esercizicircuitiac1 v1Documento15 pagineExac02 Esercizicircuitiac1 v1francescoNessuna valutazione finora
- Mos Serie ParalleloDocumento19 pagineMos Serie ParalleloAndrea ParodiNessuna valutazione finora
- Esercitazione Su Tir Van Con Soluzione 2020 03-23-10!22!25Documento8 pagineEsercitazione Su Tir Van Con Soluzione 2020 03-23-10!22!25Ana IsabelNessuna valutazione finora
- Esercizi Di Analisi MatematicaDocumento188 pagineEsercizi Di Analisi Matematicaprovola70Nessuna valutazione finora
- Esercizi di matematica: integrali di linea, di superficie e di volumeDa EverandEsercizi di matematica: integrali di linea, di superficie e di volumeNessuna valutazione finora