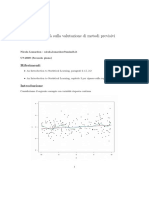
Potrebbero piacerti anche
- 280313Documento4 pagine280313Matteo AnzanoNessuna valutazione finora
- 250613Documento2 pagine250613Matteo AnzanoNessuna valutazione finora
- Compito 1Documento2 pagineCompito 1Janua CoeliNessuna valutazione finora
- Econometria 1Documento59 pagineEconometria 1Alessandra MirabileNessuna valutazione finora
- 4 - Regressione LineareDocumento44 pagine4 - Regressione LinearelippimargheritaNessuna valutazione finora
- Esame1 SoluzioniDocumento3 pagineEsame1 SoluzioniLuca BaldanziNessuna valutazione finora
- Hoja 5 20121Documento3 pagineHoja 5 20121Karolina GliwaNessuna valutazione finora
- Intro PredictionDocumento8 pagineIntro PredictionMattiaNessuna valutazione finora
- Testo Esame 26 06 2023Documento3 pagineTesto Esame 26 06 2023Andrea GreppiNessuna valutazione finora
- Appunti Di StatisticaDocumento10 pagineAppunti Di StatisticaIvan MilazzoNessuna valutazione finora
- Compitob 10-01-2023-Con SoluzioniDocumento4 pagineCompitob 10-01-2023-Con Soluzionituning.italia2015Nessuna valutazione finora
- Appunti Econometria 1 1Documento10 pagineAppunti Econometria 1 1a pNessuna valutazione finora
- 290814Documento2 pagine290814Matteo AnzanoNessuna valutazione finora
- Esercitazioni Di StatisticaDocumento18 pagineEsercitazioni Di StatisticaCarmine SoleNessuna valutazione finora
- Regressione LineareDocumento23 pagineRegressione LineareRaffaella BenettiNessuna valutazione finora
- Un Problema Di Logistica DocenteDocumento6 pagineUn Problema Di Logistica DocenteGiova62 GdsNessuna valutazione finora
- Applicazioni Del Modello Logistico in Ambito BiomedicaleDocumento287 pagineApplicazioni Del Modello Logistico in Ambito Biomedicalesilvano andornoNessuna valutazione finora
- Appunti Econometria 1 PDFDocumento10 pagineAppunti Econometria 1 PDFRoccotanosiffNessuna valutazione finora
- 160704Documento5 pagine160704CarmineD'AnielloNessuna valutazione finora
- Inferenza Statistica EserciziDocumento6 pagineInferenza Statistica EserciziQuantum05Nessuna valutazione finora
- P Sciortino PDFDocumento64 pagineP Sciortino PDFlinus18Nessuna valutazione finora
- Esercizi Statistica e Calcolo Delle ProbabilitaDocumento103 pagineEsercizi Statistica e Calcolo Delle ProbabilitaperosuttoneNessuna valutazione finora
- ESTADISTICADocumento5 pagineESTADISTICAAbner Cilis Rebaza GuzmanNessuna valutazione finora
- TracciaIA 22febbraio2022Documento3 pagineTracciaIA 22febbraio2022Anto LuppolodoNessuna valutazione finora
- Esempio Esame2Documento2 pagineEsempio Esame2Luca BaldanziNessuna valutazione finora
- Esame2 SoluzioniDocumento3 pagineEsame2 SoluzioniLuca BaldanziNessuna valutazione finora
- 37742-Appunti MatlabDocumento19 pagine37742-Appunti MatlabClaudio RoccaNessuna valutazione finora
- Esempi Domande Di Analisi UnoDocumento4 pagineEsempi Domande Di Analisi UnoLorenzo MazzellaNessuna valutazione finora
- Es 1Documento2 pagineEs 1Luca BaldanziNessuna valutazione finora
- i β +β x β x i i 2 β i2 ε i i β x +β log (x) x i i 2 2 2 iDocumento2 paginei β +β x β x i i 2 β i2 ε i i β x +β log (x) x i i 2 2 2 iMatteo AnzanoNessuna valutazione finora
- 2023 01 27 TA SolDocumento3 pagine2023 01 27 TA SolCamilo Betancourth BolivarNessuna valutazione finora
- Integrali Curvilinei e SuperficieDocumento23 pagineIntegrali Curvilinei e Superficienitrosc16703Nessuna valutazione finora
- Primo Esonero 2009-2015Documento14 paginePrimo Esonero 2009-2015Francesco LavecchiaNessuna valutazione finora
- Eserciziario FDADocumento153 pagineEserciziario FDAAmedeo Franco BonattiNessuna valutazione finora
- Anova AppuntiDocumento58 pagineAnova Appuntitrido1Nessuna valutazione finora
- Calcolo Numerico 2011Documento69 pagineCalcolo Numerico 2011Ester BeltramiNessuna valutazione finora
- Comandi Per Verifica Di Ipotesi Con R v5 PDFDocumento13 pagineComandi Per Verifica Di Ipotesi Con R v5 PDF!ofiuco2000Nessuna valutazione finora
- Sistemi Dinamici - MATLABDocumento1 paginaSistemi Dinamici - MATLABCristian HaivazNessuna valutazione finora
- Interpolazione, - Regressione, - CorrelazioneDocumento46 pagineInterpolazione, - Regressione, - CorrelazioneRahul LakhanpalNessuna valutazione finora
- Esercizi Di Riepilogo GEOMETRIADocumento19 pagineEsercizi Di Riepilogo GEOMETRIAGiulia ManciniNessuna valutazione finora
- T - CN Approssimazione II PDFDocumento61 pagineT - CN Approssimazione II PDFAngelica GiordanoNessuna valutazione finora
- 12-Esercizi TestIpotesi SoluzioniDocumento4 pagine12-Esercizi TestIpotesi SoluzioniAlessandro LuchettiNessuna valutazione finora
- Appunti Analisi 1Documento162 pagineAppunti Analisi 1Federico PinzautiNessuna valutazione finora
- Chissa Chi Lo SaDocumento105 pagineChissa Chi Lo Sa1992ceroNessuna valutazione finora
- 02 Fondamenti Di Analisi StatisticaDocumento34 pagine02 Fondamenti Di Analisi Statisticaemanueledesantis201Nessuna valutazione finora
- Fisica MedicaDocumento222 pagineFisica Medicaeliatan86Nessuna valutazione finora
- EserciziDocumento4 pagineEserciziRiccardo Della SalaNessuna valutazione finora
- Esercizi Teorici Su Algoritmi VariDocumento3 pagineEsercizi Teorici Su Algoritmi Varipixi1992Nessuna valutazione finora
- Esparz2 2014Documento6 pagineEsparz2 2014Lorenzo BercelliNessuna valutazione finora
- Foglio 4 - ANDocumento2 pagineFoglio 4 - ANsbonanni2002Nessuna valutazione finora
- Esempio Di Prova Scritta - SoluzioniDocumento4 pagineEsempio Di Prova Scritta - Soluzioni7samu0giacoNessuna valutazione finora
- Stamp A Cchi Apart I X CorsoDocumento181 pagineStamp A Cchi Apart I X CorsoLuca ZingaNessuna valutazione finora
- Laboratorio1 2Documento21 pagineLaboratorio1 2davidNessuna valutazione finora
- Calcolo Differenziale 2022Documento24 pagineCalcolo Differenziale 2022Lele KingNessuna valutazione finora
- Esercizi svolti di Matematica: Geometria AnaliticaDa EverandEsercizi svolti di Matematica: Geometria AnaliticaNessuna valutazione finora
- Progressione logica di dodici coppie di tavole binarie (con elementi fisico-matematici correlati a concetti chiave filosoficoscientifici e metafisici, comprovanti la fondamentale struttura dualisticamente quadridimensionale dell'universo)Da EverandProgressione logica di dodici coppie di tavole binarie (con elementi fisico-matematici correlati a concetti chiave filosoficoscientifici e metafisici, comprovanti la fondamentale struttura dualisticamente quadridimensionale dell'universo)Nessuna valutazione finora
- Esercizi di matematica: equazioni e disequazioni algebricheDa EverandEsercizi di matematica: equazioni e disequazioni algebricheNessuna valutazione finora
- Dispensa Vereni ModuloADocumento17 pagineDispensa Vereni ModuloAapi-3735634Nessuna valutazione finora
- Archivo Extraido y Enviado Por Mauro Risani (Mauro@urra - It) : Apellido Nombre Parentela Edad Sexo Estado CivilDocumento915 pagineArchivo Extraido y Enviado Por Mauro Risani (Mauro@urra - It) : Apellido Nombre Parentela Edad Sexo Estado CivilLourdes AysNessuna valutazione finora
- Anna Dai Capelli Rossi - Cerca Con GoogleDocumento2 pagineAnna Dai Capelli Rossi - Cerca Con GoogleANessuna valutazione finora
- An Easter Hallelujah2Documento1 paginaAn Easter Hallelujah2squatreyeuxNessuna valutazione finora
- Albert EinsteinDocumento17 pagineAlbert EinsteinJason FrancisNessuna valutazione finora
- Lucifero e Nuove MitologieDocumento15 pagineLucifero e Nuove MitologieGaia-NOM100% (1)
- 03 NP3 OnlineDocumento13 pagine03 NP3 OnlineCarmen MannaNessuna valutazione finora
- Digerente KHDocumento65 pagineDigerente KHHibino TsubakiNessuna valutazione finora
- Paniere Chiuse Didattica Della Lingua Madre Seconda e StranieraDocumento59 paginePaniere Chiuse Didattica Della Lingua Madre Seconda e Stranieraerika piervisaniNessuna valutazione finora
- Brusa-Zappellini - La Mente e Forme - Indice e Cap.IDocumento31 pagineBrusa-Zappellini - La Mente e Forme - Indice e Cap.ILuciano DuòNessuna valutazione finora