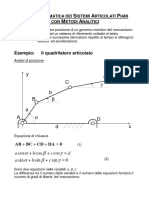
Potrebbero piacerti anche
- ITPS3Documento4 pagineITPS3Alan GuerziNessuna valutazione finora
- Appunti Analisi 1Documento263 pagineAppunti Analisi 1Dimitry GrishinNessuna valutazione finora
- Esercizi Di Analisi NumericaDocumento2 pagineEsercizi Di Analisi Numericapixi1992Nessuna valutazione finora
- Deagostini 9788853805270 PreviewDocumento31 pagineDeagostini 9788853805270 PreviewAntonella AngiulliNessuna valutazione finora
- Prova Scritta Di Geometria Corso Di Laurea in Ingegneria Informatica 25 Maggio 2018Documento3 pagineProva Scritta Di Geometria Corso Di Laurea in Ingegneria Informatica 25 Maggio 2018EdoardoNessuna valutazione finora
- 04 Insiemi e Logica - Esercizi Prova BDocumento3 pagine04 Insiemi e Logica - Esercizi Prova BornellaNessuna valutazione finora
- Analisi ADocumento115 pagineAnalisi Akirscar9299Nessuna valutazione finora
- Dispensa PDFDocumento18 pagineDispensa PDFDestinyNessuna valutazione finora
- Settimana 1Documento7 pagineSettimana 1enzoandreolli501Nessuna valutazione finora
- Integrale IndefinitoDocumento12 pagineIntegrale IndefinitoLaura PecoraroNessuna valutazione finora
- LogaritmiDocumento19 pagineLogaritmiIlclandei Marsigliesi ValerianiNessuna valutazione finora
- Appunti Analisi 1Documento162 pagineAppunti Analisi 1Federico PinzautiNessuna valutazione finora
- Soluzioni Esercizi LayoutDocumento8 pagineSoluzioni Esercizi LayoutDario Daddà TurresNessuna valutazione finora
- Senior 19Documento18 pagineSenior 19gretelpoppinsNessuna valutazione finora
- TracciaIA 22febbraio2022Documento3 pagineTracciaIA 22febbraio2022Anto LuppolodoNessuna valutazione finora
- Appunti Prof CococcioniDocumento250 pagineAppunti Prof CococcioniNaomi EspositoNessuna valutazione finora
- Appunti - Di - Geometria Paola Biondi - PIA Maria Lo ReDocumento208 pagineAppunti - Di - Geometria Paola Biondi - PIA Maria Lo ReMarina ZuddasNessuna valutazione finora
- Esercizi Analisi 1Documento3 pagineEsercizi Analisi 1Marco TrentiNessuna valutazione finora
- hw2021 03Documento1 paginahw2021 03Stefano PeaNessuna valutazione finora
- AppuntI ANALISI UnoDocumento255 pagineAppuntI ANALISI UnoStefano MiccoNessuna valutazione finora
- Chissa Chi Lo SaDocumento105 pagineChissa Chi Lo Sa1992ceroNessuna valutazione finora
- Lezioni Finesso Segnali e Sistemi UnipdDocumento122 pagineLezioni Finesso Segnali e Sistemi UnipdSh1ku100% (3)
- Libro Degli EserciziDocumento101 pagineLibro Degli EserciziMaurizio La VillettaNessuna valutazione finora
- Testies A Me 2018Documento66 pagineTesties A Me 2018DIDIER FEDERICO PERNICINessuna valutazione finora
- Esercizi EXERCISE Svolti MATLABDocumento39 pagineEsercizi EXERCISE Svolti MATLABMassimo PerfettiNessuna valutazione finora
- Metodi Quantitativi Per Le Decisioni Aziendali PDFDocumento73 pagineMetodi Quantitativi Per Le Decisioni Aziendali PDFMassimiliano MundulaNessuna valutazione finora
- Test Selezione Scienze 2013 A BQDocumento51 pagineTest Selezione Scienze 2013 A BQMatteo CirelliNessuna valutazione finora
- Compito Programmazione in CDocumento4 pagineCompito Programmazione in CAlessandro VinciNessuna valutazione finora
- Statistica Matematica (Franceschini)Documento131 pagineStatistica Matematica (Franceschini)TommasoMarin100% (1)
- Scap 2Documento32 pagineScap 2danNessuna valutazione finora
- Analisi Complessa-Cesari PDFDocumento149 pagineAnalisi Complessa-Cesari PDFIvan TomaNessuna valutazione finora
- 09 2 EseCDocumento70 pagine09 2 EseCAlessandro Siro CampiNessuna valutazione finora
- 7ano Matematica Numeros Inteiros Parte IDocumento4 pagine7ano Matematica Numeros Inteiros Parte IMaria Aparecida Santos NorbertoNessuna valutazione finora
- Calconi-Classi Resto 1Documento18 pagineCalconi-Classi Resto 1Gregorio Lazarenko AraudoNessuna valutazione finora
- 24-02-05 Parte A - SoluzioniDocumento3 pagine24-02-05 Parte A - SoluzioniAgriIT •Nessuna valutazione finora
- Prova Esame 13Documento2 pagineProva Esame 13Teresa Nunziata100% (1)
- Esercizi Spazi Vettoriali 1Documento4 pagineEsercizi Spazi Vettoriali 1aliceNessuna valutazione finora
- Calcolo Delle Probabilita'Documento47 pagineCalcolo Delle Probabilita'Andrea SichenzeNessuna valutazione finora
- Esamitesti SoluzioniDocumento318 pagineEsamitesti Soluzioniarianna_marsicoNessuna valutazione finora
- Formulario MatematicaDocumento31 pagineFormulario MatematicaluciacastelliNessuna valutazione finora
- Dispense Di Analisi 1 Del Prof. Fabio CamilliDocumento156 pagineDispense Di Analisi 1 Del Prof. Fabio CamilliGabrielMercuriNessuna valutazione finora
- Esame2 SoluzioniDocumento3 pagineEsame2 SoluzioniLuca BaldanziNessuna valutazione finora
- Test Selezione 090911 ADocumento49 pagineTest Selezione 090911 AIvan BripiNessuna valutazione finora
- Quiz Attitudinali e LogiciDocumento124 pagineQuiz Attitudinali e LogiciImmacolata GiustozziNessuna valutazione finora
- Esercizi SvoltiDocumento122 pagineEsercizi SvoltiVirus9090Nessuna valutazione finora
- Fattorizzazione RSA e Congettura Di GoldbachDocumento9 pagineFattorizzazione RSA e Congettura Di GoldbachRosario TurcoNessuna valutazione finora
- Serie Storiche - Per PCDocumento7 pagineSerie Storiche - Per PCdanielpupiNessuna valutazione finora
- Matlab - Piccolo MemorandumDocumento9 pagineMatlab - Piccolo MemorandumSedomNessuna valutazione finora
- 2018 Esercizi Extra Campi IntrocDocumento69 pagine2018 Esercizi Extra Campi IntrocAdelaide VersinoNessuna valutazione finora
- Esercizi Di Meccanica Razionale A - V. FranceschiniDocumento93 pagineEsercizi Di Meccanica Razionale A - V. FranceschiniL2VJVR100% (1)
- La seconda prova di matematica e fisica: svolgimento commentato delle prove ufficiali 2019Da EverandLa seconda prova di matematica e fisica: svolgimento commentato delle prove ufficiali 2019Nessuna valutazione finora
- Progressione logica di dodici coppie di tavole binarie (con elementi fisico-matematici correlati a concetti chiave filosoficoscientifici e metafisici, comprovanti la fondamentale struttura dualisticamente quadridimensionale dell'universo)Da EverandProgressione logica di dodici coppie di tavole binarie (con elementi fisico-matematici correlati a concetti chiave filosoficoscientifici e metafisici, comprovanti la fondamentale struttura dualisticamente quadridimensionale dell'universo)Nessuna valutazione finora
- I quiz RIPAM: guida alla risoluzione. 320 test risolti e commentatiDa EverandI quiz RIPAM: guida alla risoluzione. 320 test risolti e commentatiNessuna valutazione finora
- Concorso INPS: guida alla prova oggettiva attitudinale: 320 test risolti e commentati di carattere psicoattitudinale, logica, competenze linguisticheDa EverandConcorso INPS: guida alla prova oggettiva attitudinale: 320 test risolti e commentati di carattere psicoattitudinale, logica, competenze linguisticheValutazione: 3 su 5 stelle3/5 (1)
- Agenzia Entrate: guida alla prova oggettiva attitudinale per Funzionari Amministrativo-Tributari. 320 test risolti e commentatiDa EverandAgenzia Entrate: guida alla prova oggettiva attitudinale per Funzionari Amministrativo-Tributari. 320 test risolti e commentatiNessuna valutazione finora
- JUNO-DS 88 76 61 Ita01 WDocumento22 pagineJUNO-DS 88 76 61 Ita01 WMarco BottinoNessuna valutazione finora
- Il VoucherDocumento17 pagineIl VoucherDxneNessuna valutazione finora
- Appunti Di Meccanizzazione Forestale PDFDocumento90 pagineAppunti Di Meccanizzazione Forestale PDFMarlin ZamoraNessuna valutazione finora
- Storia Delle Forme e Dei Repertori MusicaliDocumento14 pagineStoria Delle Forme e Dei Repertori MusicaliAntonella VizzonNessuna valutazione finora
- Ez36 1000395294Documento519 pagineEz36 1000395294Flávio da silva carvalhoNessuna valutazione finora
- P10095g071001a SCH 10084726 Et000448 Es-ItDocumento15 pagineP10095g071001a SCH 10084726 Et000448 Es-ItPablo AntezanaNessuna valutazione finora
- Riassunto-Appunti MindTheGapDocumento20 pagineRiassunto-Appunti MindTheGapDaluvasNessuna valutazione finora