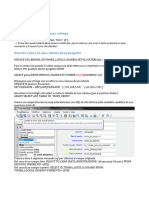
Potrebbero piacerti anche
- Corso SQLDocumento107 pagineCorso SQLgenovoffaNessuna valutazione finora
- Sintassi SQLDocumento2 pagineSintassi SQLGabryNessuna valutazione finora
- SQL per principianti: imparate l'uso dei database Microsoft SQL Server, MySQL, PostgreSQL e OracleDa EverandSQL per principianti: imparate l'uso dei database Microsoft SQL Server, MySQL, PostgreSQL e OracleNessuna valutazione finora
- Esempi Vba AccessDocumento17 pagineEsempi Vba AccessAnonymous hUjnXzZNessuna valutazione finora
- SQL Linguaggio SQLDocumento5 pagineSQL Linguaggio SQLMattia BoffaNessuna valutazione finora
- Postgres Basico Parte 1Documento5 paginePostgres Basico Parte 1Sidhar LozadaNessuna valutazione finora
- SAI - Gestione e Analisi Di Dati: IntroduzioneDocumento20 pagineSAI - Gestione e Analisi Di Dati: Introduzioneyasmine menadNessuna valutazione finora
- SQL Comandi PrincipaliDocumento4 pagineSQL Comandi PrincipalivanzegtNessuna valutazione finora
- Il Linguaggio SQL Standard: Capitolo QuartoDocumento55 pagineIl Linguaggio SQL Standard: Capitolo QuartoEXE M4HD1Nessuna valutazione finora
- Esempi Implementabili in Mysql AltervistaDocumento4 pagineEsempi Implementabili in Mysql AltervistaLUCA PICCIOTTONessuna valutazione finora
- Excel FrosiniDocumento49 pagineExcel FrosiniEdoardo CutiniNessuna valutazione finora
- Appunti LezioneDocumento22 pagineAppunti LezionemargheritafusiiNessuna valutazione finora
- R ComandiDocumento3 pagineR ComandiDavide LanziNessuna valutazione finora
- Sintesi SQLDocumento3 pagineSintesi SQLM/TNessuna valutazione finora
- SQLbasiDocumento47 pagineSQLbasialessio collettaNessuna valutazione finora
- Teste Analista BIDocumento8 pagineTeste Analista BIFábio PietroNessuna valutazione finora
- 4-SQL Structured Query LanguageDocumento91 pagine4-SQL Structured Query LanguageKalil DialloNessuna valutazione finora
- Sintassi Query Language - OdtDocumento3 pagineSintassi Query Language - OdtesmomixNessuna valutazione finora
- Gestione e Analisi Dei DatiDocumento6 pagineGestione e Analisi Dei Datiandy soldatoNessuna valutazione finora
- SQL Per La Def - 211031 - 124109Documento8 pagineSQL Per La Def - 211031 - 124109Antonella IeloNessuna valutazione finora
- Dispensa Access Avanzato Ecdl 5Documento14 pagineDispensa Access Avanzato Ecdl 5Kheper MessoriNessuna valutazione finora
- AccessDocumento36 pagineAccesscagliostro1979Nessuna valutazione finora
- (Ebook - Ita - Manuali) Microsoft Access - Query Avanzato PDFDocumento8 pagine(Ebook - Ita - Manuali) Microsoft Access - Query Avanzato PDFPersiusalNessuna valutazione finora
- SQL 1 BasiDocumento21 pagineSQL 1 BasislontchaNessuna valutazione finora
- InformaticaDocumento6 pagineInformaticafrancesca bonifacioNessuna valutazione finora
- DB Lez 2Documento1 paginaDB Lez 2David BrignaniNessuna valutazione finora
- Appunti Pistolesi - A.a.2021-2022Documento16 pagineAppunti Pistolesi - A.a.2021-2022GiacomoNessuna valutazione finora
- Rimpiazzare Un Testo in Una Colonna: LowerDocumento6 pagineRimpiazzare Un Testo in Una Colonna: Lowermaurizio.maselliNessuna valutazione finora
- Manuale Utente Autocad 2006 Italiano Riferimento RapidoDocumento6 pagineManuale Utente Autocad 2006 Italiano Riferimento RapidoSalvatore PicciottoNessuna valutazione finora
- (Ebook - ITA) Corso Di Access PDFDocumento91 pagine(Ebook - ITA) Corso Di Access PDFTheGrill FirenzeNessuna valutazione finora
- Manuale SQLDocumento114 pagineManuale SQLEICONSULTINGNessuna valutazione finora
- Guida Esercitazione Excel AvanzatoDocumento7 pagineGuida Esercitazione Excel AvanzatomanuelNessuna valutazione finora
- PLSQLDocumento32 paginePLSQLAlberto GrassiNessuna valutazione finora
- (Ebook - ITA) Corso Di AccessDocumento91 pagine(Ebook - ITA) Corso Di AccessAnibal TamburrinoNessuna valutazione finora
- Esercizi SQLDocumento35 pagineEsercizi SQLVictor PlumNessuna valutazione finora
- SQL Da DireDocumento2 pagineSQL Da DireAlberto PalumboNessuna valutazione finora
- PL Modelli e GAMSDocumento119 paginePL Modelli e GAMSValravn 999Nessuna valutazione finora
- Slide Oracle PL SQLDocumento87 pagineSlide Oracle PL SQLLuca PelorossoNessuna valutazione finora
- Dati Struttura in PythonDocumento30 pagineDati Struttura in PythonFrancescoNessuna valutazione finora
- Corso ABAP SE38-1Documento46 pagineCorso ABAP SE38-1Jose Madan Brayan EmilioNessuna valutazione finora
- Manuale - Ita - Abap - Query - Sap r3 4 6 BDocumento21 pagineManuale - Ita - Abap - Query - Sap r3 4 6 BXaxo PapoNessuna valutazione finora
- Connessione ODBCDocumento22 pagineConnessione ODBCmaurizio.maselliNessuna valutazione finora
- Strutture Dinamiche Java Con GenericsDocumento18 pagineStrutture Dinamiche Java Con GenericsValerio TufarielloNessuna valutazione finora
- Sintassi MySqlDocumento19 pagineSintassi MySqlJatinger SinghNessuna valutazione finora
- Funzioni InformaticaDocumento2 pagineFunzioni InformaticaGiuseppe ReinaNessuna valutazione finora
- Appunti Di CDocumento11 pagineAppunti Di Cesmomix100% (1)
- Elenco Variabili (Con Formato) Come Inserire I DatiDocumento5 pagineElenco Variabili (Con Formato) Come Inserire I DatiAndrea SichenzeNessuna valutazione finora
- Domande Scritto BDDocumento7 pagineDomande Scritto BDCiao GostNessuna valutazione finora
- 12 PersistenzajdbcDocumento104 pagine12 PersistenzajdbcGerry CalàNessuna valutazione finora
- Appunti C#Documento14 pagineAppunti C#AssiNessuna valutazione finora
- QueryDocumento2 pagineQueryGANGAN VICTORNessuna valutazione finora
- Teste ReviDocumento3 pagineTeste ReviggoncalvesabatiNessuna valutazione finora
- About Data Sections - HelpDocumento4 pagineAbout Data Sections - HelpcloudcrownmusicNessuna valutazione finora
- About Arrays - HelpDocumento5 pagineAbout Arrays - HelpcloudcrownmusicNessuna valutazione finora
- Fogli Di Calcolo 3Documento3 pagineFogli Di Calcolo 3gy99667knzNessuna valutazione finora
- Corso Di Matlab Simulink Per Ingegneria2Documento31 pagineCorso Di Matlab Simulink Per Ingegneria2lpestanaNessuna valutazione finora
- Eq Goniometriche Elementari ParticolariDocumento2 pagineEq Goniometriche Elementari ParticolariErik AllenatoreNessuna valutazione finora
- RelazioneDocumento5 pagineRelazioneErik AllenatoreNessuna valutazione finora
- Istologia - Parte 1 RevisionareDocumento7 pagineIstologia - Parte 1 RevisionareErik AllenatoreNessuna valutazione finora
- Storia 1Documento6 pagineStoria 1Erik AllenatoreNessuna valutazione finora
- 4.4 Vincoli Di IntegritàDocumento3 pagine4.4 Vincoli Di IntegritàErik AllenatoreNessuna valutazione finora
- 4.3 FormeNormaliDocumento3 pagine4.3 FormeNormaliErik AllenatoreNessuna valutazione finora
- 4.1 Introduzione Alle Basi Di DatiDocumento48 pagine4.1 Introduzione Alle Basi Di DatiErik AllenatoreNessuna valutazione finora
- 4.2 Regole Di DerivazioneDocumento5 pagine4.2 Regole Di DerivazioneErik AllenatoreNessuna valutazione finora
- Reti Logiche Seconda EdizioneDocumento1 paginaReti Logiche Seconda EdizioneQWENessuna valutazione finora
- Chimica in VersiDocumento194 pagineChimica in Versi11113432100% (1)
- Lez 4 - Malattie FungineDocumento39 pagineLez 4 - Malattie FungineabyutzaNessuna valutazione finora
- Mer 05Documento2 pagineMer 05tripponreNessuna valutazione finora
- 01 Tode Personaggi Storia Luoghi e Tecnica Estratto Tutto Kyan PDFDocumento22 pagine01 Tode Personaggi Storia Luoghi e Tecnica Estratto Tutto Kyan PDFMaurizio Di StefanoNessuna valutazione finora
- Metaverso: La guida visionaria per principianti per scoprire ed investire nelle Terre Virtuali, nei giochi nella blockchain, nell’arte digitale degli NFT e nelle affascinanti tecnologie del VRDa EverandMetaverso: La guida visionaria per principianti per scoprire ed investire nelle Terre Virtuali, nei giochi nella blockchain, nell’arte digitale degli NFT e nelle affascinanti tecnologie del VRValutazione: 5 su 5 stelle5/5 (8)
- Dal Cad al Web: Il Codice dell’Amministrazione Digitale per TuttiDa EverandDal Cad al Web: Il Codice dell’Amministrazione Digitale per TuttiNessuna valutazione finora
- Expert secrets: Come i migliori esperti e consulenti possono crescere onlineDa EverandExpert secrets: Come i migliori esperti e consulenti possono crescere onlineNessuna valutazione finora
- Nuovo Esame per Esperto in Gestione dell'Energia - Settore Civile: Test e temi di esame svolti per sostenere l’esame di Esperto in Gestione dell’Energia del Settore CivileDa EverandNuovo Esame per Esperto in Gestione dell'Energia - Settore Civile: Test e temi di esame svolti per sostenere l’esame di Esperto in Gestione dell’Energia del Settore CivileNessuna valutazione finora
- Autodesk Inventor | Passo dopo Passo: Progettazione CAD e Simulazione FEM con Autodesk Inventor per PrincipiantiDa EverandAutodesk Inventor | Passo dopo Passo: Progettazione CAD e Simulazione FEM con Autodesk Inventor per PrincipiantiNessuna valutazione finora
- Altro Evo, l'Album delle illustrazioni: Digital painting, sword and sorcery fantasy art bookDa EverandAltro Evo, l'Album delle illustrazioni: Digital painting, sword and sorcery fantasy art bookNessuna valutazione finora
- Elettrotecnica Generale: Circuiti Elettrici in Regime StazionarioDa EverandElettrotecnica Generale: Circuiti Elettrici in Regime StazionarioNessuna valutazione finora
- Manuale d'uso per Networker: 7 Segreti per Sponsorizzare con SuccessoDa EverandManuale d'uso per Networker: 7 Segreti per Sponsorizzare con SuccessoNessuna valutazione finora
- Nuovo Esame per Esperto in Gestione dell'Energia Settore Industriale: Test e temi di esame svolti per sostenere l’esame di Esperto in Gestione dell’Energia del Settore IndustrialeDa EverandNuovo Esame per Esperto in Gestione dell'Energia Settore Industriale: Test e temi di esame svolti per sostenere l’esame di Esperto in Gestione dell’Energia del Settore IndustrialeNessuna valutazione finora
- Dotcom secrets: Il bestseller mondiale per fare business onlineDa EverandDotcom secrets: Il bestseller mondiale per fare business onlineNessuna valutazione finora
- Né vero né falso. Nella Rete il dubbio è inevitabile - Web nostrum 2Da EverandNé vero né falso. Nella Rete il dubbio è inevitabile - Web nostrum 2Nessuna valutazione finora
- Javascript: Un Manuale Per Imparare La Programmazione In JavascriptDa EverandJavascript: Un Manuale Per Imparare La Programmazione In JavascriptNessuna valutazione finora
- FreeCAD | passo dopo passo: Impara a creare oggetti in 3D, assemblaggi e disegni tecnici con FreeCADDa EverandFreeCAD | passo dopo passo: Impara a creare oggetti in 3D, assemblaggi e disegni tecnici con FreeCADNessuna valutazione finora
- SQL per principianti: imparate l'uso dei database Microsoft SQL Server, MySQL, PostgreSQL e OracleDa EverandSQL per principianti: imparate l'uso dei database Microsoft SQL Server, MySQL, PostgreSQL e OracleNessuna valutazione finora
- Il montaggio efficace: Guida all’uso di ShotcutDa EverandIl montaggio efficace: Guida all’uso di ShotcutNessuna valutazione finora
- L'era dell'Intelligenza Artificiale: Come l'AI sta rivoluzionando le nostre viteDa EverandL'era dell'Intelligenza Artificiale: Come l'AI sta rivoluzionando le nostre viteNessuna valutazione finora
- Vincere sui social: Come i grandi imprenditori costruiscono il loro business e la loro influenza e come puoi farlo anche tu!Da EverandVincere sui social: Come i grandi imprenditori costruiscono il loro business e la loro influenza e come puoi farlo anche tu!Nessuna valutazione finora