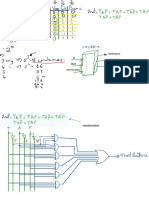
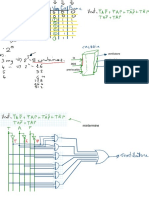
Potrebbero piacerti anche
- Le frazioni con Scratch: fare coding mentre si apprendono le frazioni ... e viceversaDa EverandLe frazioni con Scratch: fare coding mentre si apprendono le frazioni ... e viceversaNessuna valutazione finora
- Fisica: cinematica 2 con Scratch: Esperimenti con Scratch su moti vari e moti composti con il calcolo numericoDa EverandFisica: cinematica 2 con Scratch: Esperimenti con Scratch su moti vari e moti composti con il calcolo numericoNessuna valutazione finora
- Addestramento Rete NeuraleDocumento9 pagineAddestramento Rete NeuraleEmanueleNessuna valutazione finora
- Codigop 3Documento9 pagineCodigop 3Francisco Lavín FonsecaNessuna valutazione finora
- Esercizi EsameDocumento4 pagineEsercizi EsameMattiaNessuna valutazione finora
- UntitledDocumento40 pagineUntitledapi-251901021Nessuna valutazione finora
- 3442 (1) .OdtDocumento4 pagine3442 (1) .OdtArtiom KubantsevNessuna valutazione finora
- Simulazione Esame AI - Parte 1 (Reti Di Petri)Documento4 pagineSimulazione Esame AI - Parte 1 (Reti Di Petri)Ibrahim El ShemyNessuna valutazione finora
- Tutorial Matlab by IcpDocumento59 pagineTutorial Matlab by Icpilcristopagano666Nessuna valutazione finora
- Corso Di Visual Basic - 9Documento6 pagineCorso Di Visual Basic - 9saverioNessuna valutazione finora
- Appunti Di AlgoritmiDocumento39 pagineAppunti Di AlgoritmiEmanuel RamaciNessuna valutazione finora
- Guida Matlab PDFDocumento50 pagineGuida Matlab PDFpinoNessuna valutazione finora
- 1964 Public Class Esame21gennaioDocumento3 pagine1964 Public Class Esame21gennaioMattiaNessuna valutazione finora
- Dispensa MatlabDocumento24 pagineDispensa MatlabFerdinandoooNessuna valutazione finora
- Calcolo Manuale Del Logaritmo PDFDocumento22 pagineCalcolo Manuale Del Logaritmo PDFbaronto100% (1)
- Risposte DaneseDocumento36 pagineRisposte DanesemarcoNessuna valutazione finora
- Reti Neurali ArtificialiDocumento13 pagineReti Neurali Artificialicomix88100% (1)
- Esercizi Di Sistemi Operativi 1Documento6 pagineEsercizi Di Sistemi Operativi 1paolo the best(ia)Nessuna valutazione finora
- Matlab ANumDocumento18 pagineMatlab ANumAndrea TundoNessuna valutazione finora
- EserciziPerEsame 2009-10Documento25 pagineEserciziPerEsame 2009-10Gianluca MastelloNessuna valutazione finora
- Sistemi Operativi 5Documento4 pagineSistemi Operativi 5paolo the best(ia)Nessuna valutazione finora
- Classificazione Con Percettrone MultistratoDocumento8 pagineClassificazione Con Percettrone MultistratofedifediNessuna valutazione finora
- Comandi MatlabDocumento3 pagineComandi MatlabRaffaele IavazzoNessuna valutazione finora
- Soluzioni Degli Esercizi Del Manuale Di Giunta e CiaramellaDocumento26 pagineSoluzioni Degli Esercizi Del Manuale Di Giunta e CiaramellaUmberto PiscopoNessuna valutazione finora
- Algoritmi e Strutture DatiDocumento36 pagineAlgoritmi e Strutture DatiGiovanniNessuna valutazione finora
- Comando SDocumento15 pagineComando SElio AguilarNessuna valutazione finora
- Language ITADocumento3 pagineLanguage ITAN TNessuna valutazione finora
- Introduzione A MatlabDocumento32 pagineIntroduzione A Matlabgiordanobi859641Nessuna valutazione finora
- La Trasformata DCT Applicata Alle ImmaginiDocumento16 pagineLa Trasformata DCT Applicata Alle ImmaginifedifediNessuna valutazione finora
- Analisi Degli Algoritmi22Documento128 pagineAnalisi Degli Algoritmi22dforce1000Nessuna valutazione finora
- Esercizi Python 0Documento48 pagineEsercizi Python 0adrianoNessuna valutazione finora
- ASD-Find Maximum SubArray & Topological SortDocumento36 pagineASD-Find Maximum SubArray & Topological SortAlejandroDeeJay100% (1)
- Introduzione Ai ThreadDocumento6 pagineIntroduzione Ai ThreadCinzia BocchiNessuna valutazione finora
- Studio Del Moto Caotico Del Doppio PendoloDocumento6 pagineStudio Del Moto Caotico Del Doppio PendoloMatteo PompiliNessuna valutazione finora
- Calcolo Parallelo - Riassunto Sbobbinato Slide.Documento25 pagineCalcolo Parallelo - Riassunto Sbobbinato Slide.Angelo Borrelli0% (1)
- DocumentoDocumento2 pagineDocumentoSaraNessuna valutazione finora
- Libro Degli EserciziDocumento101 pagineLibro Degli EserciziMaurizio La VillettaNessuna valutazione finora
- Introduzione A Tensorflow Regressione Logistica, LeNet Convolutional NeuralNetworkDocumento17 pagineIntroduzione A Tensorflow Regressione Logistica, LeNet Convolutional NeuralNetworkFurio RuggieroNessuna valutazione finora
- Multistart K-MeansDocumento11 pagineMultistart K-MeansGourav BajeliNessuna valutazione finora
- Analisi ComputazionaleDocumento9 pagineAnalisi ComputazionaleRosario TurcoNessuna valutazione finora
- Fondamenti Di InformaticaDocumento15 pagineFondamenti Di InformaticaaaaaaaNessuna valutazione finora
- System Identification ToolboxDocumento36 pagineSystem Identification ToolboxfdadfNessuna valutazione finora
- Esercitazione 3Documento6 pagineEsercitazione 3remo rossiNessuna valutazione finora
- (ASE) FormularioDocumento9 pagine(ASE) FormularioDamian DutkaNessuna valutazione finora
- Laboratorio 12 - RicorsioneDocumento11 pagineLaboratorio 12 - RicorsioneTomas TomasNessuna valutazione finora
- Il Layout Degli ImpiantiDocumento15 pagineIl Layout Degli ImpiantiPieroNacciNessuna valutazione finora
- Modelli Dinamici Con MatlabDocumento13 pagineModelli Dinamici Con MatlabSimone OnoratiNessuna valutazione finora
- Primo CompitinoDocumento4 paginePrimo CompitinoFrancesco MorandiniNessuna valutazione finora
- Ejercicios LabviewDocumento24 pagineEjercicios LabviewAnonymous TlGnQZv5d7Nessuna valutazione finora
- Manuale MoshellDocumento4 pagineManuale MoshellLuigi RambaldiNessuna valutazione finora
- Thread JavaDocumento6 pagineThread JavaAurora VanneschiNessuna valutazione finora
- Complessita Computazionale Di Un Algoritmo - CavalieriDocumento25 pagineComplessita Computazionale Di Un Algoritmo - CavalieriAntonella SilverNessuna valutazione finora
- Cicli Matlab EserciziDocumento27 pagineCicli Matlab Esercizibananasplit87Nessuna valutazione finora
- Appunti Reti NeuraliDocumento39 pagineAppunti Reti NeuraliVincenzo Maria SchimmentiNessuna valutazione finora
- Seconda Esercitazione Di NardoDocumento16 pagineSeconda Esercitazione Di Nardoleonardo adamNessuna valutazione finora
- Ex7 LSDocumento2 pagineEx7 LSFrancesca ParercutNessuna valutazione finora
- Elementi Di Architettura e Sistemi Operativi: Bioinformatica - Tiziano VillaDocumento18 pagineElementi Di Architettura e Sistemi Operativi: Bioinformatica - Tiziano Villaapi-253266324Nessuna valutazione finora
- Fisica: dinamica 1 con Scratch: Esperimenti di fisica con Scratch sui moti con attrito con il calcolo numericoDa EverandFisica: dinamica 1 con Scratch: Esperimenti di fisica con Scratch sui moti con attrito con il calcolo numericoNessuna valutazione finora
- Verifica e confronto delle soluzioni di un telaio: Metodo degli spostamenti e analisi matriciale con codice SAPDa EverandVerifica e confronto delle soluzioni di un telaio: Metodo degli spostamenti e analisi matriciale con codice SAPNessuna valutazione finora
- Sistemi TerzaDocumento113 pagineSistemi TerzamaprogNessuna valutazione finora
- Dispense Per Le Esercitazioni Del Corso Di Sistemi Elettronici Programmabili 1Documento163 pagineDispense Per Le Esercitazioni Del Corso Di Sistemi Elettronici Programmabili 1GennaroNessuna valutazione finora
- 2009 Scuolaestiva Amplificatori OperazionaliDocumento56 pagine2009 Scuolaestiva Amplificatori OperazionalimaprogNessuna valutazione finora
- Circuito Risonante RLC 2Documento19 pagineCircuito Risonante RLC 2maprogNessuna valutazione finora
- Esempio Generico Fab1Documento3 pagineEsempio Generico Fab1maprogNessuna valutazione finora
- CaldaiaDocumento3 pagineCaldaiamaprogNessuna valutazione finora
- Sistemi Intelligenti Videogiochi CNRDocumento35 pagineSistemi Intelligenti Videogiochi CNRmaprogNessuna valutazione finora
- Intro Matlab ElyDocumento50 pagineIntro Matlab ElyMaurizio La VillettaNessuna valutazione finora
- AlgebraDocumento5 pagineAlgebramaprogNessuna valutazione finora
- Duchenne - Linee Guida Integrazione ScolasticaDocumento32 pagineDuchenne - Linee Guida Integrazione ScolasticamaprogNessuna valutazione finora