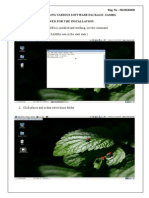
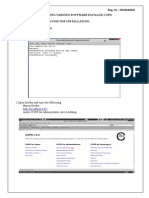
Potrebbero piacerti anche
- C++ Interview QuestionsDocumento11 pagineC++ Interview Questionsapi-3828930100% (2)
- Virtualization Environment Program For Open Source LabDocumento7 pagineVirtualization Environment Program For Open Source LabChandraSekar RaguramanNessuna valutazione finora
- C++ Questions: AnswerDocumento31 pagineC++ Questions: AnswerAB236Nessuna valutazione finora
- Os Lab FRNT Page With IndexDocumento3 pagineOs Lab FRNT Page With IndexChandraSekar RaguramanNessuna valutazione finora
- Compiling From Source Using Webattery Program For Open Source LabDocumento6 pagineCompiling From Source Using Webattery Program For Open Source LabChandraSekar RaguramanNessuna valutazione finora
- Kernel Configuration Program For Open Source LabDocumento11 pagineKernel Configuration Program For Open Source LabChandraSekar RaguramanNessuna valutazione finora
- Gui Program For Open Source LabDocumento4 pagineGui Program For Open Source LabChandraSekar RaguramanNessuna valutazione finora
- PHP Program For Open Source LabDocumento6 paginePHP Program For Open Source LabChandraSekar RaguramanNessuna valutazione finora
- Perl Program For Open Source LabDocumento6 paginePerl Program For Open Source LabChandraSekar RaguramanNessuna valutazione finora
- Network Interface Using Ifconfig Program For Open Source LabDocumento2 pagineNetwork Interface Using Ifconfig Program For Open Source LabChandraSekar RaguramanNessuna valutazione finora
- Python Program For Open Source LabDocumento11 paginePython Program For Open Source LabChandraSekar RaguramanNessuna valutazione finora
- OsrecordDocumento60 pagineOsrecordChandraSekar RaguramanNessuna valutazione finora
- SAMBA Program For Open Source LabDocumento3 pagineSAMBA Program For Open Source LabChandraSekar RaguramanNessuna valutazione finora
- CUPS Program For Open Source LabDocumento5 pagineCUPS Program For Open Source LabChandraSekar RaguramanNessuna valutazione finora
- System Software Lab ManualDocumento60 pagineSystem Software Lab ManualChandraSekar Raguraman100% (1)
- SylDocumento9 pagineSylChandraSekar RaguramanNessuna valutazione finora
- Cursor With OutputDocumento13 pagineCursor With OutputChandraSekar RaguramanNessuna valutazione finora
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (73)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (265)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (119)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)