Potrebbero piacerti anche
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5795)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Unconscious Bias - A Work BookDocumento13 pagineUnconscious Bias - A Work BookKaleem Ahmad100% (2)
- The Handbook of Forensic NeuropsychologyDocumento609 pagineThe Handbook of Forensic NeuropsychologyJohn F. Lepore100% (10)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Multiple Intelligences - Howard Gardner (Prof - BLH)Documento4 pagineMultiple Intelligences - Howard Gardner (Prof - BLH)Prof. (Dr.) B. L. HandooNessuna valutazione finora
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Neuropsychological AssessmentDocumento17 pagineNeuropsychological AssessmentSass100% (2)
- Final LeadershipDocumento112 pagineFinal LeadershipAbdullah Farrukh Goreja100% (2)
- The Psychology Behind Horror FilmsDocumento18 pagineThe Psychology Behind Horror Filmsapi-508013513Nessuna valutazione finora
- EDU Framework For Curriculum Severe and Profound Learning Needs PDFDocumento86 pagineEDU Framework For Curriculum Severe and Profound Learning Needs PDFalinadraghici100% (1)
- Beyond BiasDocumento10 pagineBeyond BiasJoão Ricardo MarquesNessuna valutazione finora
- Concepts of CompetenceDocumento36 pagineConcepts of CompetenceGustavo ASNessuna valutazione finora
- Behavioral TheoryDocumento28 pagineBehavioral TheoryAmarah Rivera PineraNessuna valutazione finora
- Age and AcquisitionDocumento56 pagineAge and AcquisitionKyle Marks100% (2)
- A Detailed Excursion On Machine Learning Approach, Algorithms and ApplicationsDocumento8 pagineA Detailed Excursion On Machine Learning Approach, Algorithms and Applicationsviju001Nessuna valutazione finora
- Journal Pone 0247330Documento14 pagineJournal Pone 0247330viju001Nessuna valutazione finora
- LubnaAlhenaki Project4Documento20 pagineLubnaAlhenaki Project4viju001Nessuna valutazione finora
- Semi-Supervised Learning A Brief ReviewDocumento6 pagineSemi-Supervised Learning A Brief ReviewReshma KhemchandaniNessuna valutazione finora
- Air Quality2Documento11 pagineAir Quality2viju001Nessuna valutazione finora
- Energy Efficiency Techniques in Cloud CoDocumento7 pagineEnergy Efficiency Techniques in Cloud Coviju001Nessuna valutazione finora
- Jurisoo Tarkvaratehnika 2017Documento45 pagineJurisoo Tarkvaratehnika 2017viju001Nessuna valutazione finora
- Deep Recurrent Level Set For Segmenting Brain TumorsDocumento8 pagineDeep Recurrent Level Set For Segmenting Brain Tumorsviju001Nessuna valutazione finora
- State Bank of India: To Whomsoever It May Concern Provisional Home Loan Interest CertificateDocumento1 paginaState Bank of India: To Whomsoever It May Concern Provisional Home Loan Interest Certificateviju001100% (1)
- Handling Missing Data Analysis of A Challenging Data Set Using Multiple ImputationDocumento20 pagineHandling Missing Data Analysis of A Challenging Data Set Using Multiple Imputationviju001Nessuna valutazione finora
- Literature Survey: 2.1 Fingerprint, Palmprint & Finger-Knuckle PrintDocumento24 pagineLiterature Survey: 2.1 Fingerprint, Palmprint & Finger-Knuckle Printviju001Nessuna valutazione finora
- Silviu Risco ThesisDocumento308 pagineSilviu Risco Thesisviju001Nessuna valutazione finora
- Data Mining Analysis of The Parkinsons DiseaseDocumento107 pagineData Mining Analysis of The Parkinsons Diseaseviju001Nessuna valutazione finora
- Fingerprint Segmentation Algorithms: A Literature Review: Rohan Nimkar Agya MishraDocumento5 pagineFingerprint Segmentation Algorithms: A Literature Review: Rohan Nimkar Agya Mishraviju001Nessuna valutazione finora
- Big Data Analytics in Supply Chain Management: A Systematic Literature Review and Research DirectionsDocumento29 pagineBig Data Analytics in Supply Chain Management: A Systematic Literature Review and Research Directionsviju001Nessuna valutazione finora
- Biometric Fingerprint Student Attendance System: Software Requirement SpecificationsDocumento19 pagineBiometric Fingerprint Student Attendance System: Software Requirement Specificationsviju001Nessuna valutazione finora
- Support Vector Machine Classification For Large Data Sets Via Minimum Enclosing Ball ClusteringDocumento9 pagineSupport Vector Machine Classification For Large Data Sets Via Minimum Enclosing Ball Clusteringviju001Nessuna valutazione finora
- Using Using Using Using Using Using Using Using Using Namespace Public Partial ClassDocumento14 pagineUsing Using Using Using Using Using Using Using Using Namespace Public Partial Classviju001Nessuna valutazione finora
- Iot Based Biometric Attendance System Using ArduinoDocumento108 pagineIot Based Biometric Attendance System Using Arduinoviju001Nessuna valutazione finora
- 10 - Chapter 1Documento22 pagine10 - Chapter 1viju001Nessuna valutazione finora
- A New Adaptive Cuckoo Search Algorithm:, Maheshwari Rashmita NathDocumento5 pagineA New Adaptive Cuckoo Search Algorithm:, Maheshwari Rashmita Nathviju001Nessuna valutazione finora
- Fingerprint Orientation Field Enhancement: April 2011Documento9 pagineFingerprint Orientation Field Enhancement: April 2011viju001Nessuna valutazione finora
- T.A. & D.A. BillDocumento1 paginaT.A. & D.A. Billviju001Nessuna valutazione finora
- 04 - Chapter 1Documento19 pagine04 - Chapter 1viju001Nessuna valutazione finora
- 06 - Chapter 3Documento36 pagine06 - Chapter 3viju001Nessuna valutazione finora
- Fingerprint Enhancement Using Improved Orientation and Circular Gabor FilterDocumento7 pagineFingerprint Enhancement Using Improved Orientation and Circular Gabor Filterviju001Nessuna valutazione finora
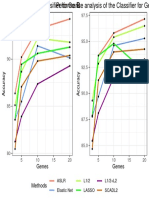
- Genes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2Documento1 paginaGenes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2viju001Nessuna valutazione finora
- Decision Making With Unknown Data: Development of ELECTRE Method Based On Black NumbersDocumento16 pagineDecision Making With Unknown Data: Development of ELECTRE Method Based On Black Numbersviju001Nessuna valutazione finora
- 14 - Chapter 6Documento7 pagine14 - Chapter 6viju001Nessuna valutazione finora
- Genes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2Documento1 paginaGenes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2viju001Nessuna valutazione finora
- Seeing Slow and Seeing Fast: Two Limits On Perception: Alex O. HolcombeDocumento6 pagineSeeing Slow and Seeing Fast: Two Limits On Perception: Alex O. HolcombeDag SpakaNessuna valutazione finora
- How Languages Are Learned 4th Edition: Patsy M. Lightbown and Nina Spada Summary of Chapter 6Documento32 pagineHow Languages Are Learned 4th Edition: Patsy M. Lightbown and Nina Spada Summary of Chapter 6phamhungthuyenNessuna valutazione finora
- Case Assignment #2 - Cabin in The MountainsDocumento7 pagineCase Assignment #2 - Cabin in The MountainsArturoBojorquezNessuna valutazione finora
- 6 Thinking (Compatibility Mode)Documento21 pagine6 Thinking (Compatibility Mode)BhargavNessuna valutazione finora
- Comm Skills NotesDocumento25 pagineComm Skills NotesGloria GichehaNessuna valutazione finora
- Teaching English in Elementary PresentationDocumento78 pagineTeaching English in Elementary PresentationLaarni Samonte Cereno100% (1)
- Chapter Seven: Electronic Training Methods Multiple-Choice QuestionsDocumento8 pagineChapter Seven: Electronic Training Methods Multiple-Choice QuestionsNotesfreeBook100% (1)
- Note MakingDocumento12 pagineNote MakingAnas AliNessuna valutazione finora
- Chapter 6Documento12 pagineChapter 6Juju ZenemijNessuna valutazione finora
- Teaching Practice 3 Iere Lesson PlanDocumento5 pagineTeaching Practice 3 Iere Lesson Planapi-29894802750% (2)
- Observed Lesson #1 PDFDocumento6 pagineObserved Lesson #1 PDFJenna CaroleNessuna valutazione finora
- Psychology Lecture 2 2020 2021Documento3 paginePsychology Lecture 2 2020 2021Oussama HarizNessuna valutazione finora
- Semi-Detailed Lesson Plan in English I. ObjectivesDocumento2 pagineSemi-Detailed Lesson Plan in English I. ObjectivesMark Vincent FernandezNessuna valutazione finora
- Paraphrase This! ™: InstructionsDocumento2 pagineParaphrase This! ™: InstructionsThuỷ Nguyên LạiNessuna valutazione finora
- Essay 4Documento4 pagineEssay 4api-490219069Nessuna valutazione finora
- Robbins Eob13ge Ppt06Documento28 pagineRobbins Eob13ge Ppt06Mingxiang WuNessuna valutazione finora
- NST IB Experimental Psychology Course Guide 2017-18 - NST and PBSDocumento29 pagineNST IB Experimental Psychology Course Guide 2017-18 - NST and PBSGustavo SilvaNessuna valutazione finora
- Daily Instructional Plan: Tanauan School of Craftsmanship and Home Industries Leyte DivisionDocumento4 pagineDaily Instructional Plan: Tanauan School of Craftsmanship and Home Industries Leyte DivisionMary Ann IsananNessuna valutazione finora
- Mount Everest Potential CausesDocumento8 pagineMount Everest Potential CausesNitin SinghNessuna valutazione finora