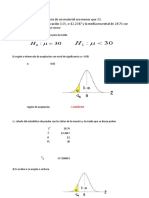
Potrebbero piacerti anche
- Análisis estadístico de datos multivariadosDa EverandAnálisis estadístico de datos multivariadosValutazione: 5 su 5 stelle5/5 (1)
- Contraste de Hipotesis Diferencia Entre Proporciones Poblacionales Trabajp SocialDocumento6 pagineContraste de Hipotesis Diferencia Entre Proporciones Poblacionales Trabajp SocialDanny Quilca50% (2)
- Taller 1 Probabilidad IIDocumento9 pagineTaller 1 Probabilidad IIJohn PalaciosNessuna valutazione finora
- Comparativa de recubrimientos para tubos: A vs BDocumento4 pagineComparativa de recubrimientos para tubos: A vs BJhon AguilarNessuna valutazione finora
- Intervalo de confianza para la media y diferencia de mediaDocumento2 pagineIntervalo de confianza para la media y diferencia de mediaJorfranDuicaVasquezNessuna valutazione finora
- EJERCICIOS DE HIPOTESIS UladechDocumento5 pagineEJERCICIOS DE HIPOTESIS UladechNorlinda LlashagNessuna valutazione finora
- Guión 10Documento2 pagineGuión 10Josué RubioNessuna valutazione finora
- Avance de La Tarea 8 Distribucion NormalDocumento18 pagineAvance de La Tarea 8 Distribucion NormalaydeeNessuna valutazione finora
- Muestreo Enviarcontabilidad1Documento54 pagineMuestreo Enviarcontabilidad1FilosofiadeContabilidadNessuna valutazione finora
- Taller Distribución NormalDocumento8 pagineTaller Distribución NormalDanna HernándezNessuna valutazione finora
- Pruebas de HipotesisDocumento8 paginePruebas de HipotesisAndrea OrellanaNessuna valutazione finora
- Unidad 5 Mat 260 VeranoDocumento43 pagineUnidad 5 Mat 260 VeranoIver SumiNessuna valutazione finora
- 4.1 Blanco Camacho Aline XimenaDocumento15 pagine4.1 Blanco Camacho Aline XimenaBlanco Camacho Aline XimenaNessuna valutazione finora
- Medidas de Tendencia Central ...Documento40 pagineMedidas de Tendencia Central ...Manuel AvalosNessuna valutazione finora
- MPRO1 U4 A3 EjerciciosDocumento3 pagineMPRO1 U4 A3 EjerciciosadrianNessuna valutazione finora
- Distribución normal: problemas de probabilidad y estadísticaDocumento1 paginaDistribución normal: problemas de probabilidad y estadísticaFernando ParedesNessuna valutazione finora
- Taller de Estadística Descriptiva.Documento12 pagineTaller de Estadística Descriptiva.ANDREA CAROLINA NOGUERA TOVARNessuna valutazione finora
- Guía-Variables Aleatorias Discretas-BioestadisticaDocumento14 pagineGuía-Variables Aleatorias Discretas-BioestadisticaLuz Adriana Martinez VasquezNessuna valutazione finora
- Semana - 1 2019 IiDocumento46 pagineSemana - 1 2019 IiJholsin Flores VargasNessuna valutazione finora
- Practica 8Documento15 paginePractica 8Isabel RoboltNessuna valutazione finora
- Probabilidad promedio salario mineros carbón muestra 25 inferir 857.500Documento1 paginaProbabilidad promedio salario mineros carbón muestra 25 inferir 857.500Eivis Meza PalenciaNessuna valutazione finora
- Tarea 3 - Intervalos de ConfianzaDocumento3 pagineTarea 3 - Intervalos de ConfianzaGiampiero 0709Nessuna valutazione finora
- Prueba de hipótesis para comparar medias de dos muestras con desviaciones estándares desconocidasDocumento23 paginePrueba de hipótesis para comparar medias de dos muestras con desviaciones estándares desconocidasLisbeth LimaNessuna valutazione finora
- Trabajo 4Documento4 pagineTrabajo 4Yadira Kimberly E. FerreNessuna valutazione finora
- Taller Unidad 4Documento3 pagineTaller Unidad 4Mafer SolorzanoNessuna valutazione finora
- Taller Estadistica IDocumento17 pagineTaller Estadistica IJulian Andres GorronNessuna valutazione finora
- Taller Repaso EstadisticaDocumento8 pagineTaller Repaso EstadisticajhonrubianoNessuna valutazione finora
- Matriz de Tendencia de VariablesDocumento4 pagineMatriz de Tendencia de VariablesVictor Matos DanielsNessuna valutazione finora
- Pruebas de Hipótesis EQP (-3) 2.0Documento36 paginePruebas de Hipótesis EQP (-3) 2.0AzkizzNessuna valutazione finora
- Ejercicios Resueltos Sesión 2-3205Documento4 pagineEjercicios Resueltos Sesión 2-3205Luiis AlfonsoNessuna valutazione finora
- Prueba de Hipótesis Media 2Documento11 paginePrueba de Hipótesis Media 2Mery Fernández HurtadoNessuna valutazione finora
- Actividad Grupal Unidad 3 Distribuciones de ProbabilidadDocumento4 pagineActividad Grupal Unidad 3 Distribuciones de ProbabilidadYANUDIS ROJAS RAMOSNessuna valutazione finora
- Trabajo Intervalos de Confianza Grupo 1Documento14 pagineTrabajo Intervalos de Confianza Grupo 1Bryan Rivas ChavezNessuna valutazione finora
- Tarea de La Unidad 3 BioestadisticaDocumento3 pagineTarea de La Unidad 3 BioestadisticaSánchez IsisNessuna valutazione finora
- Semana 2 EstadisticaDocumento10 pagineSemana 2 EstadisticaELIZABETH BRISSET SILVA MONTESINOSNessuna valutazione finora
- TALLER 1 Grupo No 3 EstadisticaDocumento7 pagineTALLER 1 Grupo No 3 EstadisticaKarina Sabogal Moreno100% (1)
- Pruebas de HipotesisDocumento32 paginePruebas de HipotesisMaria Jose0% (1)
- Probabilida y Estadistica191116Documento312 pagineProbabilida y Estadistica191116Luis SulbaranNessuna valutazione finora
- Actividad 3.1 Tema 3Documento4 pagineActividad 3.1 Tema 3Juan Camaney100% (1)
- Modelos de optimización para problemas de producción y mezclasDocumento4 pagineModelos de optimización para problemas de producción y mezclasmauroNessuna valutazione finora
- Probabilidad de proyectiles defectuososDocumento43 pagineProbabilidad de proyectiles defectuososMarco Fidel Pedraza ManriqueNessuna valutazione finora
- Distribucion Muestral de ProporciónDocumento19 pagineDistribucion Muestral de ProporciónDen Fit SouNessuna valutazione finora
- Pruebas T Independientes PDFDocumento9 paginePruebas T Independientes PDFDavid Alfonso ChuquinNessuna valutazione finora
- UNIDAD II - Probabilidades y Distribuciones - IC2021 - 5ta ParteDocumento19 pagineUNIDAD II - Probabilidades y Distribuciones - IC2021 - 5ta PartemasmianNessuna valutazione finora
- Prueba de HipotesisDocumento1 paginaPrueba de HipotesisGoku Bart HackNessuna valutazione finora
- Taller DistribucionesDocumento4 pagineTaller DistribucionesdimitryNessuna valutazione finora
- Ejercicios de Muestreo Introduccion 1Documento4 pagineEjercicios de Muestreo Introduccion 1anon_197508509Nessuna valutazione finora
- Pia EstadisticaDocumento21 paginePia EstadisticaKevin Cuellar33% (3)
- Tarea Prueba de Hipotesis para Dos MuestrasDocumento2 pagineTarea Prueba de Hipotesis para Dos MuestrasferNessuna valutazione finora
- Distribucion Continuas Completa Teoria PDFDocumento12 pagineDistribucion Continuas Completa Teoria PDFraymundoNessuna valutazione finora
- Neumáticos fabricante análisis km pinchazoDocumento6 pagineNeumáticos fabricante análisis km pinchazoRicardo CevallosNessuna valutazione finora
- Estadística ambiental ejerciciosDocumento3 pagineEstadística ambiental ejerciciosdaniel advincula50% (2)
- Diferencia de ProporcionesDocumento3 pagineDiferencia de Proporcionescarolina ogazaNessuna valutazione finora
- Taller 4 - Estadística InferencialDocumento9 pagineTaller 4 - Estadística Inferencialdavd 007Nessuna valutazione finora
- Estadistica 4Documento15 pagineEstadistica 4hockpinNessuna valutazione finora
- Ejercicios de Derivadas 9 Orden SuperiorDocumento4 pagineEjercicios de Derivadas 9 Orden SuperiorMariel TuaNessuna valutazione finora
- Organización de datos estadísticosDocumento12 pagineOrganización de datos estadísticosel chidoNessuna valutazione finora
- Distribución muestral de la varianzaDocumento25 pagineDistribución muestral de la varianzaBmCrew Oficial MXNessuna valutazione finora
- Actividad#10 EstadisticaDocumento8 pagineActividad#10 EstadisticaLuis AyalaNessuna valutazione finora
- Canaleta Parshall TablasDocumento2 pagineCanaleta Parshall TablasCristian VallejoNessuna valutazione finora
- Capötulo 3Documento150 pagineCapötulo 3elmushkaNessuna valutazione finora
- Ejemplo Canaleta ParshallDocumento3 pagineEjemplo Canaleta ParshallCristian VallejoNessuna valutazione finora
- Consideraciones de Diseño Mezcla RapidaDocumento3 pagineConsideraciones de Diseño Mezcla RapidaCristian VallejoNessuna valutazione finora
- Capötulo 4 - 1Documento440 pagineCapötulo 4 - 1elmushkaNessuna valutazione finora
- Partes constitutivas de un alcantarillado: tuberías y estructuras complementariasDocumento46 paginePartes constitutivas de un alcantarillado: tuberías y estructuras complementariasCristian VallejoNessuna valutazione finora
- Capitulo 7Documento31 pagineCapitulo 7Cristian VallejoNessuna valutazione finora
- Ejemplo Remoción de ParticulasDocumento2 pagineEjemplo Remoción de ParticulasCristian VallejoNessuna valutazione finora
- Diseño y parámetros de aliviaderos en sistemas de alcantarilladoDocumento33 pagineDiseño y parámetros de aliviaderos en sistemas de alcantarilladoCristian VallejoNessuna valutazione finora
- Capitulo 1Documento12 pagineCapitulo 1Cristian VallejoNessuna valutazione finora
- Capitulo 6Documento34 pagineCapitulo 6Cristian VallejoNessuna valutazione finora
- Capötulo 3Documento150 pagineCapötulo 3elmushkaNessuna valutazione finora
- Capitulo 4Documento18 pagineCapitulo 4Cristian VallejoNessuna valutazione finora
- Consideraciones generales para el diseño de alcantarilladosDocumento19 pagineConsideraciones generales para el diseño de alcantarilladosCristian VallejoNessuna valutazione finora
- Iii Parcial Estructuras IDocumento1 paginaIii Parcial Estructuras IJhon Jairo GomezNessuna valutazione finora
- Capötulo 6 - 1Documento432 pagineCapötulo 6 - 1elmushkaNessuna valutazione finora
- Ejercicios de Cálculo Vectorial IDocumento6 pagineEjercicios de Cálculo Vectorial IhousegrjNessuna valutazione finora
- El teodolito: definición, centraje, nivelación y usosDocumento39 pagineEl teodolito: definición, centraje, nivelación y usosCristian VallejoNessuna valutazione finora
- 03 Volumenes de TransitoDocumento13 pagine03 Volumenes de TransitoCristian VallejoNessuna valutazione finora
- Unidad 3 Rocas Parte 1Documento53 pagineUnidad 3 Rocas Parte 1Cristian VallejoNessuna valutazione finora
- Capötulo 5Documento122 pagineCapötulo 5elmushkaNessuna valutazione finora
- Probabilidad y EstadisticaDocumento30 pagineProbabilidad y EstadisticaCristian VallejoNessuna valutazione finora
- GENERALIDADES - GEOLOGÍA: Introducción a la datación relativa y absolutaDocumento30 pagineGENERALIDADES - GEOLOGÍA: Introducción a la datación relativa y absolutaCristian VallejoNessuna valutazione finora
- GeologiaDocumento4 pagineGeologiaCristian VallejoNessuna valutazione finora
- Formato Apa GeneralDocumento18 pagineFormato Apa GeneralJonathan' Cuotto Dellán'Nessuna valutazione finora
- Mecanica y Fluidos CentrifugaciónDocumento5 pagineMecanica y Fluidos CentrifugacióncarlosalfredorivasNessuna valutazione finora
- Ejercios FisicaDocumento39 pagineEjercios Fisicarecallscrib100% (1)
- Informe 4 Densidad y Absorcion en Agregado Grueso, FinoDocumento17 pagineInforme 4 Densidad y Absorcion en Agregado Grueso, Finoedison t90% (59)
- Granulometría de agregados para concretoDocumento10 pagineGranulometría de agregados para concretoKaren ZavalaNessuna valutazione finora
- Análisis estructural por pendiente-deflexión y SAP 2000Documento23 pagineAnálisis estructural por pendiente-deflexión y SAP 2000Andres Daniel Moreno BecerraNessuna valutazione finora
- Actitud Del ConsumidorDocumento3 pagineActitud Del ConsumidorJonah GalarzaNessuna valutazione finora
- Pastores Dabo VobisDocumento12 paginePastores Dabo VobisEdu portuguezNessuna valutazione finora
- Cuestiones TipológicasDocumento3 pagineCuestiones TipológicasNorma CamilaNessuna valutazione finora
- Cuidados de Enfermeria en La MenopausiaDocumento2 pagineCuidados de Enfermeria en La MenopausiaCinThia Villafane EstradaNessuna valutazione finora
- Actividad 5 Cartilla DigitalDocumento18 pagineActividad 5 Cartilla DigitalJaneth Quiroga ArizaNessuna valutazione finora
- 01 - Bucaramanga (Plan de Desarrollo 2016-2019 Gobierno de Las Ciudadanas y Los Ciudadanos) PDFDocumento572 pagine01 - Bucaramanga (Plan de Desarrollo 2016-2019 Gobierno de Las Ciudadanas y Los Ciudadanos) PDFcantillo2222Nessuna valutazione finora
- Wenceslao Lavinius de Moravia - Tratado Del Cielo TerrestreDocumento2 pagineWenceslao Lavinius de Moravia - Tratado Del Cielo Terrestrejumpin_around100% (1)
- Lista de Emperadores RomanosDocumento7 pagineLista de Emperadores RomanosGonzalo MantillaNessuna valutazione finora
- APOCALIPSISDocumento57 pagineAPOCALIPSISBENNY SIBAJANessuna valutazione finora
- Anejo 6d-Acta de Incidencia Consolidacion Electores y Papeletas - SJ 004 FinalDocumento1 paginaAnejo 6d-Acta de Incidencia Consolidacion Electores y Papeletas - SJ 004 FinalMetro Puerto RicoNessuna valutazione finora
- Muri, Mura, Muda y Los 7 DesperdiciosDocumento9 pagineMuri, Mura, Muda y Los 7 DesperdiciosVictor Hernandez ArchundiaNessuna valutazione finora
- Registro equipo mantenimientoDocumento4 pagineRegistro equipo mantenimientoHelbert Gabino Manrique RamirezNessuna valutazione finora
- Cambio Organizacional para Una Mayor CompetitividadDocumento6 pagineCambio Organizacional para Una Mayor CompetitividadvaleNessuna valutazione finora
- AZUL de PRUSIA (Bernie Gunther 12) de Philip KerrDocumento2 pagineAZUL de PRUSIA (Bernie Gunther 12) de Philip KerrJoan Estrada FiguerasNessuna valutazione finora
- DIAGNÓSTICO DE VERTICALIDAD Y REDONDEZ EN TANQUES DE COMBUSTIBLE POR GEODESIADocumento8 pagineDIAGNÓSTICO DE VERTICALIDAD Y REDONDEZ EN TANQUES DE COMBUSTIBLE POR GEODESIACristian Abanto LeónNessuna valutazione finora
- Apuntes CalculoDocumento137 pagineApuntes CalculoedwinNessuna valutazione finora
- 407209665-CUESTIONARIO-actividad 1 de 1.odtDocumento8 pagine407209665-CUESTIONARIO-actividad 1 de 1.odtsaul fraguaNessuna valutazione finora
- Presentacion Crecimiento y DesarrolloDocumento35 paginePresentacion Crecimiento y DesarrolloCARMEN PILAR WONG RAMOSNessuna valutazione finora
- EPT-EMP-C6-Sesión 1Documento4 pagineEPT-EMP-C6-Sesión 1Elizabeth Gutierrez Huamani100% (2)
- 5 Criptosporosis y CiclosporosisDocumento6 pagine5 Criptosporosis y CiclosporosisANA MARIA TORRES LUNANessuna valutazione finora
- Seminario G1 - Replicación Del DNADocumento11 pagineSeminario G1 - Replicación Del DNAABRIL SOFIA CALDERON TERANNessuna valutazione finora
- Discriminación visual y auditivaDocumento6 pagineDiscriminación visual y auditivaVia SajaNessuna valutazione finora
- Ventajas y Desventajas de Pozos MultilateralesDocumento9 pagineVentajas y Desventajas de Pozos MultilateralesandreacallizayaNessuna valutazione finora
- Diseño Curricular Panaderia Basica IDocumento4 pagineDiseño Curricular Panaderia Basica Ijrectasena50% (2)
- PPS U3 A2 Jocm.Documento6 paginePPS U3 A2 Jocm.Jonathan CammarNessuna valutazione finora
- Guía de Manejo Fisioterapéutico Del Síndrome de Desacondicionamiento Físico en Pacientes Con Guillain Barré en Unidad de Cuidado IntensivoDocumento114 pagineGuía de Manejo Fisioterapéutico Del Síndrome de Desacondicionamiento Físico en Pacientes Con Guillain Barré en Unidad de Cuidado IntensivoMaca LlanosNessuna valutazione finora
- Capítulos 1-2-3-5Documento140 pagineCapítulos 1-2-3-5Vanessa CachagoNessuna valutazione finora
- Origen y Conservacion de Los Alimentos A Lo Largo de La Historia-Doc.4Documento6 pagineOrigen y Conservacion de Los Alimentos A Lo Largo de La Historia-Doc.4coordinaciongastrolaet100% (2)
- Comunicación AsertivaDocumento8 pagineComunicación AsertivaEvelyn ArandaNessuna valutazione finora