Potrebbero piacerti anche
- Industrial Organization and Management: REVIEWERDocumento8 pagineIndustrial Organization and Management: REVIEWERGuian RomasantaNessuna valutazione finora
- SportsDocumento21 pagineSportsVeronica ReganitNessuna valutazione finora
- Viernes Jamaeca B. Aben 3412 Lec Module 3 PDFDocumento11 pagineViernes Jamaeca B. Aben 3412 Lec Module 3 PDFBanana QNessuna valutazione finora
- Water Supply Fixture Units Table 6 5Documento1 paginaWater Supply Fixture Units Table 6 5miranarvacan12Nessuna valutazione finora
- Case Study ChernobylDocumento4 pagineCase Study ChernobylLouie Shaolin LungaoNessuna valutazione finora
- Pme 896 - Capstone Project Rubric-James WallerDocumento1 paginaPme 896 - Capstone Project Rubric-James Wallerapi-450537948Nessuna valutazione finora
- SAD Chapter 3Documento42 pagineSAD Chapter 3Maxbuub AxmedNessuna valutazione finora
- Airtel Brand Extension CompressDocumento7 pagineAirtel Brand Extension CompressDarshan GohilNessuna valutazione finora
- ICT Integration in New Normal EducationDocumento47 pagineICT Integration in New Normal EducationRomulo A. Cordez Jr.Nessuna valutazione finora
- Tubal Ensc 20133 Technopreneurship 101Documento110 pagineTubal Ensc 20133 Technopreneurship 101randolf elmidoNessuna valutazione finora
- Digital Circuit Work Book F1Documento33 pagineDigital Circuit Work Book F1swaransh patelNessuna valutazione finora
- Discrete MathematicsDocumento8 pagineDiscrete MathematicsAman AgrawalNessuna valutazione finora
- VMKV Engineering College Department of Computer Science & Engineering Principles of Compiler Design Unit I Part-ADocumento80 pagineVMKV Engineering College Department of Computer Science & Engineering Principles of Compiler Design Unit I Part-ADular ChandranNessuna valutazione finora
- 7.CD Lab ManualDocumento35 pagine7.CD Lab ManualBHARTI RAWATNessuna valutazione finora
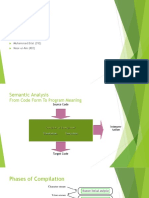
- 5 Sementic Analysis and Intermediate LanguagesDocumento10 pagine5 Sementic Analysis and Intermediate Languagesoliver OduyaNessuna valutazione finora
- Compiler Design 1Documento30 pagineCompiler Design 1Laptop StorageNessuna valutazione finora
- Compiler Construction Chapter 6Documento111 pagineCompiler Construction Chapter 6HammadHussainNessuna valutazione finora
- Compiler Design - Lexical Analysis: University of Salford, UKDocumento1 paginaCompiler Design - Lexical Analysis: University of Salford, UKAmmar MehmoodNessuna valutazione finora
- CD-Ch04 SDTDocumento15 pagineCD-Ch04 SDTHASEN SEIDNessuna valutazione finora
- SE Compiler Chapter 2Documento16 pagineSE Compiler Chapter 2mikiberhanu41Nessuna valutazione finora
- Chapter 2Documento56 pagineChapter 2Ermias MesfinNessuna valutazione finora
- Chapter 4 Semantic Analysis PDFDocumento16 pagineChapter 4 Semantic Analysis PDFAmin mohammedNessuna valutazione finora
- Group Members: Sohail Memon (429) Abdul Qayoom (350) Rehmatullah (408) Muhammad Bilal (392) Noor-ul-AinDocumento15 pagineGroup Members: Sohail Memon (429) Abdul Qayoom (350) Rehmatullah (408) Muhammad Bilal (392) Noor-ul-AinSohail JaffarNessuna valutazione finora
- CH04Documento24 pagineCH04zemikeNessuna valutazione finora
- CC QuestionsDocumento9 pagineCC QuestionsjagdishNessuna valutazione finora
- Compiler ConstructionDocumento14 pagineCompiler ConstructionMa¡RNessuna valutazione finora
- Compiler Construction CS-4207: Lecture 4-5 Instructor Name: Atif IshaqDocumento37 pagineCompiler Construction CS-4207: Lecture 4-5 Instructor Name: Atif IshaqFaisal ShehzadNessuna valutazione finora
- G52Cmp Compilers: Syntax AnalysisDocumento36 pagineG52Cmp Compilers: Syntax AnalysisKim MeyNessuna valutazione finora
- CSE2002 - Module6 - PARTA - NotesDocumento39 pagineCSE2002 - Module6 - PARTA - NotesGokul SrinathNessuna valutazione finora
- Compiler Theory: (A Simple Syntax-Directed Translator)Documento50 pagineCompiler Theory: (A Simple Syntax-Directed Translator)Syed Noman Ali ShahNessuna valutazione finora
- Chapter 3 Lexical AnalysisDocumento5 pagineChapter 3 Lexical AnalysisAmal AhmadNessuna valutazione finora
- Semantic Analysis in Compiler DesignDocumento8 pagineSemantic Analysis in Compiler DesignRamna SatarNessuna valutazione finora
- Chapter 2Documento91 pagineChapter 2Mikiyas GetasewNessuna valutazione finora
- CSC 318 Class NotesDocumento21 pagineCSC 318 Class NotesYerumoh DanielNessuna valutazione finora
- Compiler Design Chapter-4Documento77 pagineCompiler Design Chapter-4Vuggam Venkatesh100% (2)
- Chapter 2 - Lexical AnalyserDocumento39 pagineChapter 2 - Lexical AnalyserAbrham EnjireNessuna valutazione finora
- ALL The ROUGH Pages Included From Lesson 1,2,3,4,5 Are Not Included in The PaperDocumento41 pagineALL The ROUGH Pages Included From Lesson 1,2,3,4,5 Are Not Included in The PaperR U Bored ??Nessuna valutazione finora
- Unit 6Documento109 pagineUnit 6Jay ShahNessuna valutazione finora
- Chapter 2 - Lexical AnalyserDocumento38 pagineChapter 2 - Lexical AnalyserYitbarek MurcheNessuna valutazione finora
- Week 2 Lec 4 CCDocumento28 pagineWeek 2 Lec 4 CCSohaib KashmiriNessuna valutazione finora
- Chapter 4Documento35 pagineChapter 4hailomNessuna valutazione finora
- Compiler 6Documento28 pagineCompiler 6Tayyab FiazNessuna valutazione finora
- Chapter - Two: Lexical AnalysisDocumento31 pagineChapter - Two: Lexical AnalysisBlack PandaNessuna valutazione finora
- CS3304 9 LanguageSyntax 2 PDFDocumento39 pagineCS3304 9 LanguageSyntax 2 PDFrubaNessuna valutazione finora
- Chapter 2 - Lexical AnalyserDocumento40 pagineChapter 2 - Lexical Analyserbekalu alemayehuNessuna valutazione finora
- Compiler Design Chapter-2Documento105 pagineCompiler Design Chapter-2Vuggam Venkatesh60% (5)
- Mod 1Documento24 pagineMod 1Subhashree PradhanNessuna valutazione finora
- CD 1Documento23 pagineCD 1PonnuNessuna valutazione finora
- Symbol Tables Are Data Structures That Are Used by Compilers To Hold InformationDocumento3 pagineSymbol Tables Are Data Structures That Are Used by Compilers To Hold InformationHuma TarannumNessuna valutazione finora
- Syntax Directed TranslationDocumento49 pagineSyntax Directed TranslationKisiNessuna valutazione finora
- Unit 2-LEXICAL ANALYSISDocumento46 pagineUnit 2-LEXICAL ANALYSISBuvana MurugaNessuna valutazione finora
- Lec6 - SemanticAnalysis 3Documento38 pagineLec6 - SemanticAnalysis 3areejalqahtani214Nessuna valutazione finora
- LectureDocumento10 pagineLectureMariam KilanyNessuna valutazione finora
- Chapter 4Documento31 pagineChapter 4Arif AbdulelamNessuna valutazione finora
- CD Unit 1Documento35 pagineCD Unit 1Gomathi Aashika GeorgeNessuna valutazione finora
- CD - 2 MarksDocumento14 pagineCD - 2 MarksVIJAY KARTHICK X CSE studentNessuna valutazione finora
- Compiler Design WorkplaceDocumento64 pagineCompiler Design WorkplaceVishwakarma UniversityNessuna valutazione finora
- Unit - 2 Lexical AnalysisDocumento11 pagineUnit - 2 Lexical Analysismdumar umarNessuna valutazione finora
- Chapter 4 - Compiler Designnn 1 CompressedDocumento35 pagineChapter 4 - Compiler Designnn 1 Compressedmishamoamanuel574Nessuna valutazione finora
- Module 5Documento60 pagineModule 5indrajvyadavNessuna valutazione finora
- Containers: The Future of Virtualization & SDDC: Anil VasudevaDocumento24 pagineContainers: The Future of Virtualization & SDDC: Anil VasudevaOmaima MusaratNessuna valutazione finora
- Science Gateway NotesDocumento8 pagineScience Gateway NotesOmaima MusaratNessuna valutazione finora
- Software-Defined Networking of Linux Containers: September 2014Documento5 pagineSoftware-Defined Networking of Linux Containers: September 2014Omaima MusaratNessuna valutazione finora
- Amazon EC2: Platform To Learn New Skills in Computing & TechnologyDocumento20 pagineAmazon EC2: Platform To Learn New Skills in Computing & TechnologyOmaima MusaratNessuna valutazione finora
- Cloud Computing NotesDocumento14 pagineCloud Computing NotesOmaima MusaratNessuna valutazione finora
- LR (0) ParsingDocumento14 pagineLR (0) ParsingOmaima Musarat100% (1)
- Context Free Grammar and ParsingDocumento138 pagineContext Free Grammar and ParsingOmaima Musarat0% (1)
- Assignment#1: Busniess Report WritingDocumento29 pagineAssignment#1: Busniess Report WritingOmaima MusaratNessuna valutazione finora
- Hide Answer Notebook Notebook Discuss: Here Is The Answer and ExplanationDocumento16 pagineHide Answer Notebook Notebook Discuss: Here Is The Answer and ExplanationPayashwini KulkarniNessuna valutazione finora
- P103154 - 7.00 - Doc - Manual - 8000 WindlassDocumento43 pagineP103154 - 7.00 - Doc - Manual - 8000 WindlassDanNessuna valutazione finora
- Abhilash Betanamudi: AchievementsDocumento3 pagineAbhilash Betanamudi: AchievementsAbhilashBetanamudiNessuna valutazione finora
- Selecting EquipmentDocumento7 pagineSelecting EquipmentZara ShireenNessuna valutazione finora
- La 3391p Rev0.3novo DesbloqueadoDocumento48 pagineLa 3391p Rev0.3novo DesbloqueadoRogeriotabiraNessuna valutazione finora
- 50 Input Output Practice Questions 1606810110009 OBDocumento17 pagine50 Input Output Practice Questions 1606810110009 OBJavid QuadirNessuna valutazione finora
- Traulsen RLT - ALT Freezer DUTDocumento2 pagineTraulsen RLT - ALT Freezer DUTwsfc-ebayNessuna valutazione finora
- LC08 L1TP 120065 20180318 20180403 01 T1 MTLDocumento4 pagineLC08 L1TP 120065 20180318 20180403 01 T1 MTLrendy aswinNessuna valutazione finora
- SMS SRH-2D SedimentTransportDocumento19 pagineSMS SRH-2D SedimentTransportthendyNessuna valutazione finora
- Automatic Fruit Image Recognition System Based On Shape and Color FeaturesDocumento2 pagineAutomatic Fruit Image Recognition System Based On Shape and Color FeaturesakshayNessuna valutazione finora
- Reflexive Pronoun: Object SubjectDocumento5 pagineReflexive Pronoun: Object SubjectSiti Sarah Abdullah100% (1)
- Fiat Barchetta: EngineDocumento20 pagineFiat Barchetta: EngineHallex OliveiraNessuna valutazione finora
- Numerical Methods in Rock Mechanics - 2002 - International Journal of Rock Mechanics and Mining SciencesDocumento19 pagineNumerical Methods in Rock Mechanics - 2002 - International Journal of Rock Mechanics and Mining SciencesAnderson Lincol Condori PaytanNessuna valutazione finora
- UNIT1-Demand Management in Supply Chain Demand Planning and ForecastingDocumento20 pagineUNIT1-Demand Management in Supply Chain Demand Planning and Forecastingshenbha50% (2)
- Mole Concept - L1rr PDFDocumento27 pagineMole Concept - L1rr PDFLegend KillerNessuna valutazione finora
- AMC Measurement ProblemsDocumento2 pagineAMC Measurement ProblemseltoNessuna valutazione finora
- Diagbootx: // Public Release 1Documento4 pagineDiagbootx: // Public Release 1Tedy AdhinegoroNessuna valutazione finora
- Temperature Transmitter TR45Documento16 pagineTemperature Transmitter TR45cysautsNessuna valutazione finora
- System Administration JakartaDocumento347 pagineSystem Administration JakartaLorena Castillero80% (10)
- Unit Iv Ce 6405Documento13 pagineUnit Iv Ce 6405HanafiahHamzahNessuna valutazione finora
- Analytic Geometry Parabola ProblemsDocumento14 pagineAnalytic Geometry Parabola ProblemsOjit QuizonNessuna valutazione finora
- Inform: Extending PhoenicsDocumento42 pagineInform: Extending PhoenicsrsigorNessuna valutazione finora
- Ordered Groups and Infinite Permutation Groups PDFDocumento252 pagineOrdered Groups and Infinite Permutation Groups PDFmc180401877Nessuna valutazione finora
- HVSI804T WGD 83Documento6 pagineHVSI804T WGD 83mnezamiNessuna valutazione finora
- Piaggio X8 250 I.E. (EN)Documento289 paginePiaggio X8 250 I.E. (EN)Manualles100% (8)
- 4.uses of Metals - 1-32 For StudentsDocumento13 pagine4.uses of Metals - 1-32 For StudentsnergisalihpasaogluNessuna valutazione finora
- DPP 01 Periodic Table JH Sir-3576 PDFDocumento5 pagineDPP 01 Periodic Table JH Sir-3576 PDFChessNessuna valutazione finora
- Penn State University Press Is Collaborating With JSTOR To Digitize, Preserve and Extend Access To Philosophy & RhetoricDocumento16 paginePenn State University Press Is Collaborating With JSTOR To Digitize, Preserve and Extend Access To Philosophy & RhetoricvanduongNessuna valutazione finora
- DC DC BoostDocumento21 pagineDC DC BoosttrshaaaNessuna valutazione finora
- Condensation and BoilingDocumento14 pagineCondensation and BoilingCrislyn Akilit Bayawa100% (1)