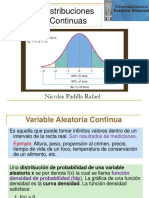
Potrebbero piacerti anche
- CUESTIONARIODocumento7 pagineCUESTIONARIOAdam Parrish100% (1)
- EA PPT 2020-I - II - SEM 1 Distribucion NormalDocumento14 pagineEA PPT 2020-I - II - SEM 1 Distribucion Normalelvis albertoNessuna valutazione finora
- Distribucion NormalDocumento3 pagineDistribucion NormalSandro BVNessuna valutazione finora
- Otras Distribuciones ContinuasDocumento12 pagineOtras Distribuciones ContinuasJimmy JaramilloNessuna valutazione finora
- Distribucion NormalDocumento33 pagineDistribucion NormalEdwin Andres Salazar100% (9)
- Pri Aux HyH Que EC Presentacion Web PDFDocumento113 paginePri Aux HyH Que EC Presentacion Web PDFAdrianita Vega RodriguezNessuna valutazione finora
- Distribuciones ContinuasDocumento42 pagineDistribuciones ContinuasDisperatoNessuna valutazione finora
- Unidad 6 - Distribuciones de Probabilidad ContinuasDocumento31 pagineUnidad 6 - Distribuciones de Probabilidad ContinuasOverstreetNessuna valutazione finora
- Variables Continuas Y Sus Distribuciones de ProbabilidadDocumento44 pagineVariables Continuas Y Sus Distribuciones de ProbabilidadSebastian PenagosNessuna valutazione finora
- EG 16 - Distribucion NormalDocumento46 pagineEG 16 - Distribucion Normalm.s.v18xNessuna valutazione finora
- ESTADÍSTICA APLICADA Semana 13Documento31 pagineESTADÍSTICA APLICADA Semana 13Nancy Sanchez LlicanNessuna valutazione finora
- Unidad 2 Distribución de Prob para Variables Aleatorias ContinúasDocumento9 pagineUnidad 2 Distribución de Prob para Variables Aleatorias Continúaspatricia0torres-24Nessuna valutazione finora
- Distrubucion NormalDocumento34 pagineDistrubucion NormalMarce PazmiñoNessuna valutazione finora
- Tema 5 - Modelos Continuos de ProbabilidadDocumento46 pagineTema 5 - Modelos Continuos de Probabilidadnahuelprost5Nessuna valutazione finora
- Semana 14 - Distribucion de Probabilidad Continua - Distribución Normal - EstandarizacionDocumento27 pagineSemana 14 - Distribucion de Probabilidad Continua - Distribución Normal - EstandarizacionHanna LoyolaNessuna valutazione finora
- Bio Dist. ContinuasDocumento30 pagineBio Dist. ContinuasSofiaNessuna valutazione finora
- Distribuciones Continuas II PDFDocumento28 pagineDistribuciones Continuas II PDFLuis HerreraNessuna valutazione finora
- EDA - Unidad 9 - Distribuciones de Probabilidad Continua (v1)Documento27 pagineEDA - Unidad 9 - Distribuciones de Probabilidad Continua (v1)Cielo Sthephan Ramírez CastroNessuna valutazione finora
- POWER POINT-. Distribuciones de Probabilidad2Documento31 paginePOWER POINT-. Distribuciones de Probabilidad2Jonatan FassioNessuna valutazione finora
- Distribuciones de Probabilidad Continua Parte 2Documento24 pagineDistribuciones de Probabilidad Continua Parte 2Albert HernandezNessuna valutazione finora
- Distribuci N NormalDocumento6 pagineDistribuci N NormalRodrigo del CidNessuna valutazione finora
- Distribucion - Normal - DefDocumento18 pagineDistribucion - Normal - DefLASALLE2014Nessuna valutazione finora
- Sesion5 Distrib NormalDocumento12 pagineSesion5 Distrib NormalMarvin ParionaNessuna valutazione finora
- Lectura Semana 8Documento18 pagineLectura Semana 8marthaNessuna valutazione finora
- Dr. Jesús Alberto MelladoDocumento8 pagineDr. Jesús Alberto MelladoAna Yatzin SorianoNessuna valutazione finora
- Distribuciones ContinuasDocumento71 pagineDistribuciones ContinuasAlejandrina De Boutaud100% (1)
- La Distribución NormalDocumento3 pagineLa Distribución NormalGerson GamboaNessuna valutazione finora
- Distribucion Normal 3Documento34 pagineDistribucion Normal 3Mauricio StanleyNessuna valutazione finora
- Sesión11 Modelos Continuos Meca Unfv 2016Documento33 pagineSesión11 Modelos Continuos Meca Unfv 2016Carla Flores DiasNessuna valutazione finora
- Distrib MuestralesDocumento9 pagineDistrib MuestralesJohnnyNessuna valutazione finora
- Semana14 Distribucion NormalDocumento15 pagineSemana14 Distribucion NormalSergio Cortez EstradaNessuna valutazione finora
- Dis Tri Buci On NormalDocumento9 pagineDis Tri Buci On NormalcrixxNessuna valutazione finora
- Distribución de Variables ContinuasDocumento28 pagineDistribución de Variables ContinuasGabriela RodriguezNessuna valutazione finora
- Clase 28 Distribución Normal 2016Documento26 pagineClase 28 Distribución Normal 2016Catalina Paz SalazarNessuna valutazione finora
- Distribuciones ContinuasDocumento57 pagineDistribuciones ContinuasFlor Samantha FranciscoNessuna valutazione finora
- Distribuciones de Probabilidad ContinuasDocumento7 pagineDistribuciones de Probabilidad ContinuasGabriel MontesinosNessuna valutazione finora
- Capitulo 6Documento31 pagineCapitulo 6Allan FabricioNessuna valutazione finora
- Unidad 1 Parte 2 ContinuasDocumento12 pagineUnidad 1 Parte 2 ContinuasReinaldo Perez FloresNessuna valutazione finora
- Distribuciones ContinuasDocumento23 pagineDistribuciones ContinuasEugenio MartinezNessuna valutazione finora
- Variable Aleatoria Continua NormalDocumento20 pagineVariable Aleatoria Continua NormalAddy CercadoNessuna valutazione finora
- Distribuciones Continuas - IIDocumento28 pagineDistribuciones Continuas - IIVargas Alex100% (2)
- Distribuciones ContinuasDocumento71 pagineDistribuciones ContinuasLorenita AguilarNessuna valutazione finora
- Uso de La Distribucion NormalDocumento26 pagineUso de La Distribucion NormalNéstor VargasNessuna valutazione finora
- Sesión 4 - Métodos Estadísticos Distribuciones Continuas1Documento41 pagineSesión 4 - Métodos Estadísticos Distribuciones Continuas1ANDRES DAVID ALZATE JIMENEZNessuna valutazione finora
- MODULO 1. LA DISTRIBUCION NORMAL y PRUEBDocumento11 pagineMODULO 1. LA DISTRIBUCION NORMAL y PRUEBMauricio de jesusNessuna valutazione finora
- Distribución NormalDocumento43 pagineDistribución NormalMaria FelipeNessuna valutazione finora
- 04 - Distribuciones Normal y Normal EstándarDocumento22 pagine04 - Distribuciones Normal y Normal EstándarLina FernandezNessuna valutazione finora
- Distribucion ProbabilidadesDocumento21 pagineDistribucion Probabilidadesanon_653709434Nessuna valutazione finora
- Distribución Normal, Ejercicios Resueltos - MatemóvilDocumento15 pagineDistribución Normal, Ejercicios Resueltos - MatemóvilDavid GarciaNessuna valutazione finora
- Distribución Normal de ProbabilidadesDocumento9 pagineDistribución Normal de ProbabilidadesJhamir AngelNessuna valutazione finora
- Distribuciones de Probabilidad ContinuaDocumento21 pagineDistribuciones de Probabilidad ContinuanikalmillateguiNessuna valutazione finora
- Distribucion Normal de ProbabilidadesDocumento38 pagineDistribucion Normal de ProbabilidadesANA GABRIELA LOPEZ PEREZNessuna valutazione finora
- U4 - Semana 15 - Distribución de Probabilidad Normal - EGDocumento25 pagineU4 - Semana 15 - Distribución de Probabilidad Normal - EGGeancarlo Cruz C.Nessuna valutazione finora
- 26-Clase 26 EM33 Distribución Normal 1Documento28 pagine26-Clase 26 EM33 Distribución Normal 1Camila Vásquez100% (1)
- Clase1. Aplicaciones de La Distribución NormalDocumento6 pagineClase1. Aplicaciones de La Distribución NormalAracely PinedaNessuna valutazione finora
- Distribucion de Probabilidad ContinuaDocumento14 pagineDistribucion de Probabilidad ContinuaBrayan PaezNessuna valutazione finora
- ETEA01 Unidad 2 Distribuciín de VAContinua-Normal 2.0Documento16 pagineETEA01 Unidad 2 Distribuciín de VAContinua-Normal 2.0Esteban ZapataNessuna valutazione finora
- Distribucion NormalDocumento12 pagineDistribucion NormalEstefania Cortes VargasNessuna valutazione finora
- Sesión 13Documento28 pagineSesión 13pierina floresNessuna valutazione finora
- Econometria - IDocumento16 pagineEconometria - IAlejandro S Figueroa AriasNessuna valutazione finora
- Comunicación Asertiva en La FamiliaDocumento8 pagineComunicación Asertiva en La FamiliaEdgar AguilarNessuna valutazione finora
- ESTILOS DE CRIANZA-tripticoDocumento3 pagineESTILOS DE CRIANZA-tripticoEdgar AguilarNessuna valutazione finora
- Test de Estilos de Aprendizaje Kolb FinalizadoDocumento3 pagineTest de Estilos de Aprendizaje Kolb Finalizadolaura valcarcel100% (2)
- El Psicólogo Educativo TripticoDocumento2 pagineEl Psicólogo Educativo TripticoEdgar AguilarNessuna valutazione finora
- Ejecución de Charlas PsicologícasDocumento36 pagineEjecución de Charlas PsicologícasEdgar AguilarNessuna valutazione finora
- Ejecución de Charlas PsicologícasDocumento36 pagineEjecución de Charlas PsicologícasEdgar AguilarNessuna valutazione finora
- Expo Miercoles Psicologico Exp. EducaDocumento40 pagineExpo Miercoles Psicologico Exp. EducaEdgar AguilarNessuna valutazione finora
- Prueba Adl Mae Primer GradoDocumento8 paginePrueba Adl Mae Primer GradoAngel Sarabia MorenoNessuna valutazione finora
- Diag-Org1 2Documento65 pagineDiag-Org1 2isabelNessuna valutazione finora
- Funcionesmentalessuperiores2 110817191723 Phpapp02Documento19 pagineFuncionesmentalessuperiores2 110817191723 Phpapp02Edgar AguilarNessuna valutazione finora
- Neuropsicologia en Trauma CranealDocumento14 pagineNeuropsicologia en Trauma CranealEdgar AguilarNessuna valutazione finora
- Picopatología Del Adulto.Documento11 paginePicopatología Del Adulto.Edgar AguilarNessuna valutazione finora
- Clasificacion Pruebas PsicologicasDocumento4 pagineClasificacion Pruebas PsicologicasEdgar AguilarNessuna valutazione finora
- Caso A.M.P.Documento22 pagineCaso A.M.P.Edgar AguilarNessuna valutazione finora
- Pip LaredoDocumento93 paginePip LaredoGonzalo Quispe ArangoitiaNessuna valutazione finora
- Desiciones GrupoDocumento11 pagineDesiciones GrupoEdgar AguilarNessuna valutazione finora
- Otto Kernberg EntrevistaDocumento6 pagineOtto Kernberg EntrevistaEdgar AguilarNessuna valutazione finora
- Casos CIe-10Documento64 pagineCasos CIe-10Hyuna Junni Joong78% (9)
- La Toma Dedecisiones en GrupoDocumento17 pagineLa Toma Dedecisiones en GrupoEdith JachoNessuna valutazione finora
- PromediosDocumento54 paginePromediosEdgar AguilarNessuna valutazione finora
- Qué Ha Escuchado Acerca Del Control de La NatalidadDocumento1 paginaQué Ha Escuchado Acerca Del Control de La NatalidadEdgar AguilarNessuna valutazione finora
- Teoria Del Establecimiento de Metas WordDocumento19 pagineTeoria Del Establecimiento de Metas WordIerzon CardenasNessuna valutazione finora
- Teorias Motivacionales Contemporaneas 2Documento10 pagineTeorias Motivacionales Contemporaneas 2Edgar AguilarNessuna valutazione finora
- Manual de Organización y Funciones (Mof)Documento55 pagineManual de Organización y Funciones (Mof)Richard Ramos CutimboNessuna valutazione finora
- 20160602180611Documento89 pagine20160602180611Edgar Aguilar0% (1)
- CorrB Prevencion CEnDHIUSept 12Documento20 pagineCorrB Prevencion CEnDHIUSept 12Edgar AguilarNessuna valutazione finora
- Tema 08Documento18 pagineTema 08Lorena Olazabal ValeraNessuna valutazione finora
- 4.1 Guía - Nonormal - Wilcoxon - Suma - Rangos - EpapDocumento22 pagine4.1 Guía - Nonormal - Wilcoxon - Suma - Rangos - EpapJosez A. DasNessuna valutazione finora
- Taller de Estadistica Inferencial 2020Documento7 pagineTaller de Estadistica Inferencial 2020Moises Castro MejiaNessuna valutazione finora
- Portafolio EstadisticaDocumento17 paginePortafolio EstadisticaRobertoPalaciosNessuna valutazione finora
- Intervalo y Prueba de Hipótesis para Diferencia de Dos Medias Muestras No RelacionadasDocumento23 pagineIntervalo y Prueba de Hipótesis para Diferencia de Dos Medias Muestras No RelacionadasMorayma lloja fernandezNessuna valutazione finora
- Actividad 6 Taller Pruebas de HipótesisDocumento21 pagineActividad 6 Taller Pruebas de HipótesisCaroNessuna valutazione finora
- Hidraulica Fluvial 2018-IDocumento102 pagineHidraulica Fluvial 2018-IDarwin Palma TafurNessuna valutazione finora
- Tablas Z y T-Student PDFDocumento3 pagineTablas Z y T-Student PDFHiraikHimura50% (2)
- TALLER DE MANTENIMIENTO WeilbullDocumento12 pagineTALLER DE MANTENIMIENTO WeilbullJuan David Sandoval HerreraNessuna valutazione finora
- Evaluacion Final - Escenario 8 Primer Bloque-Ciencias Basicas - Virtual - Probabilidad - (Grupo b08)Documento7 pagineEvaluacion Final - Escenario 8 Primer Bloque-Ciencias Basicas - Virtual - Probabilidad - (Grupo b08)Elver SuárezNessuna valutazione finora
- ETS Bioestadística QFI - Vesp Julio 2021Documento2 pagineETS Bioestadística QFI - Vesp Julio 2021Martha Lidia Perez VazquezNessuna valutazione finora
- Recup. Parcial2Documento18 pagineRecup. Parcial2autobakery0% (1)
- Cap 12. Genetica CuantitativaDocumento60 pagineCap 12. Genetica CuantitativaVanessa MelendezNessuna valutazione finora
- Trabajo Final de EstadísticaDocumento72 pagineTrabajo Final de EstadísticaFidel Vargas ManzurNessuna valutazione finora
- Distribucion T de StudentDocumento5 pagineDistribucion T de StudentJuly Sofia Rojas100% (1)
- Simulacion Gerencial 2018-2Documento161 pagineSimulacion Gerencial 2018-2Luz Vasquez Vasquez Garcia100% (1)
- Control Estadistico de ProcesosDocumento41 pagineControl Estadistico de ProcesosPaul NarvaezNessuna valutazione finora
- Programas Examen de Grado ICODocumento47 pagineProgramas Examen de Grado ICORodrigo CopariNessuna valutazione finora
- Foro Distribución de La Probabilidad NormalDocumento4 pagineForo Distribución de La Probabilidad Normalpaula villamilNessuna valutazione finora
- Metodos Numericos (Tarea1)Documento9 pagineMetodos Numericos (Tarea1)Melissa CardozoNessuna valutazione finora
- Cuerpo Superior de Actuarios, Estadísticos y EconomistasDocumento21 pagineCuerpo Superior de Actuarios, Estadísticos y EconomistasTony PignoliNessuna valutazione finora
- 01 - Analisis ExploratorioDocumento88 pagine01 - Analisis ExploratorioRhommelllNessuna valutazione finora
- APUNTE Y GUIA EJERCICIOS NORMAL InacapDocumento11 pagineAPUNTE Y GUIA EJERCICIOS NORMAL InacapfranciscoptNessuna valutazione finora
- Analísis Multifractal para La Interpretación de DatosDocumento3 pagineAnalísis Multifractal para La Interpretación de DatoseloNessuna valutazione finora
- Statistical Reports 452022Documento25 pagineStatistical Reports 452022Hannah JanawaNessuna valutazione finora
- CigarrillosDocumento11 pagineCigarrillosElkin RamirezNessuna valutazione finora
- Teorema Del Límite Central y Estimación de IntervalosDocumento21 pagineTeorema Del Límite Central y Estimación de IntervalosEdwin Gómez100% (2)
- Tercer Trayecto NuevoDocumento45 pagineTercer Trayecto NuevoJulissa EscalonaNessuna valutazione finora
- Estadisticas en MantenimientoDocumento15 pagineEstadisticas en MantenimientoRoberto Polo Timoteo0% (1)