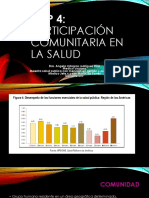
Potrebbero piacerti anche
- Guía de Valoración de Enfermería Según Patrones Funcionales de Marjory GordonDocumento16 pagineGuía de Valoración de Enfermería Según Patrones Funcionales de Marjory GordonFanny Rodriguez100% (1)
- Índice Papilar Marginal AdheridaDocumento5 pagineÍndice Papilar Marginal AdheridaValencia Hernandez Karla MercedesNessuna valutazione finora
- Fesp 4Documento36 pagineFesp 4Guillermo Ruiz CabreraNessuna valutazione finora
- Indicadores de Salud 2Documento32 pagineIndicadores de Salud 2Samari MacielNessuna valutazione finora
- 2.epidemiologia DescriptivaDocumento13 pagine2.epidemiologia DescriptivaAnghela Stana100% (1)
- Valores Normales TemperaturaDocumento2 pagineValores Normales TemperaturaPaoliita Hernandez82% (11)
- Conceptos Basicos de EpidemiologiaDocumento17 pagineConceptos Basicos de EpidemiologiaKari Janet Fabian Castro0% (1)
- Bacterias Que Afectan El Sistema DigestivoDocumento26 pagineBacterias Que Afectan El Sistema Digestivopixmar0% (3)
- Tríada Ecológica y Cadena EpidemiológicaDocumento10 pagineTríada Ecológica y Cadena EpidemiológicaLuz Cristina Armenta GaleanaNessuna valutazione finora
- Caso ClinicoDocumento13 pagineCaso ClinicoMarco SarmientoNessuna valutazione finora
- Indicadores Epidemiologicos Tasas ProporcionesDocumento32 pagineIndicadores Epidemiologicos Tasas ProporcionesRoberto DacuñaNessuna valutazione finora
- Sistema de Salud SuizoDocumento11 pagineSistema de Salud Suizodavid morenoNessuna valutazione finora
- Metodos Estadisticos Población y MuestraDocumento18 pagineMetodos Estadisticos Población y MuestraJohana Rojas100% (1)
- ENFERMERIADocumento14 pagineENFERMERIAmariaNessuna valutazione finora
- Tasas EpidemiologicasDocumento55 pagineTasas EpidemiologicasDiego Gomez Aburto100% (1)
- Diez Principales Causas de Morbilidad Ecuador A o 2007Documento32 pagineDiez Principales Causas de Morbilidad Ecuador A o 2007Mariadelcarmen Gangotena Guarderas100% (3)
- Canal EndemicoDocumento17 pagineCanal EndemicoVictor Gustavo Arias LedesmaNessuna valutazione finora
- Mecanismos de Transporte de Principios Activos A Través de Membranas Biológicas PDFDocumento16 pagineMecanismos de Transporte de Principios Activos A Través de Membranas Biológicas PDFIñaki DuBa100% (1)
- Morbilidad SPDocumento43 pagineMorbilidad SPandreaspm100% (1)
- Laboratorio N°4Documento5 pagineLaboratorio N°4Melissa Blas Cueva0% (1)
- Reporte de CasoDocumento6 pagineReporte de CasoRaquel YaxNessuna valutazione finora
- CAPURRO, Silverman Anderson y ApgarDocumento3 pagineCAPURRO, Silverman Anderson y ApgarMariel Castro100% (1)
- Teoria D. OremDocumento28 pagineTeoria D. OremMuhammadYahirNessuna valutazione finora
- s7 - Epidemiologia - Ejercicios de Sensibilidad y EspecificidadDocumento5 pagines7 - Epidemiologia - Ejercicios de Sensibilidad y EspecificidadValeria CajigasNessuna valutazione finora
- Fisiologia de Liquidos y Electrolitos I 2014Documento61 pagineFisiologia de Liquidos y Electrolitos I 2014HeberCoilaNessuna valutazione finora
- 3 - Manejo de Brote EpidémicoDocumento28 pagine3 - Manejo de Brote EpidémicoRaulNessuna valutazione finora
- Banco de Salud Pública (2) Banco de Salud PúblicaDocumento220 pagineBanco de Salud Pública (2) Banco de Salud PúblicaYislenNessuna valutazione finora
- Osmolaridad de Las Soluciones Parenterales 2021Documento3 pagineOsmolaridad de Las Soluciones Parenterales 2021Daysi Alejandra Molina BonillaNessuna valutazione finora
- Guía de Estudio Cálculo de DosisDocumento8 pagineGuía de Estudio Cálculo de DosisAlexander León PuelloNessuna valutazione finora
- Medidas EpidemiológicasDocumento62 pagineMedidas EpidemiológicasDominique Maret88% (16)
- Formato de Practicas Sonda VesicalDocumento7 pagineFormato de Practicas Sonda VesicalKalef T. ManceroNessuna valutazione finora
- Presentación Tipos de Estudios en EpidemiologìaDocumento42 paginePresentación Tipos de Estudios en EpidemiologìaSofía trujillo100% (1)
- Prerrequisitos para El Diseño de Un Programa de Salud Elaboración y La Implementación de Los ProgramasDocumento10 paginePrerrequisitos para El Diseño de Un Programa de Salud Elaboración y La Implementación de Los ProgramasDOMENICA HERNANDEZNessuna valutazione finora
- Ficha HeridasDocumento2 pagineFicha HeridasRhafa ChelNessuna valutazione finora
- Trastornos InmunológicosDocumento7 pagineTrastornos InmunológicosSofia Betancourt0% (1)
- 7-Práctica MuestreoDocumento6 pagine7-Práctica MuestreoJHINA NATALI VASQUEZ SILVANessuna valutazione finora
- Causalidad en Epidemiología. Espinoza-Carrillo PDFDocumento41 pagineCausalidad en Epidemiología. Espinoza-Carrillo PDFMiguel Espinoza CarrilloNessuna valutazione finora
- Factores Estimuladores de ColoniasDocumento2 pagineFactores Estimuladores de ColoniasMiguelMp100% (1)
- SomatometriaDocumento20 pagineSomatometriaBrenda UresteeNessuna valutazione finora
- Vigilancia EpidemiologicaDocumento9 pagineVigilancia EpidemiologicaCarlos02bassNessuna valutazione finora
- Metodo EpidemiologicoDocumento20 pagineMetodo Epidemiologicoapi-26467068100% (5)
- Etnografía - Santa MariaDocumento5 pagineEtnografía - Santa MariaGise VillaNessuna valutazione finora
- UrocultivoDocumento20 pagineUrocultivoKarina Andrea Peña MoyaNessuna valutazione finora
- Estudios EcologicosDocumento37 pagineEstudios EcologicosAlexis Antiñanco MansillaNessuna valutazione finora
- Ejercicios de Riesgo AtribuibleDocumento2 pagineEjercicios de Riesgo Atribuibleheydi100% (1)
- Epidemiologia Cadena EpidemiologicaDocumento58 pagineEpidemiologia Cadena EpidemiologicaJenny AnchiraicoNessuna valutazione finora
- Clase 5. Cadena EpidemiologicaDocumento41 pagineClase 5. Cadena EpidemiologicaDra Arce GranadosNessuna valutazione finora
- Conceptos Básicos en EpidemiologíaDocumento31 pagineConceptos Básicos en EpidemiologíaMaria Paulina0% (1)
- DX Por DominiosDocumento18 pagineDX Por DominiosnataliaNessuna valutazione finora
- Taller de EstadisticaDocumento8 pagineTaller de EstadisticaJORGE DURANNessuna valutazione finora
- Historia de La Epidemiologia-DiaposDocumento18 pagineHistoria de La Epidemiologia-DiaposMaRy Condori100% (1)
- Guía de Entrevista - Salud PúblicaDocumento13 pagineGuía de Entrevista - Salud PúblicaCezia RiosNessuna valutazione finora
- 8-Estimación de ParámetrosDocumento3 pagine8-Estimación de ParámetrosRonald VeramendiNessuna valutazione finora
- Examen Final Epidemiologia Harold - IbarraDocumento6 pagineExamen Final Epidemiologia Harold - IbarraHarold IbarraNessuna valutazione finora
- Codigo de Conducta para El Personal de SaludDocumento2 pagineCodigo de Conducta para El Personal de SaludCynthia GonzálezNessuna valutazione finora
- A#6 Ejercicios Epidemiologia y BioestadísticaDocumento9 pagineA#6 Ejercicios Epidemiologia y BioestadísticaJose BadilloNessuna valutazione finora
- Cuadernillo Guia de Ejercicios de Proceso Enfermero 1 PDFDocumento3 pagineCuadernillo Guia de Ejercicios de Proceso Enfermero 1 PDFDaniel Hernández BarreraNessuna valutazione finora
- BioestadísticaDocumento3 pagineBioestadísticaDavid Palacios IngaNessuna valutazione finora
- Ensayo de Enfoques Epidemiológicos 1Documento4 pagineEnsayo de Enfoques Epidemiológicos 1Dayanara Rodriguez50% (2)
- SCF III - Actividad Orientadora 10Documento8 pagineSCF III - Actividad Orientadora 10ElyYTNessuna valutazione finora
- 4.3 TaquiarritmiasDocumento3 pagine4.3 TaquiarritmiasAlonso Marcelo Herrera VarasNessuna valutazione finora
- 4.1 ElectrocardiogramaDocumento3 pagine4.1 ElectrocardiogramaAlonso Marcelo Herrera VarasNessuna valutazione finora
- 4.2 BradiarritmiasDocumento3 pagine4.2 BradiarritmiasAlonso Marcelo Herrera VarasNessuna valutazione finora
- 3.2 IAM Sin Supradesnivel Del STDocumento2 pagine3.2 IAM Sin Supradesnivel Del STAlonso Marcelo Herrera VarasNessuna valutazione finora
- 4.3 TaquiarritmiasDocumento2 pagine4.3 TaquiarritmiasAlonso Marcelo Herrera VarasNessuna valutazione finora
- Hipertensión ArterialDocumento4 pagineHipertensión ArterialAlonso Marcelo Herrera VarasNessuna valutazione finora
- Síndrome Aórtico AgudoDocumento3 pagineSíndrome Aórtico AgudoAlonso Marcelo Herrera VarasNessuna valutazione finora
- 4 Reanimación Con Líquidos Guiadas Por ProtocolosDocumento32 pagine4 Reanimación Con Líquidos Guiadas Por ProtocolosAlonso Marcelo Herrera VarasNessuna valutazione finora
- MATTERs Tranexamico HenorragiaDocumento3 pagineMATTERs Tranexamico HenorragiaAlonso Marcelo Herrera VarasNessuna valutazione finora
- Síndrome Coronario AgudoDocumento2 pagineSíndrome Coronario AgudoAlonso Marcelo Herrera VarasNessuna valutazione finora
- Dolor Torácico en UrgenciasDocumento3 pagineDolor Torácico en UrgenciasAlonso Marcelo Herrera VarasNessuna valutazione finora
- Wernicke Encephalopathy - UpToDateDocumento16 pagineWernicke Encephalopathy - UpToDateAlonso Marcelo Herrera VarasNessuna valutazione finora
- Circular 2010Documento26 pagineCircular 2010Alonso Marcelo Herrera VarasNessuna valutazione finora
- Estudios Descriptivos Pruebas DiagnósticasDocumento29 pagineEstudios Descriptivos Pruebas DiagnósticasAlonso Marcelo Herrera Varas0% (1)
- Respirador Reutilizable Con FiltroDocumento3 pagineRespirador Reutilizable Con FiltroAlonso Marcelo Herrera VarasNessuna valutazione finora
- Acido Base - AbordajeDocumento3 pagineAcido Base - AbordajeAlonso Marcelo Herrera VarasNessuna valutazione finora
- 4-Apuntes PeritoneoDocumento10 pagine4-Apuntes PeritoneoAlonso Marcelo Herrera VarasNessuna valutazione finora
- Estudios EcologicosDocumento17 pagineEstudios EcologicosAlonso Marcelo Herrera VarasNessuna valutazione finora
- Estudios PrevalenciaDocumento7 pagineEstudios PrevalenciaAlonso Marcelo Herrera VarasNessuna valutazione finora
- Resumen Gine EscencialDocumento39 pagineResumen Gine EscencialAlonso Marcelo Herrera VarasNessuna valutazione finora
- Aprendizaje AutomáticoDocumento2 pagineAprendizaje AutomáticoJacqueline González ANessuna valutazione finora
- Expresiones y OperadoresDocumento16 pagineExpresiones y Operadores007skyline001Nessuna valutazione finora
- Actividad Propuesta Sobre Simuladores FinancierosDocumento15 pagineActividad Propuesta Sobre Simuladores FinancierosMaría Catalina Cata Morales GalindoNessuna valutazione finora
- Cristo Hoy - El Criterio de Credibilidad y El Don de La Fe (Fernando Rielo)Documento46 pagineCristo Hoy - El Criterio de Credibilidad y El Don de La Fe (Fernando Rielo)Rodolfo Bustos Vera85% (13)
- Unidad 2 Inventarios - Demanda Dependiente MRP PDFDocumento34 pagineUnidad 2 Inventarios - Demanda Dependiente MRP PDFLaura Daniela CardonaNessuna valutazione finora
- Tema 2 Tablas de Distribucion de Frecuencia (Una Dos o Multiples EntradasDocumento27 pagineTema 2 Tablas de Distribucion de Frecuencia (Una Dos o Multiples EntradasClau GNessuna valutazione finora
- Arturo Saravia CVDocumento3 pagineArturo Saravia CVRuben Samanamud NatividadNessuna valutazione finora
- Diagrama de Momento Flector y de Fuerza CortanteDocumento14 pagineDiagrama de Momento Flector y de Fuerza CortanteJose Llanco SantosNessuna valutazione finora
- Taller CompiladoresDocumento6 pagineTaller CompiladoresJuan MontesNessuna valutazione finora
- Diccionario de Mineria Ingles-EspañolDocumento677 pagineDiccionario de Mineria Ingles-EspañolDulcinea del Toboso80% (5)
- Rayo Torres TelecomDocumento22 pagineRayo Torres TelecomJuan Cristóbal Rivera PuellesNessuna valutazione finora
- Didactica de La Matematica-Rico Modesto CastroDocumento1 paginaDidactica de La Matematica-Rico Modesto Castrocarlos gustavo castro ossaNessuna valutazione finora
- Figuración de Sucesiones NuméricasDocumento13 pagineFiguración de Sucesiones NuméricasRodrigo Sancho PaezNessuna valutazione finora
- Poligonal Cerrada...Documento12 paginePoligonal Cerrada...Marco JaramilloNessuna valutazione finora
- Algebra Lineal Matrices.Documento103 pagineAlgebra Lineal Matrices.Junior T FarroñayNessuna valutazione finora
- Tarea 1.1 EcuaDocumento3 pagineTarea 1.1 EcuaMAURICIO GABRIEL CANUL POOTNessuna valutazione finora
- ProgLF U2 A1 Eq8Documento12 pagineProgLF U2 A1 Eq8yessenia rodriguezNessuna valutazione finora
- Funciones en La Vida CotidianaDocumento5 pagineFunciones en La Vida CotidianaSteffany RicaurteNessuna valutazione finora
- 08-Torres y Condensadores 2019Documento30 pagine08-Torres y Condensadores 2019Rodrigo Civetta MartinezNessuna valutazione finora
- Informe#1 LEIII Grupo1Documento29 pagineInforme#1 LEIII Grupo1Juliana BricenoNessuna valutazione finora
- PEC - Desarrollo II Resuelta PontevedraDocumento12 paginePEC - Desarrollo II Resuelta PontevedraLuis Fernando García RodriguezNessuna valutazione finora
- Ensayo SIMCE (6° Básico)Documento4 pagineEnsayo SIMCE (6° Básico)Elcira Alejandra Jaque JaqueNessuna valutazione finora
- DocxDocumento13 pagineDocxSebastian PaucarNessuna valutazione finora
- Clase 4. Criterios de Clasificacion Del Movimiento de Los Fluidos PDFDocumento21 pagineClase 4. Criterios de Clasificacion Del Movimiento de Los Fluidos PDFLuis Briones RNessuna valutazione finora
- Balanza y Mat VolumétricoDocumento5 pagineBalanza y Mat VolumétricopacocurroNessuna valutazione finora
- 03 - Definición de Unidades GeologicasDocumento16 pagine03 - Definición de Unidades GeologicasBrayan Javier CalleNessuna valutazione finora
- Informe Final Analisis Nodal CompletoDocumento20 pagineInforme Final Analisis Nodal CompletoING.PET100% (1)
- 01 Sistema de NumeracionDocumento8 pagine01 Sistema de NumeracionM23PNessuna valutazione finora
- Práctica 4 Equilibrio de Fuerzas CoplanaresDocumento11 paginePráctica 4 Equilibrio de Fuerzas CoplanaresAmelia Ortiz MolanoNessuna valutazione finora
- 2 DaDocumento3 pagine2 Dacolber jalisto huamaniNessuna valutazione finora