Potrebbero piacerti anche
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- VP Construction Real Estate Development in NY NJ Resume Edward CondolonDocumento4 pagineVP Construction Real Estate Development in NY NJ Resume Edward CondolonEdwardCondolonNessuna valutazione finora
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- TT Class XII PDFDocumento96 pagineTT Class XII PDFUday Beer100% (2)
- Concrete For Water StructureDocumento22 pagineConcrete For Water StructureIntan MadiaaNessuna valutazione finora
- Preventing OOS DeficienciesDocumento65 paginePreventing OOS Deficienciesnsk79in@gmail.comNessuna valutazione finora
- We Move You. With Passion.: YachtDocumento27 pagineWe Move You. With Passion.: YachthatelNessuna valutazione finora
- Binder 1Documento107 pagineBinder 1Ana Maria Gálvez Velasquez0% (1)
- Sacmi Vol 2 Inglese - II EdizioneDocumento416 pagineSacmi Vol 2 Inglese - II Edizionecuibaprau100% (21)
- Heat TreatmentsDocumento14 pagineHeat Treatmentsravishankar100% (1)
- Symposium: Vitamin D Insufficiency: A Significant Risk Factor in Chronic Diseases and Potential Disease-Specific Biomarkers of Vitamin D SufficiencyDocumento6 pagineSymposium: Vitamin D Insufficiency: A Significant Risk Factor in Chronic Diseases and Potential Disease-Specific Biomarkers of Vitamin D SufficiencyYofa SukmawatiNessuna valutazione finora
- Menopause and The Cardiovascular System: Pamela Ouyang, M.DDocumento3 pagineMenopause and The Cardiovascular System: Pamela Ouyang, M.DYofa SukmawatiNessuna valutazione finora
- 8.4 Varicocele 8.4.1 PathophysiologyDocumento5 pagine8.4 Varicocele 8.4.1 PathophysiologyYofa SukmawatiNessuna valutazione finora
- Views: Serious Shopping: Essays in Psychotherapy and ConsumerismDocumento4 pagineViews: Serious Shopping: Essays in Psychotherapy and ConsumerismYofa SukmawatiNessuna valutazione finora
- CSA Report Fahim Final-1Documento10 pagineCSA Report Fahim Final-1Engr Fahimuddin QureshiNessuna valutazione finora
- Dmta 20043 01en Omniscan SX UserDocumento90 pagineDmta 20043 01en Omniscan SX UserwenhuaNessuna valutazione finora
- Life Cycle Cost Analysis of Hvac System in Office ProjectsDocumento3 pagineLife Cycle Cost Analysis of Hvac System in Office ProjectsVashuka GhritlahreNessuna valutazione finora
- BMT6138 Advanced Selling and Negotiation Skills: Digital Assignment-1Documento9 pagineBMT6138 Advanced Selling and Negotiation Skills: Digital Assignment-1Siva MohanNessuna valutazione finora
- Bba Colleges in IndiaDocumento7 pagineBba Colleges in IndiaSumit GuptaNessuna valutazione finora
- Introduction Into Post Go-Live SizingsDocumento26 pagineIntroduction Into Post Go-Live SizingsCiao BentosoNessuna valutazione finora
- Kicks: This Brochure Reflects The Product Information For The 2020 Kicks. 2021 Kicks Brochure Coming SoonDocumento8 pagineKicks: This Brochure Reflects The Product Information For The 2020 Kicks. 2021 Kicks Brochure Coming SoonYudyChenNessuna valutazione finora
- XI STD Economics Vol-1 EM Combined 12.10.18 PDFDocumento288 pagineXI STD Economics Vol-1 EM Combined 12.10.18 PDFFebin Kurian Francis0% (1)
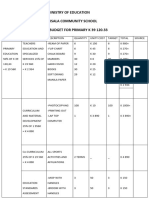
- Ministry of Education Musala SCHDocumento5 pagineMinistry of Education Musala SCHlaonimosesNessuna valutazione finora
- tdr100 - DeviceDocumento4 paginetdr100 - DeviceSrđan PavićNessuna valutazione finora
- Bank Statement SampleDocumento6 pagineBank Statement SampleRovern Keith Oro CuencaNessuna valutazione finora
- Tindara Addabbo, Edoardo Ales, Ylenia Curzi, Tommaso Fabbri, Olga Rymkevich, Iacopo Senatori - Performance Appraisal in Modern Employment Relations_ An Interdisciplinary Approach-Springer Internationa.pdfDocumento278 pagineTindara Addabbo, Edoardo Ales, Ylenia Curzi, Tommaso Fabbri, Olga Rymkevich, Iacopo Senatori - Performance Appraisal in Modern Employment Relations_ An Interdisciplinary Approach-Springer Internationa.pdfMario ChristopherNessuna valutazione finora
- Accounting II SyllabusDocumento4 pagineAccounting II SyllabusRyan Busch100% (2)
- PanasonicDocumento35 paginePanasonicAsif Shaikh0% (1)
- TP1743 - Kertas 1 Dan 2 Peperiksaan Percubaan SPM Sains 2023-20243Documento12 pagineTP1743 - Kertas 1 Dan 2 Peperiksaan Percubaan SPM Sains 2023-20243Felix ChewNessuna valutazione finora
- Caso Kola RealDocumento17 pagineCaso Kola RealEvelyn Dayhanna Escobar PalomequeNessuna valutazione finora
- Tenancy Law ReviewerDocumento19 pagineTenancy Law ReviewerSef KimNessuna valutazione finora
- LT1256X1 - Revg - FB1300, FB1400 Series - EnglishDocumento58 pagineLT1256X1 - Revg - FB1300, FB1400 Series - EnglishRahma NaharinNessuna valutazione finora
- Entrep Q4 - Module 7Documento5 pagineEntrep Q4 - Module 7Paula DT PelitoNessuna valutazione finora
- Sealant Solutions: Nitoseal Thioflex FlamexDocumento16 pagineSealant Solutions: Nitoseal Thioflex FlamexBhagwat PatilNessuna valutazione finora
- DT2 (80 82)Documento18 pagineDT2 (80 82)Anonymous jbeHFUNessuna valutazione finora
- COGELSA Food Industry Catalogue LDDocumento9 pagineCOGELSA Food Industry Catalogue LDandriyanto.wisnuNessuna valutazione finora