Potrebbero piacerti anche
- Lecture 11 Programming On Gpus Part 1 Zxu2acms60212 40212 S15lec 11 GpupdfDocumento121 pagineLecture 11 Programming On Gpus Part 1 Zxu2acms60212 40212 S15lec 11 Gpupdfeipu tuNessuna valutazione finora
- Lecture12 GPUArchCUDA02-CUDAMemDocumento67 pagineLecture12 GPUArchCUDA02-CUDAMemMichelle SaverNessuna valutazione finora
- CUDA Programming Basic: High Performance Computing Center Hanoi University of Science & TechnologyDocumento38 pagineCUDA Programming Basic: High Performance Computing Center Hanoi University of Science & TechnologyMato NguyễnNessuna valutazione finora
- Josh CudaDocumento27 pagineJosh CudaRamuNessuna valutazione finora
- Introduction To CUDA: CAP 4730 Spring 2012Documento35 pagineIntroduction To CUDA: CAP 4730 Spring 2012Manvendra Singh ChhajerhNessuna valutazione finora
- Cuda TalkDocumento82 pagineCuda TalkKevin Salmeron Vicente100% (1)
- Intro 2 CudaDocumento30 pagineIntro 2 Cudaab cNessuna valutazione finora
- CudaDocumento44 pagineCudaavinash kumarNessuna valutazione finora
- Cuda Review 1Documento13 pagineCuda Review 1JESSEMANNessuna valutazione finora
- CUDADocumento33 pagineCUDAravish177Nessuna valutazione finora
- Gpu History and Cuda Programming BasicsDocumento44 pagineGpu History and Cuda Programming BasicsFransiskus Yoga Esa WibowoNessuna valutazione finora
- Programming Gpus With Cuda: John Mellor-CrummeyDocumento42 pagineProgramming Gpus With Cuda: John Mellor-CrummeyaskbilladdmicrosoftNessuna valutazione finora
- Cuda ContDocumento29 pagineCuda Contunknown0801Nessuna valutazione finora
- 217 Lec2Documento24 pagine217 Lec2palashNessuna valutazione finora
- GPGPU Programming With CUDA: Leandro Avila - University of Northern IowaDocumento29 pagineGPGPU Programming With CUDA: Leandro Avila - University of Northern IowaXafran KhanNessuna valutazione finora
- Introduction To Gpu Programming With Cuda and OpenaccDocumento40 pagineIntroduction To Gpu Programming With Cuda and OpenaccplopNessuna valutazione finora
- Introduction To Programming Massively Parallel Graphics ProcessorsDocumento84 pagineIntroduction To Programming Massively Parallel Graphics ProcessorsdjriveNessuna valutazione finora
- Recipe For Running Simple CUDA Code On A GPU Based Rocks ClusterDocumento17 pagineRecipe For Running Simple CUDA Code On A GPU Based Rocks Clusterproxymo1Nessuna valutazione finora
- 8 Cud A 1Documento38 pagine8 Cud A 1Aashish MittalNessuna valutazione finora
- L2: Introduction To Cuda: January 14, 2009Documento27 pagineL2: Introduction To Cuda: January 14, 2009JM MejiaNessuna valutazione finora
- лк CUDA - 1 PDCnDocumento31 pagineлк CUDA - 1 PDCnОлеся БарковськаNessuna valutazione finora
- Cuda EmulatorDocumento7 pagineCuda EmulatorMidhun Pal CochinNessuna valutazione finora
- Pgi Cuda TutorialDocumento58 paginePgi Cuda TutorialMaziar IraniNessuna valutazione finora
- Group A Assignment 4 (A) : Two Large VectorsDocumento5 pagineGroup A Assignment 4 (A) : Two Large VectorsNayan JadhavNessuna valutazione finora
- Module 3.1 - CUDA Parallelism Model: GPU Teaching KitDocumento44 pagineModule 3.1 - CUDA Parallelism Model: GPU Teaching Kityassin mechbalNessuna valutazione finora
- Parralel Demro 001Documento45 pagineParralel Demro 001demro channelNessuna valutazione finora
- CUDA Programming: Lei Zhou, Yafeng Yin, Yanzhi Ren, Hong Man, Yingying ChenDocumento28 pagineCUDA Programming: Lei Zhou, Yafeng Yin, Yanzhi Ren, Hong Man, Yingying ChenChaitanya NirfarakeNessuna valutazione finora
- GPUMod 2Documento64 pagineGPUMod 2Disinlung Kamei DisinlungNessuna valutazione finora
- An Introduction To PyCUDA Using Prefix Sum Algorithm PDFDocumento6 pagineAn Introduction To PyCUDA Using Prefix Sum Algorithm PDFjackopsNessuna valutazione finora
- Unit 6 Chapter 1 Parallel Programming Tools Cuda - ProgrammingDocumento28 pagineUnit 6 Chapter 1 Parallel Programming Tools Cuda - ProgrammingPallavi BhartiNessuna valutazione finora
- High Performance Computing On GpuDocumento37 pagineHigh Performance Computing On GpuSushant SharmaNessuna valutazione finora
- CUDA IntroductionDocumento71 pagineCUDA IntroductionSiddu S. KamatarNessuna valutazione finora
- CS 179: GPU Computing: Lecture 2: More BasicsDocumento23 pagineCS 179: GPU Computing: Lecture 2: More BasicsRajulNessuna valutazione finora
- cs179 2017 Lec01Documento24 paginecs179 2017 Lec01RajulNessuna valutazione finora
- Cuda C/C++ Basics: NVIDIA CorporationDocumento67 pagineCuda C/C++ Basics: NVIDIA Corporationrj jNessuna valutazione finora
- Debugging The Linux Kernel With GDBDocumento40 pagineDebugging The Linux Kernel With GDBtedy58Nessuna valutazione finora
- Nvidia CudaDocumento26 pagineNvidia CudaArpit VijayvergiaNessuna valutazione finora
- OpenCL GuideDocumento19 pagineOpenCL GuideAmafro LopezNessuna valutazione finora
- Cuda CDocumento70 pagineCuda CSwati ChoudharyNessuna valutazione finora
- NNSW ToolsDocumento39 pagineNNSW ToolsFernando CisnerosNessuna valutazione finora
- Intro To CUDADocumento76 pagineIntro To CUDADisinlung Kamei DisinlungNessuna valutazione finora
- 06-Intro To Opencl PDFDocumento57 pagine06-Intro To Opencl PDFKshitija SahaniNessuna valutazione finora
- HPC 4 BDocumento5 pagineHPC 4 BNayan JadhavNessuna valutazione finora
- 002 - Introduction To CUDA Programming - 1Documento54 pagine002 - Introduction To CUDA Programming - 1Vinod VMNessuna valutazione finora
- Barnett HaskinsDocumento29 pagineBarnett HaskinsCristi Alexandru VasileNessuna valutazione finora
- Extreme Computing: Advanced CUDA Part 3Documento27 pagineExtreme Computing: Advanced CUDA Part 3Adr IabNessuna valutazione finora
- 3 Some Commonly Used CUDA API: 3.1 Function Type QualifiersDocumento7 pagine3 Some Commonly Used CUDA API: 3.1 Function Type QualifiersMuhammad AzmatNessuna valutazione finora
- Lecture 2Documento77 pagineLecture 2raghunaathNessuna valutazione finora
- Gpu ProgrammingDocumento96 pagineGpu ProgrammingJino Goju Stark100% (2)
- A Beginner'S Guide To Programming Gpus With Cuda: Mike PeardonDocumento21 pagineA Beginner'S Guide To Programming Gpus With Cuda: Mike Peardonproxymo1Nessuna valutazione finora
- Class4 Advanced Cuda OpenclDocumento64 pagineClass4 Advanced Cuda OpenclCarlangaslangasNessuna valutazione finora
- Matrix MultDocumento55 pagineMatrix Multsundeepadapa100% (1)
- The Evolution of Gpus For General Purpose ComputingDocumento38 pagineThe Evolution of Gpus For General Purpose ComputingsufikasihNessuna valutazione finora
- Chap7 CUDA IntroDocumento63 pagineChap7 CUDA IntroMichael ShiNessuna valutazione finora
- OPENMP NotesDocumento4 pagineOPENMP Notesavinash kumarNessuna valutazione finora
- cs179 2016 Lec13Documento30 paginecs179 2016 Lec13RajulNessuna valutazione finora
- Cuda ExamplesDocumento28 pagineCuda ExamplesRiccardo FerreroNessuna valutazione finora
- Introduccion CUDA CDocumento51 pagineIntroduccion CUDA CEric LilloNessuna valutazione finora
- PLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.Da EverandPLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.Nessuna valutazione finora
- MSTeams Diagnostics Log 17 - 8 - 2023 - 20 - 21 - 02 - Experience - RendererDocumento24 pagineMSTeams Diagnostics Log 17 - 8 - 2023 - 20 - 21 - 02 - Experience - RendererROBERTO CARLOS MONTESINOS TRUJILLONessuna valutazione finora
- Wa0004.Documento7 pagineWa0004.Mohan RajNessuna valutazione finora
- The Noob Guide For HackingDocumento6 pagineThe Noob Guide For HackingKimCarloMiraCortezNessuna valutazione finora
- 0 Dumpacore 3rd Com - Samsung.android - App.contactsDocumento253 pagine0 Dumpacore 3rd Com - Samsung.android - App.contactsSolo VictorNessuna valutazione finora
- Tia Portal V16 OrderlistDocumento7 pagineTia Portal V16 OrderlistJahidul IslamNessuna valutazione finora
- DotMAP120 User Manual enDocumento122 pagineDotMAP120 User Manual enpham linhNessuna valutazione finora
- Using Xperfinfo and XperfDocumento59 pagineUsing Xperfinfo and Xperfteamfox201Nessuna valutazione finora
- GRC12 Access ControlDocumento262 pagineGRC12 Access ControlalNessuna valutazione finora
- Introduction To Software EngineeringDocumento25 pagineIntroduction To Software EngineeringAayush MalikNessuna valutazione finora
- Introduction ToDocumento302 pagineIntroduction ToJohn Paul Anthony ArlosNessuna valutazione finora
- Three Generations of SCADA System ArchitecturesDocumento5 pagineThree Generations of SCADA System Architecturesjob_pNessuna valutazione finora
- Sample StoryDocumento2 pagineSample StoryLara Mae Gonzales100% (1)
- Snow SAP OptimizerDocumento4 pagineSnow SAP OptimizerCastNessuna valutazione finora
- Week 5 DiscussionDocumento38 pagineWeek 5 DiscussionSiri Varshitha Reddy LingareddyNessuna valutazione finora
- Materi Search EngineDocumento25 pagineMateri Search EngineGusti RahmadiNessuna valutazione finora
- HP A3 Colour MFP E78223Documento6 pagineHP A3 Colour MFP E78223bengkel_ericNessuna valutazione finora
- Enes Özbek: Cyprus, 2004-2009Documento2 pagineEnes Özbek: Cyprus, 2004-2009Enes OzbekNessuna valutazione finora
- DTP Coursebook A Complete Text Book of Desktop Publishing For EveryoneDocumento249 pagineDTP Coursebook A Complete Text Book of Desktop Publishing For EveryonecoottyNessuna valutazione finora
- Introduction To C++Documento42 pagineIntroduction To C++Sanchit PatilNessuna valutazione finora
- Excel - Create A Speedometer Chart TutorialsDocumento7 pagineExcel - Create A Speedometer Chart Tutorialsnvc_vishwanathanNessuna valutazione finora
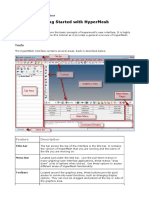
- Hm-1000: Getting Started With Hypermesh: ToolsDocumento4 pagineHm-1000: Getting Started With Hypermesh: Toolsakash_raikwar_2Nessuna valutazione finora
- Durga JAVA Interview Cre+adv+frameworkDocumento109 pagineDurga JAVA Interview Cre+adv+frameworkAkash SinghNessuna valutazione finora
- Tic-Tac-Toe CodeDocumento6 pagineTic-Tac-Toe CodeArihant KumarNessuna valutazione finora
- Uoc R1Documento12 pagineUoc R1Ahmed Khaled SeadaNessuna valutazione finora
- CP SAT Foundation Mock Exam August 2022Documento24 pagineCP SAT Foundation Mock Exam August 2022Dilip G NarappanavarNessuna valutazione finora
- Assignment 2 Server MaintenanceDocumento6 pagineAssignment 2 Server MaintenanceChristopher DemetriusNessuna valutazione finora
- Excel Tips For EngineeringDocumento17 pagineExcel Tips For EngineeringItalo VenegasNessuna valutazione finora
- Autocad Mep 2015: Course DescriptionDocumento3 pagineAutocad Mep 2015: Course DescriptionMarija MaricicNessuna valutazione finora
- Detailed Drawing Exercises: Solidworks EducationDocumento51 pagineDetailed Drawing Exercises: Solidworks EducationLal Krrish MikeNessuna valutazione finora
- Pscad ManualDocumento511 paginePscad ManualSammie AuduNessuna valutazione finora