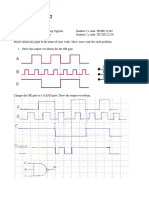
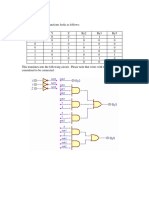
Potrebbero piacerti anche
- Cost Estimating Manual for Pipelines and Marine Structures: New Printing 1999Da EverandCost Estimating Manual for Pipelines and Marine Structures: New Printing 1999Valutazione: 5 su 5 stelle5/5 (2)
- Lecture Note 2Documento21 pagineLecture Note 2santiago greyratNessuna valutazione finora
- Melay and Moore and BCD and Excess 3Documento11 pagineMelay and Moore and BCD and Excess 3win papasanNessuna valutazione finora
- ITC161 Assignment 1: Computers & Data & Digital LogicDocumento6 pagineITC161 Assignment 1: Computers & Data & Digital LogicBrad GoddardNessuna valutazione finora
- CS206 CS 230 - Digital Logic Design Week 3Documento4 pagineCS206 CS 230 - Digital Logic Design Week 3Fahad Of arabiaNessuna valutazione finora
- Y, Z and W. After That, I Denote Seven Segments of The 7-Segment LED As A, B, C, D, eDocumento3 pagineY, Z and W. After That, I Denote Seven Segments of The 7-Segment LED As A, B, C, D, eVũ Hoàng LongNessuna valutazione finora
- Logic Design (CE 207, CE 213) Chapter No. 2 - Part No. 2: Z y y X Xy FDocumento8 pagineLogic Design (CE 207, CE 213) Chapter No. 2 - Part No. 2: Z y y X Xy FtytytyNessuna valutazione finora
- F Xy+x' y '+ y ' Z F Xy+x' y '+ y ' Z: Logic Design (CE 207, CE 213) Chapter No. 2 - Part No. 2Documento8 pagineF Xy+x' y '+ y ' Z F Xy+x' y '+ y ' Z: Logic Design (CE 207, CE 213) Chapter No. 2 - Part No. 2Freyja SigurgisladottirNessuna valutazione finora
- Lab 03Documento4 pagineLab 03Noman MustafaNessuna valutazione finora
- Akekaduro24 - 1894422Documento15 pagineAkekaduro24 - 1894422Kelvin OppongNessuna valutazione finora
- Graded 3Documento16 pagineGraded 3Abdulrehman HabibNessuna valutazione finora
- Full AdderDocumento2 pagineFull Adderraffy arranguezNessuna valutazione finora
- Chapter05 SMDocumento46 pagineChapter05 SMleeNessuna valutazione finora
- Assement 02Documento17 pagineAssement 02Naina Prashar100% (1)
- CHP 4Documento25 pagineCHP 4RizalFahmiNessuna valutazione finora
- DACS 2101 - Discrete Structures: Homework #2 - Fall 2021Documento3 pagineDACS 2101 - Discrete Structures: Homework #2 - Fall 2021Abbas KhanNessuna valutazione finora
- Exercise1 F01Documento4 pagineExercise1 F01Viktor KozorezNessuna valutazione finora
- Assignment 1Documento5 pagineAssignment 1Kireina Shafira HidayatNessuna valutazione finora
- FEM NotesDocumento10 pagineFEM NotesReetheshNessuna valutazione finora
- Binary-to-BCD Converter: Discussion D4.5Documento19 pagineBinary-to-BCD Converter: Discussion D4.5Siddhartha MukherjeeNessuna valutazione finora
- C Ac BC Ab C Ab Ab A: AbandDocumento2 pagineC Ac BC Ab C Ab Ab A: AbandFauzan HakimiNessuna valutazione finora
- Bayan University of Science and Technology Collage of EngineeringDocumento27 pagineBayan University of Science and Technology Collage of EngineeringOmur NoorNessuna valutazione finora
- Assignment1 CCCN212Documento2 pagineAssignment1 CCCN212Asma AlnounouNessuna valutazione finora
- Combinational CircuitsDocumento44 pagineCombinational Circuitsgoku dukeNessuna valutazione finora
- Tutorial 4 AnswersDocumento2 pagineTutorial 4 AnswersM Arif SiddiquiNessuna valutazione finora
- Tabla VerdadDocumento1 paginaTabla VerdadvalentinaNessuna valutazione finora
- Circuit DesignDocumento15 pagineCircuit DesignHafiezul HassanNessuna valutazione finora
- State Diagram:: Truth Table Relating S, R, T, Q (T) To Q (t+1) Q (T) S R T Q (t+1)Documento6 pagineState Diagram:: Truth Table Relating S, R, T, Q (T) To Q (t+1) Q (T) S R T Q (t+1)Irtaza AkramNessuna valutazione finora
- Ejercicio 12Documento12 pagineEjercicio 12Laura MoránNessuna valutazione finora
- Computer System Architecture NotesDocumento137 pagineComputer System Architecture NotesSaurabh PandeyNessuna valutazione finora
- Lay 1.2Documento11 pagineLay 1.2pri shNessuna valutazione finora
- Sample SolutionsDocumento4 pagineSample Solutionsravimech_862750Nessuna valutazione finora
- Assignment 1Documento41 pagineAssignment 1Sai BharathNessuna valutazione finora
- Logic Gates AnswersDocumento3 pagineLogic Gates AnswersNyein ChanNessuna valutazione finora
- Tutorial 2 - Electronics (2018)Documento3 pagineTutorial 2 - Electronics (2018)Pasindu PramodNessuna valutazione finora
- Book 1Documento11 pagineBook 1Jean Pablo Valverde MoraNessuna valutazione finora
- Ejerciccio de MicrocontroladorDocumento28 pagineEjerciccio de MicrocontroladorLuis Adrian ChipanaNessuna valutazione finora
- Running ECE LEDs DesignDocumento5 pagineRunning ECE LEDs DesignMarvin AtienzaNessuna valutazione finora
- Stadistica Simulacion Paradoja de Monty Hall - Sophia Martinez 802Documento31 pagineStadistica Simulacion Paradoja de Monty Hall - Sophia Martinez 802Sophia MartinezNessuna valutazione finora
- Laborator 3Documento6 pagineLaborator 3Dan GhimpuNessuna valutazione finora
- Tripoli University Faculty of Engineering Computer Engineering DepartmentDocumento13 pagineTripoli University Faculty of Engineering Computer Engineering Departmentmohammed altoumieNessuna valutazione finora
- Generation of Cyclic CodesDocumento11 pagineGeneration of Cyclic CodesRISHIKA SINHANessuna valutazione finora
- Gerald Forigua Andrade T00049723 Ing. Mecatronica: C 2 X C 2 yDocumento1 paginaGerald Forigua Andrade T00049723 Ing. Mecatronica: C 2 X C 2 yLina Stella Forigua AndradeNessuna valutazione finora
- Building Convolutional Neural Networks For Image Classification SlidesDocumento57 pagineBuilding Convolutional Neural Networks For Image Classification SlidesRahul ShettyNessuna valutazione finora
- DLD Manual - EXP - 3Documento3 pagineDLD Manual - EXP - 3Ahmad RazaNessuna valutazione finora
- BCD To Excess-3 CodeDocumento10 pagineBCD To Excess-3 CodeDr. B. Khaleelu Rehman Associate Professor, Dept. of ECENessuna valutazione finora
- Foro 2Documento4 pagineForo 2SouthSide RNessuna valutazione finora
- Uji Ambang Rangsangan - ManisDocumento1 paginaUji Ambang Rangsangan - ManiswahyuNessuna valutazione finora
- Inverse KinematicsDocumento64 pagineInverse KinematicsHoney RathoreNessuna valutazione finora
- Magic SquaresDocumento7 pagineMagic SquaresMassimiliano PatassiniNessuna valutazione finora
- BooleanFunctions QADocumento4 pagineBooleanFunctions QAironmanfire121Nessuna valutazione finora
- Applecore Childrens Clothing Solucion en ExcelDocumento8 pagineApplecore Childrens Clothing Solucion en ExcelMo LoganNessuna valutazione finora
- Computer Servicing 4: Introduction To Logic Gates Boolean AlgebraDocumento13 pagineComputer Servicing 4: Introduction To Logic Gates Boolean AlgebraJhon Keneth NamiasNessuna valutazione finora
- Boolean AlgebraDocumento29 pagineBoolean AlgebraDeepanshuNessuna valutazione finora
- DLD HWDocumento17 pagineDLD HWNấm LùnNessuna valutazione finora
- Problemas Resueltos IOPDocumento44 pagineProblemas Resueltos IOPjoema26Nessuna valutazione finora
- Rajshahi University of Engineering & Technology: Heaven's Light Is Our GuideDocumento38 pagineRajshahi University of Engineering & Technology: Heaven's Light Is Our GuideNafis HasanNessuna valutazione finora
- Tutorial 3Documento10 pagineTutorial 3kanuni41Nessuna valutazione finora
- Chapter 02 SolutionsDocumento75 pagineChapter 02 SolutionsDiane ParkNessuna valutazione finora
- Assignment 1 DSE 163Documento4 pagineAssignment 1 DSE 163sandunmaheesha01Nessuna valutazione finora
- Practical 1: Measuring The Wind Profile in The Surface LayerDocumento5 paginePractical 1: Measuring The Wind Profile in The Surface LayerajpsalisonNessuna valutazione finora
- Review of Basic Field Equations: Strain-Displacement RelationsDocumento14 pagineReview of Basic Field Equations: Strain-Displacement RelationsajpsalisonNessuna valutazione finora
- Highway Capacity EstimationDocumento7 pagineHighway Capacity Estimationajpsalison50% (2)
- DPWH Matrix of Trucks AxleDocumento5 pagineDPWH Matrix of Trucks AxleajpsalisonNessuna valutazione finora
- Good Versus Bad Teaching - NichollsDocumento29 pagineGood Versus Bad Teaching - Nichollsapi-300172472Nessuna valutazione finora
- Erik Soto LCVDocumento3 pagineErik Soto LCVapi-231949012Nessuna valutazione finora
- The Teochew Chinese of ThailandDocumento7 pagineThe Teochew Chinese of ThailandbijsshrjournalNessuna valutazione finora
- Chapter 5 Research EthicsDocumento30 pagineChapter 5 Research EthicsitsabcdeeNessuna valutazione finora
- Inter-Relationship Among Academic Performance Academic Achievement Learning OutcomesDocumento17 pagineInter-Relationship Among Academic Performance Academic Achievement Learning OutcomesWen PamanilayNessuna valutazione finora
- Retake 522 Asm1Documento17 pagineRetake 522 Asm1Trần Minh NhậtNessuna valutazione finora
- Complete Guide For Research.2Documento65 pagineComplete Guide For Research.2Jeric Cavidog ClaudioNessuna valutazione finora
- Plant Disease Detection Using Drones in Precision AgricultureDocumento20 paginePlant Disease Detection Using Drones in Precision AgricultureDavid Castorena MinorNessuna valutazione finora
- Pilferage Control in HospitalsDocumento4 paginePilferage Control in HospitalsDr. Rakshit Solanki100% (3)
- Your Results For: "Multiple Choice": Site Title: Book Title: Book Author: Location On Site: Date/Time SubmittedDocumento40 pagineYour Results For: "Multiple Choice": Site Title: Book Title: Book Author: Location On Site: Date/Time SubmittedthaihangusshNessuna valutazione finora
- Coding Simple PendulumDocumento7 pagineCoding Simple PendulumSarifudin HusniNessuna valutazione finora
- Flight Operations MonitoringDocumento49 pagineFlight Operations MonitoringAmr Alex100% (1)
- Maptek Vulcan Overview BrochureDocumento4 pagineMaptek Vulcan Overview Brochureyacoo54Nessuna valutazione finora
- Evaluación Back Pain Peter o SullivanDocumento11 pagineEvaluación Back Pain Peter o SullivanAntonio tapiaNessuna valutazione finora
- 1 World Issues Course Outline 2019-2020Documento4 pagine1 World Issues Course Outline 2019-2020api-237676128Nessuna valutazione finora
- BKDocumento5 pagineBKIrfan Khan100% (2)
- Dornyei - Understanding L2 MotivationDocumento10 pagineDornyei - Understanding L2 MotivationMarina Smirnova100% (1)
- Digital Participatory Culture and The TV AudienceDocumento212 pagineDigital Participatory Culture and The TV AudiencebugmenotNessuna valutazione finora
- Internship ReportDocumento45 pagineInternship ReportAsif Rajian Khan Apon100% (2)
- Proposal QUAL MoralesDocumento101 pagineProposal QUAL MoralesFrederick BaldemoroNessuna valutazione finora
- ARM Active Risk Manager Brochure PDFDocumento8 pagineARM Active Risk Manager Brochure PDFalirtaheri7299Nessuna valutazione finora
- Title: Impact of Leadership Styles On Performance Through The Mediating Role of Employee's MotivationDocumento29 pagineTitle: Impact of Leadership Styles On Performance Through The Mediating Role of Employee's Motivationsardar hussainNessuna valutazione finora
- Stress Assessment and Research Toolkit (StART)Documento11 pagineStress Assessment and Research Toolkit (StART)Dr-Chufo IzquierdoNessuna valutazione finora
- Week 3 - Describing Numerical DataDocumento7 pagineWeek 3 - Describing Numerical DatamarcNessuna valutazione finora
- Critique Paper BSUDocumento4 pagineCritique Paper BSUAndrei Dela CruzNessuna valutazione finora
- Weibull AnalysisDocumento6 pagineWeibull AnalysisT/ROXNessuna valutazione finora
- Smart Meter Data AnalysisDocumento306 pagineSmart Meter Data AnalysisGurpinder Singh100% (1)
- SEC6010 - Planning For Information SecurityDocumento9 pagineSEC6010 - Planning For Information SecurityVenkata Pathi JaligamaNessuna valutazione finora
- DLL On UNDERSTANDING DATA AND WAYS TO SYSTEMATICALLY COLLECT DATA - Research IIDocumento3 pagineDLL On UNDERSTANDING DATA AND WAYS TO SYSTEMATICALLY COLLECT DATA - Research IIRuffa L100% (1)
- Lecture in EntrepreneurshipDocumento7 pagineLecture in EntrepreneurshipAnonymous xl2Fs9R8wNessuna valutazione finora