Potrebbero piacerti anche
- Unit-V 3Documento36 pagineUnit-V 3Ash KNessuna valutazione finora
- Sampling Theory and Hypothesis TestingDocumento21 pagineSampling Theory and Hypothesis TestingMahendranath RamakrishnanNessuna valutazione finora
- 2012 Mean ComparisonDocumento35 pagine2012 Mean Comparison3rlangNessuna valutazione finora
- Unit VDocumento22 pagineUnit Vazly vanNessuna valutazione finora
- Sampling QBDocumento24 pagineSampling QBSHREYAS TR0% (1)
- Testing Two Independent Samples - With Minitab Procedures)Documento67 pagineTesting Two Independent Samples - With Minitab Procedures)Hey its meNessuna valutazione finora
- An Introduction To T-Tests: Statistical Test Means Hypothesis TestingDocumento8 pagineAn Introduction To T-Tests: Statistical Test Means Hypothesis Testingshivani100% (1)
- Chapter 9Documento14 pagineChapter 9Khay OngNessuna valutazione finora
- PT_Module5Documento30 paginePT_Module5Venkat BalajiNessuna valutazione finora
- Statistics For College Students-Part 2Documento43 pagineStatistics For College Students-Part 2Yeyen Patino100% (1)
- Statistics: The Chi Square TestDocumento41 pagineStatistics: The Chi Square TestAik ReyesNessuna valutazione finora
- Inferential Statistic IIDocumento61 pagineInferential Statistic IIThiviyashiniNessuna valutazione finora
- False - Choosing Random Individuals Who Pass by Yields A Random Sample False - Probability Predicts What Kind of PopulationDocumento5 pagineFalse - Choosing Random Individuals Who Pass by Yields A Random Sample False - Probability Predicts What Kind of Populationpiepie2Nessuna valutazione finora
- Non-Parametric_testDocumento12 pagineNon-Parametric_testhansdeep479Nessuna valutazione finora
- McNemar's Test & Mann-Whitney UDocumento24 pagineMcNemar's Test & Mann-Whitney UCashmira Balabagan-IbrahimNessuna valutazione finora
- Tests of Hypothesis: Statistical SignificanceDocumento49 pagineTests of Hypothesis: Statistical SignificanceJeff Andrian ParienteNessuna valutazione finora
- Statistical Analysis and Interpretation of Data: Nonparametric Tests ExplainedDocumento27 pagineStatistical Analysis and Interpretation of Data: Nonparametric Tests ExplainedPrasanth RaviNessuna valutazione finora
- Hypothesis TestDocumento19 pagineHypothesis TestmalindaNessuna valutazione finora
- Chapter 008-Data Analysis Techniques-UpdateDocumento32 pagineChapter 008-Data Analysis Techniques-UpdateSuryanti TsangNessuna valutazione finora
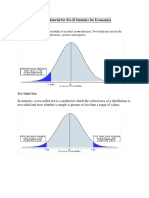
- Study Material For BA-II Statistics For Economics: One Tailed TestDocumento9 pagineStudy Material For BA-II Statistics For Economics: One Tailed TestC.s TanyaNessuna valutazione finora
- Hypothesis Testing GDocumento28 pagineHypothesis Testing GRenee Jezz LopezNessuna valutazione finora
- Understanding The Nature of StatisticsDocumento12 pagineUnderstanding The Nature of StatisticsDenisse Nicole SerutNessuna valutazione finora
- Advanced Statistics Hypothesis TestingDocumento42 pagineAdvanced Statistics Hypothesis TestingShermaine CachoNessuna valutazione finora
- Forms of Test StatisticsDocumento16 pagineForms of Test StatisticsRayezeus Jaiden Del RosarioNessuna valutazione finora
- Samra A. Akmad: InstructorDocumento20 pagineSamra A. Akmad: InstructorlolwriterNessuna valutazione finora
- Non Parametric Tests-Marketing ReasearchDocumento38 pagineNon Parametric Tests-Marketing ReasearchcalmchandanNessuna valutazione finora
- AnovaDocumento55 pagineAnovaFiona Fernandes67% (3)
- Prob Stat Lesson 9Documento44 pagineProb Stat Lesson 9Wellington FloresNessuna valutazione finora
- qm2 NotesDocumento9 pagineqm2 NotesdeltathebestNessuna valutazione finora
- Statistics and Numerical Methods - RekhaDocumento13 pagineStatistics and Numerical Methods - Rekhabhagyagr8Nessuna valutazione finora
- CLG Project ReportDocumento13 pagineCLG Project Reportruchi sharmaNessuna valutazione finora
- CH 7Documento36 pagineCH 7Legese TusseNessuna valutazione finora
- Forms of Test StatisticDocumento31 pagineForms of Test StatisticJackielou TrongcosoNessuna valutazione finora
- Statistics and Hypothesis Testing Using ExcelDocumento13 pagineStatistics and Hypothesis Testing Using ExcelKUNAL DURGANINessuna valutazione finora
- Testing Hypothesis & ANOVA TechniquesDocumento13 pagineTesting Hypothesis & ANOVA TechniquesAlvi KabirNessuna valutazione finora
- 2 Independent Samples: Mann-Whitney Test.: 1 2 n1 X, 1, 2,...., n2 YDocumento5 pagine2 Independent Samples: Mann-Whitney Test.: 1 2 n1 X, 1, 2,...., n2 YAre MeerNessuna valutazione finora
- 14-18 Stat Inferential Non-ParametricDocumento77 pagine14-18 Stat Inferential Non-ParametricCaren Valenzuela RubioNessuna valutazione finora
- Student's t-statistic: A guide to using this test for comparing means and testing hypothesesDocumento35 pagineStudent's t-statistic: A guide to using this test for comparing means and testing hypothesesAmaal GhaziNessuna valutazione finora
- Assignment Updated 101Documento24 pagineAssignment Updated 101Lovely Posion100% (1)
- Unit 3 Experimental Designs: ObjectivesDocumento14 pagineUnit 3 Experimental Designs: ObjectivesDep EnNessuna valutazione finora
- H Y Poth Esis Te Sting: T-TestDocumento21 pagineH Y Poth Esis Te Sting: T-TestJhaydiel JacutanNessuna valutazione finora
- STAT 1013 Statistics: Week 12Documento48 pagineSTAT 1013 Statistics: Week 12Angelo Valdez33% (3)
- Sign TestDocumento7 pagineSign TestJovito PermanteNessuna valutazione finora
- Paired T-Test: A Project Report OnDocumento19 paginePaired T-Test: A Project Report OnTarun kumarNessuna valutazione finora
- UNIT-4: Reading Material On Hypothesis Testing With Single SampleDocumento7 pagineUNIT-4: Reading Material On Hypothesis Testing With Single Samplesamaya pypNessuna valutazione finora
- STAT100 Fall19 Activity 21 WorksheetDocumento3 pagineSTAT100 Fall19 Activity 21 WorksheetabutiNessuna valutazione finora
- Ugc Net CommerceDocumento166 pagineUgc Net CommerceHilal Ahmad100% (3)
- T Test For Independent SamplesDocumento29 pagineT Test For Independent SamplesRichard BacharNessuna valutazione finora
- Hypothesis Testing GuideDocumento49 pagineHypothesis Testing GuideJomar Frogoso60% (20)
- Hypothesis Test for a Mean GuideDocumento5 pagineHypothesis Test for a Mean GuideBobbyNicholsNessuna valutazione finora
- BRM Assignment Sample Size - Tahir Khan AbdaliDocumento3 pagineBRM Assignment Sample Size - Tahir Khan AbdaliSyed Shahid SheraziNessuna valutazione finora
- 02 - Statistical Analysis - Chem32 PDFDocumento12 pagine02 - Statistical Analysis - Chem32 PDFBrian PermejoNessuna valutazione finora
- Mistakes in Quality Statistics: and How to Fix ThemDa EverandMistakes in Quality Statistics: and How to Fix ThemNessuna valutazione finora
- Sample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignDa EverandSample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignNessuna valutazione finora
- Statistics: a QuickStudy Laminated Reference GuideDa EverandStatistics: a QuickStudy Laminated Reference GuideNessuna valutazione finora
- Learn Statistics Fast: A Simplified Detailed Version for StudentsDa EverandLearn Statistics Fast: A Simplified Detailed Version for StudentsNessuna valutazione finora
- Hamiltonian Monte Carlo Methods in Machine LearningDa EverandHamiltonian Monte Carlo Methods in Machine LearningNessuna valutazione finora
- Explaining The Linkage Between Antecedents' Factors of Adopting Online Classes and Perceived Learning Outcome Using Extended UTAUT ModelDocumento12 pagineExplaining The Linkage Between Antecedents' Factors of Adopting Online Classes and Perceived Learning Outcome Using Extended UTAUT Modelrahmayunial06Nessuna valutazione finora
- Factor Structure of the Millon Adolescent Clinical InventoryDocumento6 pagineFactor Structure of the Millon Adolescent Clinical Inventorymyriam casner50% (2)
- SWB in PortugalDocumento25 pagineSWB in PortugalmenNessuna valutazione finora
- PLS-SEM or CB-SEM: Updated Guidelines On Which Method To UseDocumento17 paginePLS-SEM or CB-SEM: Updated Guidelines On Which Method To UseLazuardi AwalNessuna valutazione finora
- The relationship between positive thinking and individual characteristics in soccer playersDocumento10 pagineThe relationship between positive thinking and individual characteristics in soccer playersIrinNessuna valutazione finora
- Information Security Adherence in Institutions of Higher Education: A Case Study of American University of NigeriaDocumento10 pagineInformation Security Adherence in Institutions of Higher Education: A Case Study of American University of NigeriajournalNessuna valutazione finora
- Chona C. Burgos Bsoa-Om Dimensions of Stress Among Tricycle Drivers in Davao City: An Application of Exploratory Factor Analysis I. A. AuthorsDocumento2 pagineChona C. Burgos Bsoa-Om Dimensions of Stress Among Tricycle Drivers in Davao City: An Application of Exploratory Factor Analysis I. A. AuthorsChona BurgosNessuna valutazione finora
- Dr. Richa GautamDocumento30 pagineDr. Richa GautamTryl TsNessuna valutazione finora
- Analysis of Perception of The Customers Towards Digitization of Banking SectorDocumento11 pagineAnalysis of Perception of The Customers Towards Digitization of Banking SectorHARSH MALPANINessuna valutazione finora
- Factors Affecting Credit Card Use in IndiaDocumento18 pagineFactors Affecting Credit Card Use in India9451893077Nessuna valutazione finora
- Factors Affecting English Speaking Skills of StudentsDocumento10 pagineFactors Affecting English Speaking Skills of StudentsMiftah Nag BjbNessuna valutazione finora
- Intelligence: Balazs Aczel, Bence Pal Fi, Zoltan KekecsDocumento8 pagineIntelligence: Balazs Aczel, Bence Pal Fi, Zoltan KekecsJavier NessNessuna valutazione finora
- Exploratory Factor AnalysisDocumento35 pagineExploratory Factor Analysismgmt6008Nessuna valutazione finora
- Sustainability 11 00613Documento20 pagineSustainability 11 00613Амур БагауриNessuna valutazione finora
- Content ServerDocumento21 pagineContent ServerOmar TerraNessuna valutazione finora
- International Internal Audit Standards IIA and TheDocumento14 pagineInternational Internal Audit Standards IIA and Thesern soonNessuna valutazione finora
- Dynamics of Consumer's Perception, Demographic Characteristics and Consumer's Behavior Towards Selection of A Restaurant PDFDocumento14 pagineDynamics of Consumer's Perception, Demographic Characteristics and Consumer's Behavior Towards Selection of A Restaurant PDFAgusTina Pikaa WoelandsariNessuna valutazione finora
- Goldberg, 1990 Five FactorDocumento14 pagineGoldberg, 1990 Five FactorbpregerNessuna valutazione finora
- Franchising andDocumento11 pagineFranchising andmohhmameddNessuna valutazione finora
- Principal Component Regression Analysis With: R.X. Liu, J. Kuang, Q. Gong, X.L. HouDocumento7 paginePrincipal Component Regression Analysis With: R.X. Liu, J. Kuang, Q. Gong, X.L. HouOscar ArsonistNessuna valutazione finora
- Family JournalDocumento19 pagineFamily Journalemily45Nessuna valutazione finora
- Role of Micro-Financing in Women Empowerment: An Empirical Study of Urban PunjabDocumento16 pagineRole of Micro-Financing in Women Empowerment: An Empirical Study of Urban PunjabAnum ZubairNessuna valutazione finora
- Principal Component AnalysisDocumento17 paginePrincipal Component AnalysisNovi NurcahyaningsihNessuna valutazione finora
- Confirmatory Factor Analysis With AMOS: T&F's Data Site SPSS Data PageDocumento7 pagineConfirmatory Factor Analysis With AMOS: T&F's Data Site SPSS Data PageHajar AsmidarNessuna valutazione finora
- Journal of Financial Economics: Bryan T. Kelly, Seth Pruitt, Yinan SuDocumento24 pagineJournal of Financial Economics: Bryan T. Kelly, Seth Pruitt, Yinan SuviolettaNessuna valutazione finora
- Total Quality Management, Balanced Scorecard and PerformanceDocumento16 pagineTotal Quality Management, Balanced Scorecard and PerformanceAglin MaghfiraNessuna valutazione finora
- Sinharay S. Definition of Statistical InferenceDocumento11 pagineSinharay S. Definition of Statistical InferenceSara ZeynalzadeNessuna valutazione finora
- Mva - 2008 India School Rick LoydDocumento86 pagineMva - 2008 India School Rick Loydamar_saxena60857Nessuna valutazione finora
- Multi WayDocumento68 pagineMulti WayAlex IkedaNessuna valutazione finora
- EDu 302-Lec1-9Documento65 pagineEDu 302-Lec1-9PakistaniTalent cover songsNessuna valutazione finora