Potrebbero piacerti anche
- CRAN Recipes: DPLYR, Stringr, Lubridate, and RegEx in RDa EverandCRAN Recipes: DPLYR, Stringr, Lubridate, and RegEx in RNessuna valutazione finora
- OS Process Synchronization CompleteDocumento63 pagineOS Process Synchronization CompleteAfza FatimaNessuna valutazione finora
- OS Unit-3Documento45 pagineOS Unit-3mudduswamyNessuna valutazione finora
- 1.5 AlgorithmsDocumento32 pagine1.5 AlgorithmsAprajita KumariNessuna valutazione finora
- Unit1 5Documento76 pagineUnit1 5Ngô Việtt AnnhNessuna valutazione finora
- Os Module 2 21 Scheme NotesDocumento23 pagineOs Module 2 21 Scheme NotesMudassir PashaNessuna valutazione finora
- BashGuide - TestsAndConditionals - Greg's Wiki11Documento14 pagineBashGuide - TestsAndConditionals - Greg's Wiki11prateekNessuna valutazione finora
- Introduction To Concurrent Programming: Operating SystemsDocumento18 pagineIntroduction To Concurrent Programming: Operating Systemsonkar khavaleNessuna valutazione finora
- Chapter 3 - Process SynchronizationDocumento61 pagineChapter 3 - Process Synchronizationhhbw10Nessuna valutazione finora
- SD-CC: GDB TutorialDocumento2 pagineSD-CC: GDB TutorialBogdan GeorgeNessuna valutazione finora
- Chapter 3 - Process SynchronizationDocumento61 pagineChapter 3 - Process Synchronizationsibhat mequanintNessuna valutazione finora
- Lecture07 Full and ParallelDocumento45 pagineLecture07 Full and ParallelVeadeshNessuna valutazione finora
- Programming Assignment 2: Priority Queues and Disjoint SetsDocumento11 pagineProgramming Assignment 2: Priority Queues and Disjoint SetsAnanya KallankudluNessuna valutazione finora
- Programming Assignment 2: Priority Queues and Disjoint SetsDocumento11 pagineProgramming Assignment 2: Priority Queues and Disjoint SetsDaniel SerranoNessuna valutazione finora
- ClassTest Part3Documento6 pagineClassTest Part3Pooja SNessuna valutazione finora
- Linear Learning With Allreduce: John Langford (With Help From Many)Documento33 pagineLinear Learning With Allreduce: John Langford (With Help From Many)juggleninjaNessuna valutazione finora
- Unit1 5Documento73 pagineUnit1 5Giáp TrầnNessuna valutazione finora
- OS Process Synchronization Unit 3Documento58 pagineOS Process Synchronization Unit 3austinme727Nessuna valutazione finora
- AlgoDocumento36 pagineAlgoAtta RandhawaNessuna valutazione finora
- OS Module2 PDFDocumento22 pagineOS Module2 PDFSadh SNessuna valutazione finora
- OS Process Synchronization Unit 3Documento55 pagineOS Process Synchronization Unit 3AbhayNessuna valutazione finora
- Day 2 1 Advanced-OpenmpDocumento52 pagineDay 2 1 Advanced-OpenmpJAMEEL AHMADNessuna valutazione finora
- Introduction To Software EngineeringDocumento30 pagineIntroduction To Software EngineeringsanaNessuna valutazione finora
- 04 Shared MemoryDocumento68 pagine04 Shared MemoryakttripathiNessuna valutazione finora
- PythonDocumento76 paginePythonAjay kumar BaleboinaNessuna valutazione finora
- Programming Assignment 1: Decomposition of Graphs: Algorithms On Graphs ClassDocumento10 pagineProgramming Assignment 1: Decomposition of Graphs: Algorithms On Graphs ClassRani SorenNessuna valutazione finora
- Class 12 TopicsDocumento43 pagineClass 12 Topicsgideontargrave7Nessuna valutazione finora
- Design Decisions and Implementation Details in Vegan: Jari OksanenDocumento10 pagineDesign Decisions and Implementation Details in Vegan: Jari OksanenWilliam Alberto Florez FrancoNessuna valutazione finora
- Notes From The Series Namaste JavascriptDocumento30 pagineNotes From The Series Namaste JavascriptTejaswi SedimbiNessuna valutazione finora
- Verilog Questions by Shekar PDFDocumento5 pagineVerilog Questions by Shekar PDFmeghna veggalamNessuna valutazione finora
- Concurrency: Background and ImplementationDocumento20 pagineConcurrency: Background and ImplementationAkhil VashishthaNessuna valutazione finora
- Overview of Programming and Problem Solving: Dale/Weems/HeadingtonDocumento46 pagineOverview of Programming and Problem Solving: Dale/Weems/HeadingtonJoe BlackNessuna valutazione finora
- Spyglass® Known Problems and Solutions: This Document Describes The FollowingDocumento82 pagineSpyglass® Known Problems and Solutions: This Document Describes The FollowingLeslie WrightNessuna valutazione finora
- Oracle Cluster On CentOS Using CentOS Cluster Ware PDFDocumento131 pagineOracle Cluster On CentOS Using CentOS Cluster Ware PDFmusabsyd100% (1)
- groovyBC PDFDocumento13 paginegroovyBC PDFtoolpostNessuna valutazione finora
- Ch-6 - Process SynchronizationDocumento31 pagineCh-6 - Process SynchronizationsankarkvdcNessuna valutazione finora
- OS Notes Module 3 4Documento49 pagineOS Notes Module 3 4Huzaifa AnjumNessuna valutazione finora
- ASSIGNMENT 1 2020 (5%) : Cse1Pes: Programming For Engineers and Scientist SDocumento8 pagineASSIGNMENT 1 2020 (5%) : Cse1Pes: Programming For Engineers and Scientist SFarrukh AbbasiNessuna valutazione finora
- Arrier Ynchronization: by Samir NajarDocumento70 pagineArrier Ynchronization: by Samir NajarSamir NajarNessuna valutazione finora
- Mem ManDocumento25 pagineMem ManRude MaverickNessuna valutazione finora
- 590-Bypass Hardware Breakpoint ProtectionDocumento24 pagine590-Bypass Hardware Breakpoint Protectionapi-3754605Nessuna valutazione finora
- Multithreading and Java: Concurrent ProgrammingDocumento17 pagineMultithreading and Java: Concurrent Programmingjeyaprakash120690Nessuna valutazione finora
- DA SlidesDocumento349 pagineDA SlidesAvinash RajoriyaNessuna valutazione finora
- Week2 - Assignment SolutionsDocumento16 pagineWeek2 - Assignment Solutionsmobal62523Nessuna valutazione finora
- Computer Programming/Error HandlingDocumento7 pagineComputer Programming/Error HandlingNirmala OmkaregowdaNessuna valutazione finora
- If StatementDocumento7 pagineIf Statementmuhammad jehangirNessuna valutazione finora
- Debugging A C++ Program Under Unix: GDB TutorialDocumento6 pagineDebugging A C++ Program Under Unix: GDB TutorialLong VũNessuna valutazione finora
- Computer Architecture: Concurrency Khiyam IftikharDocumento10 pagineComputer Architecture: Concurrency Khiyam IftikharHassan AsgharNessuna valutazione finora
- Programming Fundamentals: by Imran KazmiDocumento17 pagineProgramming Fundamentals: by Imran KazmiAbdul Quddus KhanNessuna valutazione finora
- 09 Graph Decomposition Problems 1Documento12 pagine09 Graph Decomposition Problems 1Guru Prasad IyerNessuna valutazione finora
- Multiple-/Single-Choice Questions: and RegressionDocumento3 pagineMultiple-/Single-Choice Questions: and RegressionAkshay KumbarwarNessuna valutazione finora
- Ann MPDM IiDocumento42 pagineAnn MPDM Iisidra shafiqNessuna valutazione finora
- Lab # 2 Loops and Logic: Objective: TheoryDocumento11 pagineLab # 2 Loops and Logic: Objective: TheoryBakhtawar ChangeziNessuna valutazione finora
- CPU SchedulingDocumento39 pagineCPU SchedulingAbhishek DuttaNessuna valutazione finora
- 6.os Unit-Ii (Process Synchronization)Documento15 pagine6.os Unit-Ii (Process Synchronization)Bishnu PrasadNessuna valutazione finora
- Operating System ProcessDocumento57 pagineOperating System Processsasongko wardhanaNessuna valutazione finora
- Process SynchronizationDocumento23 pagineProcess Synchronizationwowafer745Nessuna valutazione finora
- ECS - Solution To Address CVE-2022-31231 Security Vulnerability On 3.5.x - 3.6.x - Dell USDocumento11 pagineECS - Solution To Address CVE-2022-31231 Security Vulnerability On 3.5.x - 3.6.x - Dell USMarcelo MafraNessuna valutazione finora
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningDa EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningNessuna valutazione finora
- Ita403 Accounting-And-financial-management TH 1.00 Ac20Documento1 paginaIta403 Accounting-And-financial-management TH 1.00 Ac20Deepak ChakrasaliNessuna valutazione finora
- Visualization Tool SeminarDocumento12 pagineVisualization Tool SeminarDeepak ChakrasaliNessuna valutazione finora
- Eng601 Professional-And-communication-skills Ela 2.10 Ac29Documento2 pagineEng601 Professional-And-communication-skills Ela 2.10 Ac29Deepak ChakrasaliNessuna valutazione finora
- ADVANCED Book Shop Management SystemDocumento4 pagineADVANCED Book Shop Management SystemDeepak ChakrasaliNessuna valutazione finora
- Book Shop Management System SYNOPSISDocumento18 pagineBook Shop Management System SYNOPSISDeepak Chakrasali75% (12)
- Portable Mobile Charger Using Solar PanelDocumento18 paginePortable Mobile Charger Using Solar PanelDeepak ChakrasaliNessuna valutazione finora
- Laser Security AlarmDocumento8 pagineLaser Security AlarmDeepak ChakrasaliNessuna valutazione finora
- Data StructureDocumento2 pagineData StructureDeepak ChakrasaliNessuna valutazione finora
- Mineral Claim Purchase and Sale Agreement FinalDocumento5 pagineMineral Claim Purchase and Sale Agreement Finaldaks4uNessuna valutazione finora
- CCBA Exam: Questions & Answers (Demo Version - Limited Content)Documento11 pagineCCBA Exam: Questions & Answers (Demo Version - Limited Content)begisep202Nessuna valutazione finora
- Phrasal Verbs en Inglés.Documento2 paginePhrasal Verbs en Inglés.David Alexander Palomo QuirozNessuna valutazione finora
- Sample Heat Sheets June 2007Documento63 pagineSample Heat Sheets June 2007Nesuui MontejoNessuna valutazione finora
- Portfolio Sandwich Game Lesson PlanDocumento2 paginePortfolio Sandwich Game Lesson Planapi-252005239Nessuna valutazione finora
- France 10-Day ItineraryDocumento3 pagineFrance 10-Day ItineraryYou goabroadNessuna valutazione finora
- Nodal Mesh AnalysisDocumento20 pagineNodal Mesh Analysisjaspreet964Nessuna valutazione finora
- Statistics 2Documento121 pagineStatistics 2Ravi KNessuna valutazione finora
- Digital-To-Analog Converter - Wikipedia, The Free EncyclopediaDocumento8 pagineDigital-To-Analog Converter - Wikipedia, The Free EncyclopediaAnilkumar KubasadNessuna valutazione finora
- List of Every National School Walkout PDF LinksDocumento373 pagineList of Every National School Walkout PDF LinksStephanie Dube Dwilson100% (1)
- Financial/ Accounting Ratios: Sebi Grade A & Rbi Grade BDocumento10 pagineFinancial/ Accounting Ratios: Sebi Grade A & Rbi Grade Bneevedita tiwariNessuna valutazione finora
- The Community Reinvestment Act in The Age of Fintech and Bank CompetitionDocumento28 pagineThe Community Reinvestment Act in The Age of Fintech and Bank CompetitionHyder AliNessuna valutazione finora
- CV's of M.ishtiaqDocumento3 pagineCV's of M.ishtiaqishtiaqNessuna valutazione finora
- Where Business Happens Where Happens: SupportDocumento19 pagineWhere Business Happens Where Happens: SupportRahul RamtekkarNessuna valutazione finora
- TLE-Carpentry7 Q4M4Week4 PASSED NoAKDocumento12 pagineTLE-Carpentry7 Q4M4Week4 PASSED NoAKAmelita Benignos OsorioNessuna valutazione finora
- Understand Fox Behaviour - Discover WildlifeDocumento1 paginaUnderstand Fox Behaviour - Discover WildlifeChris V.Nessuna valutazione finora
- DGA Furan AnalysisDocumento42 pagineDGA Furan AnalysisShefian Md Dom100% (10)
- Bangalore Escorts Services - Riya ShettyDocumento11 pagineBangalore Escorts Services - Riya ShettyRiya ShettyNessuna valutazione finora
- Consumer Price SummaryDocumento5 pagineConsumer Price SummaryKJ HiramotoNessuna valutazione finora
- Aui2601 Exam Pack 2016 1Documento57 pagineAui2601 Exam Pack 2016 1ricara alexia moodleyNessuna valutazione finora
- 2018 International Swimming Pool and Spa CodeDocumento104 pagine2018 International Swimming Pool and Spa CodeEngFaisal Alrai100% (3)
- HOWO SERVICE AND MAINTENANCE SCHEDULE SinotruckDocumento3 pagineHOWO SERVICE AND MAINTENANCE SCHEDULE SinotruckRPaivaNessuna valutazione finora
- What Is A Timer?Documento12 pagineWhat Is A Timer?Hemraj Singh Rautela100% (1)
- Queen - Hammer To Fall ChordsDocumento3 pagineQueen - Hammer To Fall ChordsDavideContiNessuna valutazione finora
- Veris Case StudyDocumento2 pagineVeris Case StudyPankaj GargNessuna valutazione finora
- Business Maths Chapter 5Documento9 pagineBusiness Maths Chapter 5鄭仲抗Nessuna valutazione finora
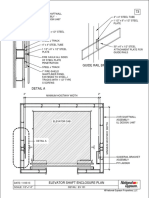
- Guide Rail Bracket AssemblyDocumento1 paginaGuide Rail Bracket AssemblyPrasanth VarrierNessuna valutazione finora
- Mathematical Method For Physicists Ch. 1 & 2 Selected Solutions Webber and ArfkenDocumento7 pagineMathematical Method For Physicists Ch. 1 & 2 Selected Solutions Webber and ArfkenJosh Brewer100% (3)
- Digital Economy 1Documento11 pagineDigital Economy 1Khizer SikanderNessuna valutazione finora
- Problem Solving Questions: Solutions (Including Comments)Documento25 pagineProblem Solving Questions: Solutions (Including Comments)Narendrn KanaesonNessuna valutazione finora