Potrebbero piacerti anche
- ARTIFICIAL NEURAL NETWORKS-moduleIIIDocumento61 pagineARTIFICIAL NEURAL NETWORKS-moduleIIIelakkadanNessuna valutazione finora
- Statistical Methods in ANNDocumento42 pagineStatistical Methods in ANNelakkadanNessuna valutazione finora
- All-Wheel Direct Drive System Using Switched Reluctance Motor in Inverted ConfigurationDocumento2 pagineAll-Wheel Direct Drive System Using Switched Reluctance Motor in Inverted ConfigurationelakkadanNessuna valutazione finora
- Kerala University M Tech Power Systems SyllabusDocumento88 pagineKerala University M Tech Power Systems SyllabuselakkadanNessuna valutazione finora
- Public Sector Undertakings Recruiting Through GATE 2014Documento3 paginePublic Sector Undertakings Recruiting Through GATE 2014elakkadanNessuna valutazione finora
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Collaboration Proposal FormDocumento4 pagineCollaboration Proposal FormGabriel TecuceanuNessuna valutazione finora
- Comparisons YouTrackDocumento13 pagineComparisons YouTrackMihai DanielNessuna valutazione finora
- Getting You To Test Day: An 8-Week Prep Plan For The TOEFL TestDocumento2 pagineGetting You To Test Day: An 8-Week Prep Plan For The TOEFL Testsmith90Nessuna valutazione finora
- B1+ Exam MappingDocumento3 pagineB1+ Exam Mappingmonika krajewskaNessuna valutazione finora
- 2 Mathematics For Social Science-1-1Documento58 pagine2 Mathematics For Social Science-1-1ሀበሻ EntertainmentNessuna valutazione finora
- Artikel Jurnal Siti Tsuwaibatul ADocumento11 pagineArtikel Jurnal Siti Tsuwaibatul Aaslamiyah1024Nessuna valutazione finora
- Real-World Data Is Dirty: Data Cleansing and The Merge/Purge ProblemDocumento29 pagineReal-World Data Is Dirty: Data Cleansing and The Merge/Purge Problemapi-19731161Nessuna valutazione finora
- Mars Climate Orbiter ReportDocumento27 pagineMars Climate Orbiter Reportbiguelo100% (1)
- Excel Tips Tricks e-BookV1.1 PDFDocumento20 pagineExcel Tips Tricks e-BookV1.1 PDFSulabhNessuna valutazione finora
- Module 1-Grade 9Documento19 pagineModule 1-Grade 9Charity NavarroNessuna valutazione finora
- Practical FileDocumento108 paginePractical FileRakesh KumarNessuna valutazione finora
- Daily ReportDocumento39 pagineDaily ReportLe TuanNessuna valutazione finora
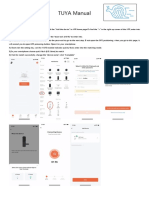
- TUYA ManualDocumento2 pagineTUYA ManualMagandang MallNessuna valutazione finora
- Mazada Consortium LimitedDocumento3 pagineMazada Consortium Limitedjowila5377Nessuna valutazione finora
- Intelligent Building FacadeDocumento32 pagineIntelligent Building FacadeVeè Vêk JåyswãlNessuna valutazione finora
- List of ItemsDocumento5 pagineList of ItemsMoiNessuna valutazione finora
- PDF EnglishDocumento36 paginePDF EnglishSanti CheewabantherngNessuna valutazione finora
- How To Query Asham Tele Points (Telebirr)Documento13 pagineHow To Query Asham Tele Points (Telebirr)Fayisa ETNessuna valutazione finora
- CreditCardStatement3665658 - 2087 - 02-Mar-21Documento2 pagineCreditCardStatement3665658 - 2087 - 02-Mar-21Aamir MushtaqNessuna valutazione finora
- Very High Frequency Omni-Directional Range: Alejandro Patt CarrionDocumento21 pagineVery High Frequency Omni-Directional Range: Alejandro Patt CarrionAlejandro PattNessuna valutazione finora
- Psyc 1100 Research ExperimentDocumento10 paginePsyc 1100 Research Experimentapi-242343747Nessuna valutazione finora
- Hatton National Bank PLC: Instance Type and TransmissionDocumento2 pagineHatton National Bank PLC: Instance Type and TransmissiontaraNessuna valutazione finora
- Final Model Paper Computer Science HSSC-IIDocumento9 pagineFinal Model Paper Computer Science HSSC-IIMUhammad Milad AwanNessuna valutazione finora
- Google - (Chrome) - Default NetworkDocumento21 pagineGoogle - (Chrome) - Default Networkjohnnyalves93302Nessuna valutazione finora
- APP PinAAcle 900 Elemental Analysis of Beer by FAAS 012049 01Documento3 pagineAPP PinAAcle 900 Elemental Analysis of Beer by FAAS 012049 01strubingeraNessuna valutazione finora
- 10th Syllbus PDFDocumento104 pagine10th Syllbus PDFGagandeep KaurNessuna valutazione finora
- TRANSLATIONDocumento4 pagineTRANSLATIONGarren Jude Aquino100% (1)
- Reports On TECHNICAL ASSISTANCE PROVIDED by The Teachers To The Learners / Learning FacilitatorsDocumento2 pagineReports On TECHNICAL ASSISTANCE PROVIDED by The Teachers To The Learners / Learning FacilitatorsJerv AlferezNessuna valutazione finora
- JSEA - Hydro Test - 2833Documento13 pagineJSEA - Hydro Test - 2833Amit Sharma100% (1)
- Yamaha Gp1200 Owners ManualDocumento3 pagineYamaha Gp1200 Owners ManualGregoryNessuna valutazione finora