Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Mochammad Adji Firmansyah Study PlanDocumento1 paginaMochammad Adji Firmansyah Study PlanMochammad Adji Firmansyah100% (1)
- Far LowDocumento4 pagineFar LowDidier ArchambaultNessuna valutazione finora
- Harmony LessonDocumento6 pagineHarmony LessonMochammad Adji FirmansyahNessuna valutazione finora
- Slightly Out of Reach (Solos) : Keyboard SoloDocumento3 pagineSlightly Out of Reach (Solos) : Keyboard SoloMochammad Adji FirmansyahNessuna valutazione finora
- Tom Quayle - From Rock To Fusion DVDDocumento11 pagineTom Quayle - From Rock To Fusion DVDJuan Villegas100% (2)
- Pengantar Manajemen Rantai Pasok: Oleh: Erma SuryaniDocumento53 paginePengantar Manajemen Rantai Pasok: Oleh: Erma SuryaniMochammad Adji FirmansyahNessuna valutazione finora
- Forecasting Time Series With Arma and Arima Models The Box-Jenkins MethodologyDocumento35 pagineForecasting Time Series With Arma and Arima Models The Box-Jenkins MethodologyMochammad Adji FirmansyahNessuna valutazione finora
- Cw1 Drivin TabDocumento10 pagineCw1 Drivin Tabarturxox1zNessuna valutazione finora
- Form SuratDocumento1 paginaForm SuratMochammad Adji FirmansyahNessuna valutazione finora
- PreparationDocumento2 paginePreparationMochammad Adji FirmansyahNessuna valutazione finora
- Tq1 Hopes NotesDocumento1 paginaTq1 Hopes NotesMochammad Adji FirmansyahNessuna valutazione finora
- TQ 1Documento6 pagineTQ 1Mochammad Adji Firmansyah80% (5)
- Analisis 3: Nilai Negatif Pada Analisis 1 Yang Di Drop Lalu Model Dijalankan Kembali - Hasil Analisisnya Sebagai BerikutDocumento3 pagineAnalisis 3: Nilai Negatif Pada Analisis 1 Yang Di Drop Lalu Model Dijalankan Kembali - Hasil Analisisnya Sebagai BerikutMochammad Adji FirmansyahNessuna valutazione finora
- Contoh KuesionerDocumento2 pagineContoh KuesionerMochammad Adji FirmansyahNessuna valutazione finora
- Tugas 2 SMBDDocumento11 pagineTugas 2 SMBDMochammad Adji FirmansyahNessuna valutazione finora
- Flow AnalysisDocumento27 pagineFlow AnalysisMochammad Adji FirmansyahNessuna valutazione finora
- Pokok Bahasan #1-1 Review BDDocumento30 paginePokok Bahasan #1-1 Review BDMochammad Adji FirmansyahNessuna valutazione finora
- Pokok Bahasan #11 DB Design & TuningDocumento20 paginePokok Bahasan #11 DB Design & TuningMochammad Adji FirmansyahNessuna valutazione finora
- Pokok Bahasan #1-2 Review DB ArchitectureDocumento53 paginePokok Bahasan #1-2 Review DB ArchitectureMochammad Adji FirmansyahNessuna valutazione finora
- Tugas 1 SMBDDocumento6 pagineTugas 1 SMBDMochammad Adji FirmansyahNessuna valutazione finora
- CADocumento19 pagineCAMochammad Adji FirmansyahNessuna valutazione finora
- Angel of DarknessDocumento13 pagineAngel of DarknessMochammad Adji FirmansyahNessuna valutazione finora
- Slightly Out of Reach (Solos) : Keyboard SoloDocumento3 pagineSlightly Out of Reach (Solos) : Keyboard SoloMochammad Adji FirmansyahNessuna valutazione finora
- Vitali T - Major II - V7 - I As The Chromatic PentatonicsDocumento3 pagineVitali T - Major II - V7 - I As The Chromatic PentatonicsMochammad Adji FirmansyahNessuna valutazione finora
- C Dominant 7flat5 Arpeggio: 44 P V Ev Ev V V Ev Ev V V Ev Ev V V V V V V Ev eVV JDocumento2 pagineC Dominant 7flat5 Arpeggio: 44 P V Ev Ev V V Ev Ev V V Ev Ev V V V V V V Ev eVV JMochammad Adji FirmansyahNessuna valutazione finora
- Buyer ChevronDocumento2 pagineBuyer ChevronMochammad Adji FirmansyahNessuna valutazione finora
- Is It YouDocumento2 pagineIs It YouSamuel ValeniaNessuna valutazione finora
- Formulir Pendaftaran Djarum Beasiswa Plus 2011 2012 PDFDocumento4 pagineFormulir Pendaftaran Djarum Beasiswa Plus 2011 2012 PDFIrwan AnugrahNessuna valutazione finora
- Post TestDocumento1 paginaPost TestMochammad Adji FirmansyahNessuna valutazione finora
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- CH 11Documento37 pagineCH 11Raj ChauhanNessuna valutazione finora
- LaptopDocumento22 pagineLaptopAnoopNessuna valutazione finora
- Cisco IP DampeningDocumento18 pagineCisco IP DampeningERLITHONessuna valutazione finora
- FactoryTalk VantagePoint EMI Server - 8.20.00 (Released 10 - 2020)Documento10 pagineFactoryTalk VantagePoint EMI Server - 8.20.00 (Released 10 - 2020)Ary Fernando PissoNessuna valutazione finora
- Learn by ExampleDocumento112 pagineLearn by ExampleSimon LutzNessuna valutazione finora
- Mediaplayer11 Text ResourcesDocumento7 pagineMediaplayer11 Text ResourcesRobert SchumannNessuna valutazione finora
- Attacking Cisco R&S With Kali (Backtrac)Documento23 pagineAttacking Cisco R&S With Kali (Backtrac)Rakesh KumarNessuna valutazione finora
- Yamaha RX-V367/HTR-3063 Firmware Installation - ManualDocumento5 pagineYamaha RX-V367/HTR-3063 Firmware Installation - ManualKlaus Emerson KowalskiNessuna valutazione finora
- 01 SolonDocumento9 pagine01 SolonDaud Jiong KIMNessuna valutazione finora
- HOWTO Using Openvpn To Bridge NetworksDocumento10 pagineHOWTO Using Openvpn To Bridge NetworksNghia NguyenNessuna valutazione finora
- Game CrashDocumento35 pagineGame CrashJoao Vitor AlvesNessuna valutazione finora
- (润州)ZX5102WT DataSheetDocumento3 pagine(润州)ZX5102WT DataSheetjorgeNessuna valutazione finora
- CC3x20 Labs PDFDocumento29 pagineCC3x20 Labs PDFyuvarajnarayanasamyNessuna valutazione finora
- Installation LogDocumento2 pagineInstallation LogHacksbyRay & HacksbyHeainzNessuna valutazione finora
- Multifunzione Laser BN Panasonic KX mb2130 PDFDocumento2 pagineMultifunzione Laser BN Panasonic KX mb2130 PDFblackghostNessuna valutazione finora
- On "IOT Smart Bulb": Mini Project ReportDocumento7 pagineOn "IOT Smart Bulb": Mini Project ReportRanveer RotwalNessuna valutazione finora
- Magical Macintosh Key SequencesDocumento11 pagineMagical Macintosh Key Sequenceszawzawsugu3Nessuna valutazione finora
- Powerbuilder 12.5: Installation GuideDocumento48 paginePowerbuilder 12.5: Installation Guidem.naveed.ashraf.k8400Nessuna valutazione finora
- Benefits and Features Pin Assignment: DS2502 1Kb Add-Only MemoryDocumento24 pagineBenefits and Features Pin Assignment: DS2502 1Kb Add-Only MemoryFariasNessuna valutazione finora
- What Is Amazon Ec2Documento18 pagineWhat Is Amazon Ec2Chaitu ChaitanyaNessuna valutazione finora
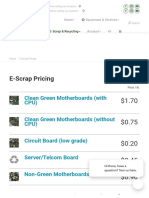
- List E-Waste PriceDocumento4 pagineList E-Waste PriceArianna ContrerasNessuna valutazione finora
- CS610 Mcqs MidTerm by Vu Topper RMDocumento46 pagineCS610 Mcqs MidTerm by Vu Topper RMCh HamXa Aziz (HeMi)Nessuna valutazione finora
- En-548 Doc-Dwg ListDocumento3 pagineEn-548 Doc-Dwg ListPanosMitsopoulosNessuna valutazione finora
- NetSDK Programming ManualDocumento49 pagineNetSDK Programming ManualRodrigo VieiraNessuna valutazione finora
- PC Repair TechnicianDocumento16 paginePC Repair TechnicianFairuz HanafiahNessuna valutazione finora
- OceanStor 2000 V3 Series Storage Systems V300R006C20 Upgrade Guide 06Documento295 pagineOceanStor 2000 V3 Series Storage Systems V300R006C20 Upgrade Guide 06Pelon SinpeloNessuna valutazione finora
- An Introduction To Computer Networks - An Introduction To Computer Networks, Desktop Edition 2.0.10Documento7 pagineAn Introduction To Computer Networks - An Introduction To Computer Networks, Desktop Edition 2.0.10Mike MikkelsenNessuna valutazione finora
- 10th Physics Chapter 17 - 2 PDFDocumento1 pagina10th Physics Chapter 17 - 2 PDFAsad SaleemNessuna valutazione finora
- Bluecoat SG Proxy MibDocumento15 pagineBluecoat SG Proxy MibRonald SaavedraNessuna valutazione finora
- Seminar Report ON Cloud Storage 1Documento25 pagineSeminar Report ON Cloud Storage 1Krishna KhedkarNessuna valutazione finora