Potrebbero piacerti anche
- DALADAWE THEWA HANDA - emDocumento1 paginaDALADAWE THEWA HANDA - emRochana RamanayakaNessuna valutazione finora
- Bondawi Bondawi - DDocumento2 pagineBondawi Bondawi - DRochana RamanayakaNessuna valutazione finora
- Dasis Bala AthiDocumento2 pagineDasis Bala AthiRochana RamanayakaNessuna valutazione finora
- ATHITHAYE MA - DMDocumento1 paginaATHITHAYE MA - DMRochana RamanayakaNessuna valutazione finora
- Chandra Mandale - CDocumento1 paginaChandra Mandale - CRochana RamanayakaNessuna valutazione finora
- Aradhana - G - 2Documento1 paginaAradhana - G - 2Rochana RamanayakaNessuna valutazione finora
- ATHA DURAKA HITIYATH OBA - FMDocumento1 paginaATHA DURAKA HITIYATH OBA - FMRochana RamanayakaNessuna valutazione finora
- AMANUSSAKAM - USSAPAN - emDocumento1 paginaAMANUSSAKAM - USSAPAN - emRochana RamanayakaNessuna valutazione finora
- Aradhana - G - 1Documento1 paginaAradhana - G - 1Rochana RamanayakaNessuna valutazione finora
- AYUBOWAN WASANAWAN - BBDocumento1 paginaAYUBOWAN WASANAWAN - BBRochana RamanayakaNessuna valutazione finora
- ASANI WASI ADAHALE - BMDocumento1 paginaASANI WASI ADAHALE - BMRochana RamanayakaNessuna valutazione finora
- Ape Bime (Ravana) - GDocumento1 paginaApe Bime (Ravana) - GRochana RamanayakaNessuna valutazione finora
- Khoya Khoya ChandDocumento2 pagineKhoya Khoya ChandRochana RamanayakaNessuna valutazione finora
- Gayanni - ADocumento1 paginaGayanni - ARochana RamanayakaNessuna valutazione finora
- Aharenna - DDocumento2 pagineAharenna - DRochana RamanayakaNessuna valutazione finora
- ALAKAMANDAWE THANI WI - CMDocumento1 paginaALAKAMANDAWE THANI WI - CMRochana RamanayakaNessuna valutazione finora
- Aduru Thumaneni - GDocumento1 paginaAduru Thumaneni - GRochana RamanayakaNessuna valutazione finora
- Adare Hara Giyata - DDocumento1 paginaAdare Hara Giyata - DRochana RamanayakaNessuna valutazione finora
- ADARE LASSANAMA - BMDocumento1 paginaADARE LASSANAMA - BMRochana RamanayakaNessuna valutazione finora
- ADARAYE RAN WIMANE - DMDocumento1 paginaADARAYE RAN WIMANE - DMRochana RamanayakaNessuna valutazione finora
- Abhimananiya Wu Nawodaye - FDocumento2 pagineAbhimananiya Wu Nawodaye - FRochana RamanayakaNessuna valutazione finora
- AAP KI NAZRON NE - CMDocumento1 paginaAAP KI NAZRON NE - CMRochana RamanayakaNessuna valutazione finora
- AAJ PHIR JEENE KI - BBMDocumento2 pagineAAJ PHIR JEENE KI - BBMRochana RamanayakaNessuna valutazione finora
- Computor ScienceDocumento12 pagineComputor ScienceRochana RamanayakaNessuna valutazione finora
- Aa Nila Nethu Sala - DDocumento1 paginaAa Nila Nethu Sala - DRochana RamanayakaNessuna valutazione finora
- Uploads Resources 116 Cello - LSTDocumento2 pagineUploads Resources 116 Cello - LSTRochana Ramanayaka100% (1)
- Abide With Me CelloDocumento1 paginaAbide With Me CelloRochana RamanayakaNessuna valutazione finora
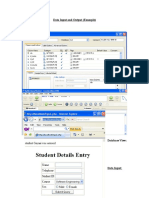
- Data Input and Output10122009Documento4 pagineData Input and Output10122009Rochana RamanayakaNessuna valutazione finora
- Computor ScienceDocumento4 pagineComputor ScienceRochana RamanayakaNessuna valutazione finora
- Software Requirement Specification Software EngineeringDocumento20 pagineSoftware Requirement Specification Software EngineeringRochana Ramanayaka100% (1)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- List of Indigenized MaterialsDocumento20 pagineList of Indigenized MaterialsBill VillonNessuna valutazione finora
- UntitledDocumento4 pagineUntitledDjunah ArellanoNessuna valutazione finora
- Demand ForecastingDocumento41 pagineDemand ForecastingPooja Surana100% (1)
- Statistische Auswertung WiederfindungsfunktionDocumento7 pagineStatistische Auswertung WiederfindungsfunktionMichael HuberNessuna valutazione finora
- IJRR74Documento8 pagineIJRR74LIRA LYN T. REBANGCOSNessuna valutazione finora
- Chapter 4 Statistial Process Control (SPC)Documento22 pagineChapter 4 Statistial Process Control (SPC)Yousab CreatorNessuna valutazione finora
- Bayesian Hierarchical Models - With Applications Using R - Congdon P.D. (CRC 2020) (2nd Ed.)Documento593 pagineBayesian Hierarchical Models - With Applications Using R - Congdon P.D. (CRC 2020) (2nd Ed.)Armai Zsolt100% (2)
- Trial SizeDocumento78 pagineTrial SizeOlga Constanza UñateNessuna valutazione finora
- (2013) Package Relaimpo PDFDocumento36 pagine(2013) Package Relaimpo PDFLyly MagnanNessuna valutazione finora
- BRMDocumento20 pagineBRMSourabh JainNessuna valutazione finora
- Measures of VariabilityDocumento13 pagineMeasures of VariabilitymochiNessuna valutazione finora
- Chapter Four: The Research DesignDocumento24 pagineChapter Four: The Research DesignAdonayt BezunehNessuna valutazione finora
- Experimental ResearchDocumento5 pagineExperimental ResearchKurniawanHidayatNessuna valutazione finora
- (Maths) - Normal DistributionDocumento4 pagine(Maths) - Normal Distributionanonymous accountNessuna valutazione finora
- STAT 125 HK Business Statistics Midterm ExamDocumento65 pagineSTAT 125 HK Business Statistics Midterm Examandrebaldwin100% (1)
- Frequencies Variables-1Documento7 pagineFrequencies Variables-1Nur AnjelinaNessuna valutazione finora
- Lecture # 2, Frequency, Class Limit & Class Boundaries & HistorgramsDocumento28 pagineLecture # 2, Frequency, Class Limit & Class Boundaries & HistorgramsArham RajpootNessuna valutazione finora
- Introduction To Design of Experiments: by Michael MonteroDocumento25 pagineIntroduction To Design of Experiments: by Michael Monteroducnguyenso100% (1)
- Metlit-02 Populasi, Sampel & Variabel - Prof. Dr. Sudigdo S, SpA (K)Documento55 pagineMetlit-02 Populasi, Sampel & Variabel - Prof. Dr. Sudigdo S, SpA (K)Laurencia LenyNessuna valutazione finora
- 2 - The Forecaster's Toolbox-ClassNotesDocumento25 pagine2 - The Forecaster's Toolbox-ClassNotesSushobhan DasNessuna valutazione finora
- Jirachaya HomeworkDocumento6 pagineJirachaya Homeworkจิรชยา จันทรพรมNessuna valutazione finora
- Statistics FundamentalsDocumento17 pagineStatistics FundamentalsWilliam NcubeNessuna valutazione finora
- Statistics Review Week 7Documento22 pagineStatistics Review Week 7Aldo CalderaNessuna valutazione finora
- Ass1 mth513Documento3 pagineAss1 mth513Muhammad Idrees0% (1)
- Capslet: Practical Research IiDocumento14 pagineCapslet: Practical Research IiAbby Bahim100% (1)
- Simple Linear Regression and Correlation Analysis: Chapter FiveDocumento5 pagineSimple Linear Regression and Correlation Analysis: Chapter FiveAmsalu WalelignNessuna valutazione finora
- Logistic RegressionDocumento24 pagineLogistic RegressionVeerpal KhairaNessuna valutazione finora
- Beyond The VIFDocumento23 pagineBeyond The VIFAidenNessuna valutazione finora
- Simple Six Sigma Calculator GATIDocumento5 pagineSimple Six Sigma Calculator GATIbambang haryantoNessuna valutazione finora
- Mann-Whitney U TestDocumento72 pagineMann-Whitney U TestHazel Mai CelinoNessuna valutazione finora