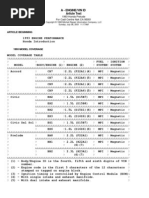
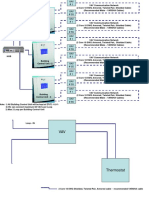
Potrebbero piacerti anche
- Amateur-Built Fabrication and Assembly Checklist (2011) (Helicopter)Documento9 pagineAmateur-Built Fabrication and Assembly Checklist (2011) (Helicopter)Bowtie41Nessuna valutazione finora
- 4x4 Tech KnowledgeDocumento369 pagine4x4 Tech KnowledgeMohd Hatta100% (1)
- 1996 2.4L (LD9) J-Car (With Auto Trans) Engine Diagnostic Parameters 96c24T - J - AeDocumento14 pagine1996 2.4L (LD9) J-Car (With Auto Trans) Engine Diagnostic Parameters 96c24T - J - AezmadwolfNessuna valutazione finora
- Dynamometer Testing of Caterpillar Engines (0781, 1000)Documento94 pagineDynamometer Testing of Caterpillar Engines (0781, 1000)David MercadoNessuna valutazione finora
- AW55-51 Troubleshooting LowDocumento7 pagineAW55-51 Troubleshooting Lowalexcus1539100% (1)
- CAT C13 2007 Service Bulletin (Cooling Sys, DPF, and Diagnostic Trouble Codes)Documento34 pagineCAT C13 2007 Service Bulletin (Cooling Sys, DPF, and Diagnostic Trouble Codes)Jonathan Carlson100% (4)
- Tesla Model X Full Collection 2015 2019 Service Repair Manuals Part Catalog DVDDocumento25 pagineTesla Model X Full Collection 2015 2019 Service Repair Manuals Part Catalog DVDbrendamcguire120300mjg100% (112)
- Tabla de Correccion de CombustibleDocumento99 pagineTabla de Correccion de CombustibleMartina FambNessuna valutazione finora
- 2005 Diesel Ref Manual PDFDocumento68 pagine2005 Diesel Ref Manual PDFWilmer P MendozaNessuna valutazione finora
- General Automotive Repair Revenues World Summary: Market Values & Financials by CountryDa EverandGeneral Automotive Repair Revenues World Summary: Market Values & Financials by CountryNessuna valutazione finora
- LCT Engines Service Man 208ccDocumento23 pagineLCT Engines Service Man 208ccmowerman33Nessuna valutazione finora
- Diesel Engine GuideDocumento19 pagineDiesel Engine GuidePadmakumarVariorNessuna valutazione finora
- Pending TicketsDocumento6 paginePending TicketsMonali HedauNessuna valutazione finora
- Ecus CodeDocumento6 pagineEcus CodePaulo Gonçalves62% (13)
- Jacobs Brake Application Guide CaterpillarDocumento8 pagineJacobs Brake Application Guide Caterpillarviemey1952100% (2)
- Brake, Front End & Wheel Alignment Revenues World Summary: Market Values & Financials by CountryDa EverandBrake, Front End & Wheel Alignment Revenues World Summary: Market Values & Financials by CountryNessuna valutazione finora
- En Us c5 2000Documento259 pagineEn Us c5 2000Zoran Bozinovic75% (4)
- NUMBER: 6-04-10 S.M. REF.: Listed in Table ENGINE: EPA07 DD Platform DATE: June 2010Documento4 pagineNUMBER: 6-04-10 S.M. REF.: Listed in Table ENGINE: EPA07 DD Platform DATE: June 2010Cuong DinhNessuna valutazione finora
- 2013 - Magnaflow California CatalogDocumento848 pagine2013 - Magnaflow California CatalogMQPNessuna valutazione finora
- Horsepower Ver3Documento2 pagineHorsepower Ver3rike.spNessuna valutazione finora
- 2005mustang SpecsDocumento37 pagine2005mustang SpecsTetsunari KodaNessuna valutazione finora
- Docu Volvo Vida DDocumento8 pagineDocu Volvo Vida Dluis100% (1)
- C15-Berlingo 2005Documento339 pagineC15-Berlingo 2005ionmocanu100% (5)
- (SELD0179-11) 3500 Engines and Short Blocks (Peso Motores CAT)Documento4 pagine(SELD0179-11) 3500 Engines and Short Blocks (Peso Motores CAT)victor.cipriani100% (1)
- 2014 Chevrolet Performance CatalogDocumento384 pagine2014 Chevrolet Performance Catalogsantihdez100% (1)
- Function List of Car BrainDocumento39 pagineFunction List of Car BrainBogdan PopNessuna valutazione finora
- 2013 CP Catalog (02.01.13)Documento388 pagine2013 CP Catalog (02.01.13)Mauricio Goku VaLondNessuna valutazione finora
- Designing and Tuning High-Performance Fuel Injection SystemsDa EverandDesigning and Tuning High-Performance Fuel Injection SystemsValutazione: 3.5 su 5 stelle3.5/5 (7)
- CTM400 - 19 - 02JUN05 Rep 9 0Documento420 pagineCTM400 - 19 - 02JUN05 Rep 9 0Antony Moreno100% (4)
- Troubleshooting and Repair of Diesel EnginesDa EverandTroubleshooting and Repair of Diesel EnginesValutazione: 1.5 su 5 stelle1.5/5 (2)
- Dynamic Simulation in Motorsport DiFina TREngineering GermanyDocumento27 pagineDynamic Simulation in Motorsport DiFina TREngineering GermanyJohnMerrNessuna valutazione finora
- AW55-51 TroubleshootingDocumento7 pagineAW55-51 Troubleshootingalexcus15390% (3)
- C9 Engine BrochureDocumento6 pagineC9 Engine Brochurebaghermanesh135450% (2)
- C9 Brochure LEDT7015-01Documento6 pagineC9 Brochure LEDT7015-01DraganNessuna valutazione finora
- Cat Forklift Dpl40 Service Operation Maintenance ManualDocumento28 pagineCat Forklift Dpl40 Service Operation Maintenance Manualxycedfsf100% (34)
- 1996-1998 Polaris Service ManualDocumento633 pagine1996-1998 Polaris Service Manualdanielsantacruz169% (16)
- Specifications Katalog XJDocumento14 pagineSpecifications Katalog XJddg1966Nessuna valutazione finora
- 797F HAA - Meeting Guide PDFDocumento368 pagine797F HAA - Meeting Guide PDFGustavo Sandoval Moscoso100% (2)
- TSB WK PDFDocumento4 pagineTSB WK PDFfulltransmissionNessuna valutazione finora
- 1984 GMC Light Duty Trucks Service ManualDocumento1.746 pagine1984 GMC Light Duty Trucks Service ManualRoberto Stefani94% (17)
- 2012 PassatDocumento44 pagine2012 PassatMcGiver990100% (1)
- Cars - Transmission New Automatic Transmission 722.9 NAG2 (7-Speed) Diagnosis, Repair Advanced TrainingDocumento60 pagineCars - Transmission New Automatic Transmission 722.9 NAG2 (7-Speed) Diagnosis, Repair Advanced TrainingTuấn Neo100% (1)
- Man BWDocumento24 pagineMan BWDhanie KhruxzNessuna valutazione finora
- Honda Prelude IV (92-96) - Engine VIN IDDocumento3 pagineHonda Prelude IV (92-96) - Engine VIN IDTor Warut100% (1)
- 15045.11 GM Braking SystemsDocumento75 pagine15045.11 GM Braking SystemsClaudio ShimamotoNessuna valutazione finora
- Western Star Maintenance ManualDocumento164 pagineWestern Star Maintenance Manualtransteven9383% (6)
- Aerodynamic Design Considerations of A Formula 1 Racing CarDocumento4 pagineAerodynamic Design Considerations of A Formula 1 Racing CarVyssionNessuna valutazione finora
- Lean Manufacturing and Six SegmaDocumento22 pagineLean Manufacturing and Six Segmashahid_ali21Nessuna valutazione finora
- Vol28 Aeromotive Catalog RedDocumento49 pagineVol28 Aeromotive Catalog RedgitmeNessuna valutazione finora
- How to Use and Upgrade to GM Gen III LS-Series Powertrain Control SystemsDa EverandHow to Use and Upgrade to GM Gen III LS-Series Powertrain Control SystemsValutazione: 3.5 su 5 stelle3.5/5 (4)
- How to Swap GM LT-Series Engines into Almost AnythingDa EverandHow to Swap GM LT-Series Engines into Almost AnythingNessuna valutazione finora
- LS Swaps: How to Swap GM LS Engines into Almost AnythingDa EverandLS Swaps: How to Swap GM LS Engines into Almost AnythingValutazione: 3.5 su 5 stelle3.5/5 (2)
- How to Rebuild & Modify Ford C4 & C6 Automatic TransmissionsDa EverandHow to Rebuild & Modify Ford C4 & C6 Automatic TransmissionsValutazione: 5 su 5 stelle5/5 (5)
- Fuel Pumps & Fuel Tanks (C.V. OE & Aftermarket) World Summary: Market Values & Financials by CountryDa EverandFuel Pumps & Fuel Tanks (C.V. OE & Aftermarket) World Summary: Market Values & Financials by CountryNessuna valutazione finora
- Air Brakes (C.V. OE & Aftermarket) World Summary: Market Values & Financials by CountryDa EverandAir Brakes (C.V. OE & Aftermarket) World Summary: Market Values & Financials by CountryNessuna valutazione finora
- Automobile & Motor Vehicle Wholesale Revenues World Summary: Market Values & Financials by CountryDa EverandAutomobile & Motor Vehicle Wholesale Revenues World Summary: Market Values & Financials by CountryNessuna valutazione finora
- 16k Block Not Real SolutionDocumento7 pagine16k Block Not Real SolutionpentiumonceNessuna valutazione finora
- 11gR2 Clusterware and Grid Home - What You Need To KnowDocumento19 pagine11gR2 Clusterware and Grid Home - What You Need To KnowpentiumonceNessuna valutazione finora
- Check The Undocumented Oracle ParameterDocumento1 paginaCheck The Undocumented Oracle ParameterpentiumonceNessuna valutazione finora
- Alter Table - Partition ExamplesDocumento3 pagineAlter Table - Partition ExamplespentiumonceNessuna valutazione finora
- Oracle Report User Guide 11g b32122Documento778 pagineOracle Report User Guide 11g b32122Arshad HussainNessuna valutazione finora
- Oracle Report User Guide 11g b32122Documento778 pagineOracle Report User Guide 11g b32122Arshad HussainNessuna valutazione finora
- Database CloudDocumento11 pagineDatabase CloudpentiumonceNessuna valutazione finora
- Oracle Reports Tutorial 11g R1 - b32123Documento60 pagineOracle Reports Tutorial 11g R1 - b32123tranhieu5959Nessuna valutazione finora
- Oracle Database 12c New FeaturesDocumento26 pagineOracle Database 12c New Featurespentiumonce100% (1)
- ps3q05 20050193 Mahmood SOEDocumento5 pagineps3q05 20050193 Mahmood SOEJose Luis CollantesNessuna valutazione finora
- RAC Backup and Recovery Using RMANDocumento7 pagineRAC Backup and Recovery Using RMANpentiumonceNessuna valutazione finora
- Free Spanning Analysis of Offshore PipelinesDocumento14 pagineFree Spanning Analysis of Offshore PipelinesMaringan JuliverNessuna valutazione finora
- Converção de AçosDocumento16 pagineConverção de Açoshelton dziedzicNessuna valutazione finora
- Nelson Stud CatalogDocumento110 pagineNelson Stud CatalogAustin SollockNessuna valutazione finora
- Brushbond Ultraflex BFLDocumento2 pagineBrushbond Ultraflex BFLpeashNessuna valutazione finora
- Unit 1 Vehicle Components - BackDocumento20 pagineUnit 1 Vehicle Components - BackCarlos CabreraNessuna valutazione finora
- DevOps For VMware Administrators (VMware Press Technology) - 1-321Documento321 pagineDevOps For VMware Administrators (VMware Press Technology) - 1-321mailboxrohitsharma100% (1)
- Aerobic Respiration in PeasDocumento2 pagineAerobic Respiration in PeasMatt Schiavo100% (1)
- Energy Saving Basics - EsdsDocumento40 pagineEnergy Saving Basics - Esdsapi-238581599Nessuna valutazione finora
- 7-Strengthening Mechanisms - SlidesDocumento74 pagine7-Strengthening Mechanisms - SlidesRyan TorresNessuna valutazione finora
- Epoxylite TSA 220 - TDS - 2008Documento3 pagineEpoxylite TSA 220 - TDS - 2008Anonymous sAmJfcVNessuna valutazione finora
- Erpi Admin 11123510Documento416 pagineErpi Admin 11123510prakash9565Nessuna valutazione finora
- $MP 026 18Documento12 pagine$MP 026 18Safura BegumNessuna valutazione finora
- Technological University of The Philippines ManilaDocumento1 paginaTechnological University of The Philippines Manilalesterginno de guzmanNessuna valutazione finora
- JSA Basket TransferDocumento3 pagineJSA Basket TransferCristina Rican100% (1)
- Design and Analysis For Crane HookDocumento6 pagineDesign and Analysis For Crane Hookmukeshsonava076314Nessuna valutazione finora
- Instructions VbamDocumento2 pagineInstructions VbamAustin Yu LiuNessuna valutazione finora
- Kleene ClosureDocumento6 pagineKleene ClosurepbhmmmmNessuna valutazione finora
- Aluminium Aluminum 6070 Alloy (UNS A96070)Documento2 pagineAluminium Aluminum 6070 Alloy (UNS A96070)HARIPRASATH PNessuna valutazione finora
- Final Fine Black Sport 06.12.23Documento15 pagineFinal Fine Black Sport 06.12.23NATWAR PRAJAPATINessuna valutazione finora
- Settling Tank DecantDocumento23 pagineSettling Tank Decantjvan migvelNessuna valutazione finora
- Position - List - Tank 17 11 2023Documento8 paginePosition - List - Tank 17 11 2023simionalex1987Nessuna valutazione finora
- VAV CablingDocumento2 pagineVAV Cablingsripriya01Nessuna valutazione finora
- Syllabus Compendium For PCN Aerospace Sector ExaminationsDocumento27 pagineSyllabus Compendium For PCN Aerospace Sector ExaminationstomcanNessuna valutazione finora
- IntegratingBIMTechnologyintoLA (2014) PDFDocumento115 pagineIntegratingBIMTechnologyintoLA (2014) PDFArnaldo RuizNessuna valutazione finora
- Silo Culture at SonyDocumento2 pagineSilo Culture at Sonydasarup24123Nessuna valutazione finora
- Polypac BalseleDocumento18 paginePolypac BalseleRenato GouveiaNessuna valutazione finora
- Geographic Information System of Public Complaint Testing Based On Mobile WebDocumento2 pagineGeographic Information System of Public Complaint Testing Based On Mobile WebArya HardinataNessuna valutazione finora
- HFC1508EN - Hi-Force Condensed Catalogue PDFDocumento76 pagineHFC1508EN - Hi-Force Condensed Catalogue PDFVladimir ShepelNessuna valutazione finora
- Gapura Company Profile - 17mar17Documento43 pagineGapura Company Profile - 17mar17als izmiNessuna valutazione finora
- InteliMains 210 MC - Global Guide PDFDocumento637 pagineInteliMains 210 MC - Global Guide PDFHakim GOURAIANessuna valutazione finora