Potrebbero piacerti anche
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedDa EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNessuna valutazione finora
- Service Manual HP 602Documento91 pagineService Manual HP 602Danny Gonzalez del ValleNessuna valutazione finora
- Kitchen Garden - December 2015Documento116 pagineKitchen Garden - December 2015reinaldoopus100% (2)
- SAP interface programming with RFC and VBA: Edit SAP data with MS AccessDa EverandSAP interface programming with RFC and VBA: Edit SAP data with MS AccessNessuna valutazione finora
- Questions On Logic SynthesisDocumento11 pagineQuestions On Logic SynthesisrAM89% (9)
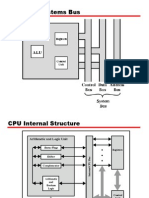
- CPU Structure and FunctionDocumento30 pagineCPU Structure and Functiondbunet100% (1)
- Practical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationDa EverandPractical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationNessuna valutazione finora
- (Mathematica) The Mathematica® Book 5th Ed - Stephen Wolfram (2003)Documento1.301 pagine(Mathematica) The Mathematica® Book 5th Ed - Stephen Wolfram (2003)reinaldoopus100% (2)
- Intel x86 Architecture 1326950278 Phpapp02 120118231851 Phpapp02Documento71 pagineIntel x86 Architecture 1326950278 Phpapp02 120118231851 Phpapp02krishnadevanur100% (1)
- 1.3.1.6 Worksheet - Build A Specialized Computer SystemDocumento6 pagine1.3.1.6 Worksheet - Build A Specialized Computer Systemelias80% (5)
- William Stallings Computer Organization and Architecture: CPU Structure and FunctionDocumento22 pagineWilliam Stallings Computer Organization and Architecture: CPU Structure and FunctionGabrielNessuna valutazione finora
- Group 6 Cpu Design PresentationDocumento50 pagineGroup 6 Cpu Design PresentationFerry AriNessuna valutazione finora
- Top Level View of Computer Function and InterconnectionDocumento35 pagineTop Level View of Computer Function and InterconnectionWaseem HaiderNessuna valutazione finora
- Processor OrganizationDocumento55 pagineProcessor OrganizationMinoshini Fonseka100% (1)
- CH12 CPU Structure and FunctionDocumento44 pagineCH12 CPU Structure and FunctionUsha PrasannaNessuna valutazione finora
- CPU Structure and FunctionsDocumento39 pagineCPU Structure and FunctionsNICE ONENessuna valutazione finora
- William Stallings Computer Organization and Architecture: Chapter 11 - 11.3 CPU Structure and FunctionDocumento27 pagineWilliam Stallings Computer Organization and Architecture: Chapter 11 - 11.3 CPU Structure and FunctionYasyrNessuna valutazione finora
- Chapter 2 Lecture 4 and 5Documento56 pagineChapter 2 Lecture 4 and 5Gebrie BeleteNessuna valutazione finora
- CH01-Computer System OverviewDocumento36 pagineCH01-Computer System OverviewViveekdeep SinghNessuna valutazione finora
- CPU Structure & FunctionsDocumento44 pagineCPU Structure & FunctionsMohammed UsmanNessuna valutazione finora
- CPU With Systems BusDocumento35 pagineCPU With Systems BusTanafe33% (3)
- Chapter 2 Part FourDocumento76 pagineChapter 2 Part FoursileNessuna valutazione finora
- Unit 2Documento60 pagineUnit 2Ashish kumarNessuna valutazione finora
- Draw The Block Diagram of Von Neumann Architecture and Explain About Its Parts in Brief AnswerDocumento7 pagineDraw The Block Diagram of Von Neumann Architecture and Explain About Its Parts in Brief AnswerhayerpaNessuna valutazione finora
- IAS & MIPS RateDocumento42 pagineIAS & MIPS RateWaseem HaiderNessuna valutazione finora
- Lecture 5 - CPU DesignDocumento20 pagineLecture 5 - CPU Designnoberth nikombolweNessuna valutazione finora
- Organisasi Dan Arsitektur Komputer: Ajeng Savitri Puspaningrum, M.Kom Pertemuan 8Documento21 pagineOrganisasi Dan Arsitektur Komputer: Ajeng Savitri Puspaningrum, M.Kom Pertemuan 8YuanserenadaNessuna valutazione finora
- CH 3 95Documento46 pagineCH 3 95theo dominic silvosaNessuna valutazione finora
- Isa 1Documento13 pagineIsa 1awais_alii56Nessuna valutazione finora
- Lecture1 ComputerSystemOverviewDocumento66 pagineLecture1 ComputerSystemOverviewAloyceNessuna valutazione finora
- William Stallings Computer Organization and Architecture: Reduced Instruction Set ComputersDocumento39 pagineWilliam Stallings Computer Organization and Architecture: Reduced Instruction Set ComputersreinaldoopusNessuna valutazione finora
- Organisasi Dan Arsitektur Komputer - 8Documento18 pagineOrganisasi Dan Arsitektur Komputer - 8YuanserenadaNessuna valutazione finora
- 12 - Processor Structure and FunctionDocumento73 pagine12 - Processor Structure and FunctionRao FaisalNessuna valutazione finora
- Module 5Documento9 pagineModule 5Saugat TripathiNessuna valutazione finora
- CPU Structure and Functions: Processor OrganizationDocumento5 pagineCPU Structure and Functions: Processor OrganizationShahzadNessuna valutazione finora
- Unit 2 The CPU and Register Org.Documento11 pagineUnit 2 The CPU and Register Org.shashank2001tewariNessuna valutazione finora
- Computer Memory By: Manzoor Ali SolangiDocumento41 pagineComputer Memory By: Manzoor Ali Solangiمنظور سولنگیNessuna valutazione finora
- Assignment 4: Course Instructor / Lab EngineerDocumento8 pagineAssignment 4: Course Instructor / Lab EngineerNitasha HumaNessuna valutazione finora
- William Stallings Computer Organization and Architecture: System BusesDocumento47 pagineWilliam Stallings Computer Organization and Architecture: System BusesreinaldoopusNessuna valutazione finora
- Perkuliahan 12 - Organisasi Dan Arsitektur Komputer - Control UnitDocumento41 paginePerkuliahan 12 - Organisasi Dan Arsitektur Komputer - Control UnitMimar Mirhat HidayatNessuna valutazione finora
- Informatica PDFDocumento38 pagineInformatica PDFKoteswararao TirumalasettyNessuna valutazione finora
- Fundamentals of Processor Design: Using Figures From by Hamblen and FurmanDocumento35 pagineFundamentals of Processor Design: Using Figures From by Hamblen and Furmanwilliamjamir2295Nessuna valutazione finora
- Cpu 1Documento6 pagineCpu 1mayan nelsonNessuna valutazione finora
- Pipelining With NumericalDocumento55 paginePipelining With NumericalpbgamingbeastNessuna valutazione finora
- Individual Assigment CoaDocumento8 pagineIndividual Assigment Coacheruuasrat30Nessuna valutazione finora
- Computer System: Operating Systems: Internals and Design PrinciplesDocumento62 pagineComputer System: Operating Systems: Internals and Design PrinciplesRamadan ElhendawyNessuna valutazione finora
- EC303 - Chapter 1 Computer Architecture OrganizationDocumento61 pagineEC303 - Chapter 1 Computer Architecture OrganizationChinNessuna valutazione finora
- Processor Organisation and ArchitectureDocumento25 pagineProcessor Organisation and Architecturejontyrhodes1012237Nessuna valutazione finora
- Processor Basics: Nizwa College of Technology Department of IT Computer ArchitectureDocumento30 pagineProcessor Basics: Nizwa College of Technology Department of IT Computer Architecturealinma76Nessuna valutazione finora
- Instruction Set and Addressing ModesDocumento14 pagineInstruction Set and Addressing ModesAastha KohliNessuna valutazione finora
- Computer Organization: Virtual MemoryDocumento26 pagineComputer Organization: Virtual Memorychuks felix michaelNessuna valutazione finora
- CMP 3011 - Unit 2 - CPUDocumento186 pagineCMP 3011 - Unit 2 - CPUSabrina JohnsonNessuna valutazione finora
- Computer System: Operating Systems: Internals and Design PrinciplesDocumento56 pagineComputer System: Operating Systems: Internals and Design PrinciplesHurrain QueenNessuna valutazione finora
- Computer Architecture: Computer Architecture Refers To Those Attributes of A System Visible To ADocumento6 pagineComputer Architecture: Computer Architecture Refers To Those Attributes of A System Visible To AKobinaNessuna valutazione finora
- Task Switching:: JMP Call JMP Call Iret JMP Call IretDocumento19 pagineTask Switching:: JMP Call JMP Call Iret JMP Call IretAshish PatilNessuna valutazione finora
- 03-Top Level View of Computer Function and Interconnection-Update-2022!09!21Documento73 pagine03-Top Level View of Computer Function and Interconnection-Update-2022!09!21Haikal GustiansyahNessuna valutazione finora
- Cyan 2800398239029h09fn0ivj0vcjb0Documento16 pagineCyan 2800398239029h09fn0ivj0vcjb0Anonymous zWBss8LKNessuna valutazione finora
- Unit 4Documento182 pagineUnit 4Vamsi KrishnaNessuna valutazione finora
- CSWDocumento6 pagineCSWBurtNessuna valutazione finora
- Chapter 3 Central Processing Unit: 3.1 CPU Organization and StructureDocumento8 pagineChapter 3 Central Processing Unit: 3.1 CPU Organization and StructureLui PascherNessuna valutazione finora
- Mca 301Documento7 pagineMca 301logicballiaNessuna valutazione finora
- HW2 Operating SystemsDocumento9 pagineHW2 Operating SystemsSainadh GodenaNessuna valutazione finora
- STW120CT Computer Architecture and Networks: (Instruction Pipelining)Documento24 pagineSTW120CT Computer Architecture and Networks: (Instruction Pipelining)BJ AcharyaNessuna valutazione finora
- William Stallings Computer Organization and Architecture: Instruction Level Parallelism and Superscalar ProcessorsDocumento28 pagineWilliam Stallings Computer Organization and Architecture: Instruction Level Parallelism and Superscalar ProcessorsreinaldoopusNessuna valutazione finora
- William Stallings Computer Organization and Architecture: Parallel ProcessingDocumento40 pagineWilliam Stallings Computer Organization and Architecture: Parallel ProcessingreinaldoopusNessuna valutazione finora
- William Stallings Computer Organization and Architecture: Reduced Instruction Set ComputersDocumento39 pagineWilliam Stallings Computer Organization and Architecture: Reduced Instruction Set ComputersreinaldoopusNessuna valutazione finora
- William Stallings Computer Organization and Architecture: Instruction Sets: Characteristics and FunctionsDocumento30 pagineWilliam Stallings Computer Organization and Architecture: Instruction Sets: Characteristics and FunctionsreinaldoopusNessuna valutazione finora
- William Stallings Computer Organization and Architecture: Instruction Sets: Addressing Modes and FormatsDocumento25 pagineWilliam Stallings Computer Organization and Architecture: Instruction Sets: Addressing Modes and FormatsreinaldoopusNessuna valutazione finora
- William Stallings Computer Organization and Architecture: System BusesDocumento47 pagineWilliam Stallings Computer Organization and Architecture: System BusesreinaldoopusNessuna valutazione finora
- William Stallings Computer Organization and ArchitectureDocumento37 pagineWilliam Stallings Computer Organization and ArchitecturereinaldoopusNessuna valutazione finora
- William Stallings Computer Organization and Architecture: Operating System SupportDocumento41 pagineWilliam Stallings Computer Organization and Architecture: Operating System SupportreinaldoopusNessuna valutazione finora
- William Stallings Computer Organization and Architecture: Input/OutputDocumento53 pagineWilliam Stallings Computer Organization and Architecture: Input/OutputreinaldoopusNessuna valutazione finora
- William Stallings Computer Organization and Architecture: Internal MemoryDocumento60 pagineWilliam Stallings Computer Organization and Architecture: Internal MemoryreinaldoopusNessuna valutazione finora
- William Stallings Computer Organization and ArchitectureDocumento26 pagineWilliam Stallings Computer Organization and ArchitecturereinaldoopusNessuna valutazione finora
- Introduction To L TEX: You're A Luvely AudienceDocumento17 pagineIntroduction To L TEX: You're A Luvely AudiencereinaldoopusNessuna valutazione finora
- VMware VSAN Nutanix Quick Positioning and Battle Card enDocumento3 pagineVMware VSAN Nutanix Quick Positioning and Battle Card enRphcostaNessuna valutazione finora
- DAE Civil Computer Practical COMP-111Documento9 pagineDAE Civil Computer Practical COMP-111MuhammadIrfanNessuna valutazione finora
- Stanford Dash MultiprocessorDocumento19 pagineStanford Dash MultiprocessorWinner WinnerNessuna valutazione finora
- Sison, Winnie Rose B - Learning-Activity - 1Documento5 pagineSison, Winnie Rose B - Learning-Activity - 1Winnie SisonNessuna valutazione finora
- PCS-978 Transformer Protection Instruction Manual SupplementDocumento30 paginePCS-978 Transformer Protection Instruction Manual SupplementBenigno Sayaboc TaradelNessuna valutazione finora
- 1111 C Programming p.47Documento446 pagine1111 C Programming p.47Paras DorleNessuna valutazione finora
- Embedded Systems PIC16FDocumento100 pagineEmbedded Systems PIC16FmigadNessuna valutazione finora
- Iot Based Automatic College Gong: S.Arockia Ranjith Kumar, R.Glarwin, M.Gowthamaraj, M.K.Vijayanainar, G.ShunmugalakshmiDocumento3 pagineIot Based Automatic College Gong: S.Arockia Ranjith Kumar, R.Glarwin, M.Gowthamaraj, M.K.Vijayanainar, G.ShunmugalakshmiMohseen SNessuna valutazione finora
- Crank Wheel Pulser SoftwareDocumento5 pagineCrank Wheel Pulser SoftwarePercy ZarateNessuna valutazione finora
- ENPUH-302 User's ManualDocumento14 pagineENPUH-302 User's ManualCarlos Alberto López LaraNessuna valutazione finora
- EnGenius TutorialDocumento7 pagineEnGenius TutorialFredy Turpo TiconaNessuna valutazione finora
- Xi Ip 2013-14Documento136 pagineXi Ip 2013-14Ravi JhaNessuna valutazione finora
- Design StickerDocumento14 pagineDesign StickerRiwi WidakdoNessuna valutazione finora
- OS 01 IntroductionDocumento34 pagineOS 01 IntroductionSUSHANTA SORENNessuna valutazione finora
- Gefran Software: Gfe PressDocumento6 pagineGefran Software: Gfe Press97g897g8Nessuna valutazione finora
- MQXUSBDEVAPIDocumento32 pagineMQXUSBDEVAPIwonderxNessuna valutazione finora
- Project StargateDocumento14 pagineProject StargategeekboyNessuna valutazione finora
- Summer Sale 2 PDFDocumento4 pagineSummer Sale 2 PDFAnonymous z5zV3K3NdeNessuna valutazione finora
- Sim900 HardwareDocumento22 pagineSim900 HardwareStefan EnevNessuna valutazione finora
- Positioning The ConneCtor 2001 Case (Positioning)Documento9 paginePositioning The ConneCtor 2001 Case (Positioning)billy930% (2)
- CCLDocumento13 pagineCCLNasis DerejeNessuna valutazione finora
- Graphics Card Hierarchy Chart Geforce Radeon IntelDocumento4 pagineGraphics Card Hierarchy Chart Geforce Radeon IntelInsightKindnessNessuna valutazione finora
- SLG84401 DatasheetDocumento21 pagineSLG84401 DatasheetSergey MorozNessuna valutazione finora
- NEC Datasheet P402-EnglishDocumento2 pagineNEC Datasheet P402-EnglishbuzduceanuNessuna valutazione finora
- XPC Target™ Release NotesDocumento108 pagineXPC Target™ Release NotesAhmed58seribegawanNessuna valutazione finora
- Ds Eternus Lt260 WW enDocumento5 pagineDs Eternus Lt260 WW enAntónio MartinsNessuna valutazione finora
- Chapter - 1 Basic Structure of Computers: 1.1 Computer TypesDocumento46 pagineChapter - 1 Basic Structure of Computers: 1.1 Computer TypesTameem AhmedNessuna valutazione finora