Potrebbero piacerti anche
- Chemometrics and Intelligent Laboratory Systems: 10.1016/j.chemolab.2016.07.011Documento26 pagineChemometrics and Intelligent Laboratory Systems: 10.1016/j.chemolab.2016.07.011JessicaNessuna valutazione finora
- Averaged and Weighted Average Partial Least Squares: M.H. Zhang, Q.S. Xu, D.L. MassartDocumento11 pagineAveraged and Weighted Average Partial Least Squares: M.H. Zhang, Q.S. Xu, D.L. MassartAnonymous cVJKeIOLBNNessuna valutazione finora
- Urkedal,' A.T.: PaperDocumento16 pagineUrkedal,' A.T.: PaperRosa K Chang HNessuna valutazione finora
- Fitting Nonlinear Calibration Curves No Models PerDocumento17 pagineFitting Nonlinear Calibration Curves No Models PerLuis LahuertaNessuna valutazione finora
- Va41 3 405Documento6 pagineVa41 3 405bdalcin5512Nessuna valutazione finora
- Validation of The Calibration Procedure in Atomic Absorption Spectrometric MethodsDocumento10 pagineValidation of The Calibration Procedure in Atomic Absorption Spectrometric MethodsaureaborosNessuna valutazione finora
- Bootstrap confidence intervals for reservoir model selection techniquesDocumento25 pagineBootstrap confidence intervals for reservoir model selection techniquesregarcia81Nessuna valutazione finora
- Ranova Help Tcm18-242064Documento20 pagineRanova Help Tcm18-242064BruzziNessuna valutazione finora
- Prediction Methods in The Presence of MulticollinearityDocumento17 paginePrediction Methods in The Presence of MulticollinearityKhaja Riazuddin Nawaz MohammedNessuna valutazione finora
- Results and Conclusions: 9.1 Summary of The ResultsDocumento8 pagineResults and Conclusions: 9.1 Summary of The ResultsNova MejisienNessuna valutazione finora
- Using Additional Standards For Increasing The Accuracy of Quantitative Chromatographic AnalysisDocumento10 pagineUsing Additional Standards For Increasing The Accuracy of Quantitative Chromatographic AnalysisTiar_Rahman_9553Nessuna valutazione finora
- A Comparison of SIFT, PCA-SIFT and SURF: Computer Graphics Lab, Chonbuk National University, Jeonju 561-756, South KoreaDocumento10 pagineA Comparison of SIFT, PCA-SIFT and SURF: Computer Graphics Lab, Chonbuk National University, Jeonju 561-756, South Koreamatkhau01Nessuna valutazione finora
- Performance Indication Improvement For A Proficiency TestingDocumento5 paginePerformance Indication Improvement For A Proficiency TestingManvel EnriqueNessuna valutazione finora
- Estimating Replicability of Classifier Learning ExperimentsDocumento11 pagineEstimating Replicability of Classifier Learning Experimentssmunoz443x9066Nessuna valutazione finora
- Ball in 1992Documento23 pagineBall in 1992Hossein HaddadpourNessuna valutazione finora
- Cross ValidationDocumento6 pagineCross ValidationSantosh ButleNessuna valutazione finora
- Machine Learning Book Review: An Algorithmic PerspectiveDocumento4 pagineMachine Learning Book Review: An Algorithmic PerspectivePrajwal GowdaNessuna valutazione finora
- SVM Quantile DNADocumento9 pagineSVM Quantile DNAXiao YaoNessuna valutazione finora
- Cross Validation LN 12Documento11 pagineCross Validation LN 12M S PrasadNessuna valutazione finora
- Cross Validation LN 12Documento11 pagineCross Validation LN 12M S PrasadNessuna valutazione finora
- BAYREUTHDocumento15 pagineBAYREUTHAjitNessuna valutazione finora
- Algorithms-09-00046 (Path Based Four Uci Datasets)Documento13 pagineAlgorithms-09-00046 (Path Based Four Uci Datasets)Khin MyintNessuna valutazione finora
- Niels-Peter Vest Nielsen, 1998Documento19 pagineNiels-Peter Vest Nielsen, 1998Laura MonicaNessuna valutazione finora
- An Efficient Method For Paired-Comparison: D. Amnon Silverstein Joyce E. FarrellDocumento15 pagineAn Efficient Method For Paired-Comparison: D. Amnon Silverstein Joyce E. FarrellSharif UllahNessuna valutazione finora
- CHEMOMETRICS and STATISTICS Multivariate Classification Techniques-21-27Documento7 pagineCHEMOMETRICS and STATISTICS Multivariate Classification Techniques-21-27Jose GarciaNessuna valutazione finora
- K Means SpectralDocumento10 pagineK Means SpectralEthan Carres HidalgoNessuna valutazione finora
- 1 s2.0 S0003267017306967 MainDocumento11 pagine1 s2.0 S0003267017306967 Mainmuhammad reza mahendraNessuna valutazione finora
- F.-M. Schleif, T. Villmann and B. Hammer - Prototype Based Fuzzy Classification in Clinical ProteomicsDocumento20 pagineF.-M. Schleif, T. Villmann and B. Hammer - Prototype Based Fuzzy Classification in Clinical ProteomicsGrettszNessuna valutazione finora
- Zhong - 2005 - Efficient Online Spherical K-Means ClusteringDocumento6 pagineZhong - 2005 - Efficient Online Spherical K-Means ClusteringswarmbeesNessuna valutazione finora
- Dechter Constraint ProcessingDocumento40 pagineDechter Constraint Processingnani subrNessuna valutazione finora
- Remotesensing 09 01113 v2Documento24 pagineRemotesensing 09 01113 v2Débora PlácidoNessuna valutazione finora
- Comparative Studies On Some Metrics For External Validation of QSPR ModelsDocumento13 pagineComparative Studies On Some Metrics For External Validation of QSPR ModelsPace RaditNessuna valutazione finora
- Gaussian Kernel Optimization For Pattern Classification: Jie Wang, Haiping Lu, Juwei LuDocumento28 pagineGaussian Kernel Optimization For Pattern Classification: Jie Wang, Haiping Lu, Juwei LuAnshul SuneriNessuna valutazione finora
- A Hybrid Algorithm Based On Cuckoo Search and Differential Evolution For Numerical OptimizationDocumento8 pagineA Hybrid Algorithm Based On Cuckoo Search and Differential Evolution For Numerical OptimizationrasminojNessuna valutazione finora
- A Distance-Based Kernel For Classification Via Support Vector Machines - PMC-19Documento1 paginaA Distance-Based Kernel For Classification Via Support Vector Machines - PMC-19jefferyleclercNessuna valutazione finora
- OPTIMIZE PARAMETER ESTIMATION IN GEOTECHNICAL MODELINGDocumento23 pagineOPTIMIZE PARAMETER ESTIMATION IN GEOTECHNICAL MODELINGHUGINessuna valutazione finora
- Sparkscore: Leveraging Apache Spark For Distributed Genomic InferenceDocumento8 pagineSparkscore: Leveraging Apache Spark For Distributed Genomic InferenceMónicaPitaLópezNessuna valutazione finora
- Journal of Petroleum Science and Engineering: Kyungbook Lee, Jungtek Lim, Jonggeun Choe, Hyun Suk LeeDocumento11 pagineJournal of Petroleum Science and Engineering: Kyungbook Lee, Jungtek Lim, Jonggeun Choe, Hyun Suk LeeYarisol Rivera ChàvezNessuna valutazione finora
- Alehandro Lumentah 210211010188 Assignment09Documento10 pagineAlehandro Lumentah 210211010188 Assignment09Alex FredNessuna valutazione finora
- Prediction Under Uncertainty in Reservoir Modeling: Mike Christie, Sam Subbey, Malcolm SambridgeDocumento8 paginePrediction Under Uncertainty in Reservoir Modeling: Mike Christie, Sam Subbey, Malcolm SambridgeDannyNessuna valutazione finora
- Model Reduction High DimensionDocumento20 pagineModel Reduction High DimensionLei TuNessuna valutazione finora
- Genetic Algorithm-Based Clustering TechniqueDocumento11 pagineGenetic Algorithm-Based Clustering TechniqueArmansyah BarusNessuna valutazione finora
- Final Project ReportDocumento18 pagineFinal Project ReportjstpallavNessuna valutazione finora
- Gaussian Process Landmarking On Manifolds: Tingran Gao, Shahar Z. Kovalsky, Ingrid DaubechiesDocumento30 pagineGaussian Process Landmarking On Manifolds: Tingran Gao, Shahar Z. Kovalsky, Ingrid DaubechiesmeoxauNessuna valutazione finora
- Algorithms 10 00105Documento14 pagineAlgorithms 10 00105kamutmazNessuna valutazione finora
- Analysis&Comparisonof Efficient TechniquesofDocumento5 pagineAnalysis&Comparisonof Efficient TechniquesofasthaNessuna valutazione finora
- Estimates of Uncertainty of Measurement From Proficiency Testing Data: A Case StudyDocumento7 pagineEstimates of Uncertainty of Measurement From Proficiency Testing Data: A Case StudyChuckPeter MartinorrisNessuna valutazione finora
- Improving Expression Data Mining Through ClusterDocumento4 pagineImproving Expression Data Mining Through ClusterYuhefizar Ephi LintauNessuna valutazione finora
- Ecient Leave-One-Out Cross-Validation of Kernel Fisher Discriminant Classi'ersDocumento8 pagineEcient Leave-One-Out Cross-Validation of Kernel Fisher Discriminant Classi'ersMohammad TaheriNessuna valutazione finora
- Analytical Chemistry. - Curvas de Calibracion, Bondad de Ajuste, PonderaciónDocumento8 pagineAnalytical Chemistry. - Curvas de Calibracion, Bondad de Ajuste, Ponderaciónhugoboss_darkNessuna valutazione finora
- Number of Analytes in A PanelDocumento3 pagineNumber of Analytes in A Panelshakthi jayanthNessuna valutazione finora
- Active Learning of Ternary Alloy Structures and EnergiesDocumento22 pagineActive Learning of Ternary Alloy Structures and Energiesbmalki68Nessuna valutazione finora
- (VK) 25. Bayesian Node LocalisationDocumento4 pagine(VK) 25. Bayesian Node LocalisationHarshNessuna valutazione finora
- Implementation of Bayesian Tests Pbayes and Dbayes For Randomized Block Design in R Code.Documento7 pagineImplementation of Bayesian Tests Pbayes and Dbayes For Randomized Block Design in R Code.IJAERS JOURNALNessuna valutazione finora
- Ijaiem 2014 05 20 056Documento11 pagineIjaiem 2014 05 20 056International Journal of Application or Innovation in Engineering & ManagementNessuna valutazione finora
- H-P Discretisation in Three DimensionsDocumento13 pagineH-P Discretisation in Three DimensionsMario Galindo QueraltNessuna valutazione finora
- Bickel and Levina 2004Documento28 pagineBickel and Levina 2004dfaini12Nessuna valutazione finora
- Journal of Chromatography A: David Pfister, Fabian Steinebach, Massimo MorbidelliDocumento9 pagineJournal of Chromatography A: David Pfister, Fabian Steinebach, Massimo MorbidelliJames EdwardsNessuna valutazione finora
- 2001, Pena, PrietoDocumento25 pagine2001, Pena, Prietomatchman6Nessuna valutazione finora
- Seed Enterprises January 2011Documento94 pagineSeed Enterprises January 2011Madan LakshmananNessuna valutazione finora
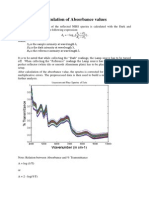
- Calculation of Absorbance ValuesDocumento1 paginaCalculation of Absorbance ValuesMadan LakshmananNessuna valutazione finora
- Which data points go into the training set for molecular modelingDocumento4 pagineWhich data points go into the training set for molecular modelingMadan LakshmananNessuna valutazione finora
- Smoothing and Differentiation of Data by Simplified Least Squares ProceduresDocumento13 pagineSmoothing and Differentiation of Data by Simplified Least Squares ProceduresMadan LakshmananNessuna valutazione finora
- Selecting Arrester MCOV-UcDocumento9 pagineSelecting Arrester MCOV-Ucjose GonzalezNessuna valutazione finora
- MF1547Front Linkage - Seat PDFDocumento18 pagineMF1547Front Linkage - Seat PDFAhmad Ali NursahidinNessuna valutazione finora
- Sadi Mohammad Naved: Duties/ResponsibilitiesDocumento3 pagineSadi Mohammad Naved: Duties/ResponsibilitiesNick SanchezNessuna valutazione finora
- AeDocumento12 pagineAeRoberto SanchezNessuna valutazione finora
- Ladybug5 DatasheetDocumento2 pagineLadybug5 DatasheetEloy Ricardo Franco FigueiraNessuna valutazione finora
- Effect of CSR on Corporate Reputation and PerformanceDocumento13 pagineEffect of CSR on Corporate Reputation and PerformanceAnthon AqNessuna valutazione finora
- MS Gree Aircon Midwall Service Manual PDFDocumento55 pagineMS Gree Aircon Midwall Service Manual PDFMacSparesNessuna valutazione finora
- Checklist For BrickworkDocumento2 pagineChecklist For Brickworkइंजि कौस्तुभ पवारNessuna valutazione finora
- 12 585 Rov Latches Brochure v3 Web 1 PDFDocumento8 pagine12 585 Rov Latches Brochure v3 Web 1 PDFIZayvenkoNessuna valutazione finora
- SwephprgDocumento94 pagineSwephprgAbhisekAcharyaNessuna valutazione finora
- Tata Safari 2.2L Headlamp Level Adjustment GuideDocumento3 pagineTata Safari 2.2L Headlamp Level Adjustment GuidePraveen SinghNessuna valutazione finora
- Spare Parts List: Hydraulic Breakers RX6Documento16 pagineSpare Parts List: Hydraulic Breakers RX6Sales AydinkayaNessuna valutazione finora
- Design of Coin Sorter Counter Based On MCU: Articles You May Be Interested inDocumento5 pagineDesign of Coin Sorter Counter Based On MCU: Articles You May Be Interested inArchana BenkarNessuna valutazione finora
- LRP I Approved ProjectsDocumento1 paginaLRP I Approved ProjectsTheReviewNessuna valutazione finora
- Serrano y Olalla - Linearization of The Hoek y BrownDocumento11 pagineSerrano y Olalla - Linearization of The Hoek y BrownEsteban JamettNessuna valutazione finora
- Datasheet Modevapac v2.1 PDFDocumento4 pagineDatasheet Modevapac v2.1 PDFParvezNessuna valutazione finora
- Super Capacitors ConstructionDocumento7 pagineSuper Capacitors ConstructionVivek BavdhaneNessuna valutazione finora
- CIRCULAR WATER TANK DESIGN-Layout1 AkhilDocumento1 paginaCIRCULAR WATER TANK DESIGN-Layout1 AkhilVENKAT KALYANNessuna valutazione finora
- Reliability and Failure Modes of A Hybrid Ceramic Abutment PrototypeDocumento5 pagineReliability and Failure Modes of A Hybrid Ceramic Abutment PrototypeAli FaridiNessuna valutazione finora
- A Young Lasallian Is US Environmental ScholarDocumento1 paginaA Young Lasallian Is US Environmental ScholarDia DimayugaNessuna valutazione finora
- Asi X Packer 105243965Documento3 pagineAsi X Packer 105243965Esteban RochaNessuna valutazione finora
- SUMMER TRAINING REPORT AT Elin Electronics Ltd. Gzb.Documento54 pagineSUMMER TRAINING REPORT AT Elin Electronics Ltd. Gzb.Ravi Kumar100% (3)
- IECDocumento52 pagineIECM.r. Munish100% (2)
- Spokane County Sheriff's Internal Communication PlanDocumento11 pagineSpokane County Sheriff's Internal Communication Planjmcgrath208100% (1)
- Manufacturing Technology Question Papers of JntuaDocumento15 pagineManufacturing Technology Question Papers of JntuaHimadhar SaduNessuna valutazione finora
- PQA824 ManualDocumento100 paginePQA824 ManualElkin AguasNessuna valutazione finora
- Model 2000 Flow ComputerDocumento8 pagineModel 2000 Flow ComputerAdnan SalihbegovicNessuna valutazione finora
- User's Manual: Motherboard AMD Socket AM2Documento56 pagineUser's Manual: Motherboard AMD Socket AM2vagnerrock007Nessuna valutazione finora
- How to ping NodeB and RNC using RTN transmission IPDocumento14 pagineHow to ping NodeB and RNC using RTN transmission IPPaulo DembiNessuna valutazione finora
- 30x173 - TPDS-T - MK317 Mod0 - NAVSEA - 2011Documento16 pagine30x173 - TPDS-T - MK317 Mod0 - NAVSEA - 2011Anonymous jIzz7woS6Nessuna valutazione finora