Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- An Introduction To The Archimate 2 Modeling LanguageDocumento30 pagineAn Introduction To The Archimate 2 Modeling LanguageFernandoFortanellNessuna valutazione finora
- Recursive Least Squares Parameter SlidesDocumento18 pagineRecursive Least Squares Parameter SlideswahbaabassNessuna valutazione finora
- CSE202 Database Management Systems: Lecture #6Documento82 pagineCSE202 Database Management Systems: Lecture #6Kedir WarituNessuna valutazione finora
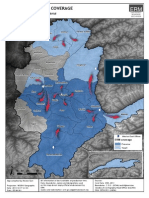
- MissionEast Map - ERM3 Coverage On Badakhshan Province, AfghanistanDocumento1 paginaMissionEast Map - ERM3 Coverage On Badakhshan Province, AfghanistanJG_AudeoudNessuna valutazione finora
- CSE 2204 Database Systems Lesson Plan 2016Documento4 pagineCSE 2204 Database Systems Lesson Plan 2016srssNessuna valutazione finora
- Previous GATE Questions With Solutions On DBMS (Normalization) - CS/ITDocumento7 paginePrevious GATE Questions With Solutions On DBMS (Normalization) - CS/ITdsmari100% (1)
- Warehouse Schema DesignDocumento3 pagineWarehouse Schema DesignAmit BaghelNessuna valutazione finora
- Usulan Perbaikan Proses Pelayanan Loading Dan UnloDocumento8 pagineUsulan Perbaikan Proses Pelayanan Loading Dan Unlojanuar baharuliNessuna valutazione finora
- Chapter 4 RegressionDocumento38 pagineChapter 4 RegressionIvan NgNessuna valutazione finora
- Chapter 3 SQLDocumento59 pagineChapter 3 SQLdinaras bekeleNessuna valutazione finora
- Database Programming With PL/SQL 2-3: Practice Activities: Recognizing Data TypesDocumento3 pagineDatabase Programming With PL/SQL 2-3: Practice Activities: Recognizing Data TypesJOSE CARLOS MAR RANGELNessuna valutazione finora
- AE114 Course ContentDocumento2 pagineAE114 Course Contentjohny BraveNessuna valutazione finora
- Lab Manual 03 PDFDocumento10 pagineLab Manual 03 PDFShahid ZikriaNessuna valutazione finora
- DBMS LabDocumento59 pagineDBMS LabNirmala SherineNessuna valutazione finora
- DBMS Unit 4 Notes PDFDocumento61 pagineDBMS Unit 4 Notes PDFPandu NaiduNessuna valutazione finora
- 9A04802 Digital Image ProcessingDocumento4 pagine9A04802 Digital Image ProcessingsivabharathamurthyNessuna valutazione finora
- Normalization ExercisesDocumento6 pagineNormalization ExercisesWava Jahn Vargas100% (1)
- MGT 2070 Assignment 2 - Solutions: T t-1 t-1 t-1Documento5 pagineMGT 2070 Assignment 2 - Solutions: T t-1 t-1 t-1Nadya AzzuraNessuna valutazione finora
- Evermotion Archmodels 79 PDFDocumento2 pagineEvermotion Archmodels 79 PDFKimNessuna valutazione finora
- Pemodelan Dan SimulasiDocumento40 paginePemodelan Dan SimulasiTak Sebatas BukuNessuna valutazione finora
- Bike Sharing AnalysisDocumento4 pagineBike Sharing AnalysisDevansh SharmaNessuna valutazione finora
- Roever College of Engineering and Technology PERAMBALUR - 621 212 Department of Computer Science and EngineeringDocumento4 pagineRoever College of Engineering and Technology PERAMBALUR - 621 212 Department of Computer Science and EngineeringanbuelectricalNessuna valutazione finora
- ECS 165A: Introduction To Database Systems: Todd J. GreenDocumento15 pagineECS 165A: Introduction To Database Systems: Todd J. GreenRobinson JoshuaNessuna valutazione finora
- IE306 Lec 4Documento20 pagineIE306 Lec 4Atakan DemirkanNessuna valutazione finora
- Bienve Nidos: Tecnología Avanzada en Bases de DatosDocumento42 pagineBienve Nidos: Tecnología Avanzada en Bases de DatoscobiamNessuna valutazione finora
- Question Text: Clear My ChoiceDocumento31 pagineQuestion Text: Clear My ChoiceKimberly Mae HernandezNessuna valutazione finora
- System Analysis & DesignDocumento2 pagineSystem Analysis & DesignMuktinath rajbanshiNessuna valutazione finora
- MySQL Codes For LearningDocumento12 pagineMySQL Codes For LearningMirzoboburNessuna valutazione finora
- 3 UmlDocumento42 pagine3 UmlAli OzdemirNessuna valutazione finora