Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- 2022 WR Extended VersionDocumento71 pagine2022 WR Extended Versionpavankawade63Nessuna valutazione finora
- Standard Answers For The MSC ProgrammeDocumento17 pagineStandard Answers For The MSC ProgrammeTiwiNessuna valutazione finora
- 50114a Isolemfi 50114a MonoDocumento2 pagine50114a Isolemfi 50114a MonoUsama AwadNessuna valutazione finora
- 7TH Maths F.a-1Documento1 pagina7TH Maths F.a-1Marrivada SuryanarayanaNessuna valutazione finora
- 2016 Closing The Gap ReportDocumento64 pagine2016 Closing The Gap ReportAllan ClarkeNessuna valutazione finora
- Ccoli: Bra Ica Ol A LDocumento3 pagineCcoli: Bra Ica Ol A LsychaitanyaNessuna valutazione finora
- Cyber Briefing Series - Paper 2 - FinalDocumento24 pagineCyber Briefing Series - Paper 2 - FinalMapacheYorkNessuna valutazione finora
- Thesis PaperDocumento53 pagineThesis PaperAnonymous AOOrehGZAS100% (1)
- Tool Charts PDFDocumento3 pagineTool Charts PDFtebengz100% (2)
- Jackson V AEGLive - May 10 Transcripts, of Karen Faye-Michael Jackson - Make-up/HairDocumento65 pagineJackson V AEGLive - May 10 Transcripts, of Karen Faye-Michael Jackson - Make-up/HairTeamMichael100% (2)
- SweetenersDocumento23 pagineSweetenersNur AfifahNessuna valutazione finora
- An Evaluation of MGNREGA in SikkimDocumento7 pagineAn Evaluation of MGNREGA in SikkimBittu SubbaNessuna valutazione finora
- QuexBook TutorialDocumento14 pagineQuexBook TutorialJeffrey FarillasNessuna valutazione finora
- Acute Appendicitis in Children - Diagnostic Imaging - UpToDateDocumento28 pagineAcute Appendicitis in Children - Diagnostic Imaging - UpToDateHafiz Hari NugrahaNessuna valutazione finora
- Development Developmental Biology EmbryologyDocumento6 pagineDevelopment Developmental Biology EmbryologyBiju ThomasNessuna valutazione finora
- Genetics Icar1Documento18 pagineGenetics Icar1elanthamizhmaranNessuna valutazione finora
- Applications SeawaterDocumento23 pagineApplications SeawaterQatar home RentNessuna valutazione finora
- Sveba Dahlen - SRP240Documento16 pagineSveba Dahlen - SRP240Paola MendozaNessuna valutazione finora
- (1921) Manual of Work Garment Manufacture: How To Improve Quality and Reduce CostsDocumento102 pagine(1921) Manual of Work Garment Manufacture: How To Improve Quality and Reduce CostsHerbert Hillary Booker 2nd100% (1)
- PDF Chapter 5 The Expenditure Cycle Part I Summary - CompressDocumento5 paginePDF Chapter 5 The Expenditure Cycle Part I Summary - CompressCassiopeia Cashmere GodheidNessuna valutazione finora
- Module 2 MANA ECON PDFDocumento5 pagineModule 2 MANA ECON PDFMeian De JesusNessuna valutazione finora
- Chapter 4 Achieving Clarity and Limiting Paragraph LengthDocumento1 paginaChapter 4 Achieving Clarity and Limiting Paragraph Lengthapi-550339812Nessuna valutazione finora
- The Covenant Taken From The Sons of Adam Is The FitrahDocumento10 pagineThe Covenant Taken From The Sons of Adam Is The FitrahTyler FranklinNessuna valutazione finora
- Unsuccessful MT-SM DeliveryDocumento2 pagineUnsuccessful MT-SM DeliveryPitam MaitiNessuna valutazione finora
- (Jones) GoodwinDocumento164 pagine(Jones) Goodwinmount2011Nessuna valutazione finora
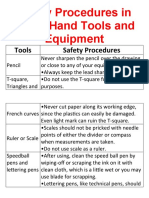
- Safety Procedures in Using Hand Tools and EquipmentDocumento12 pagineSafety Procedures in Using Hand Tools and EquipmentJan IcejimenezNessuna valutazione finora
- Lesson 3 - ReviewerDocumento6 pagineLesson 3 - ReviewerAdrian MarananNessuna valutazione finora
- PSA Poster Project WorkbookDocumento38 paginePSA Poster Project WorkbookwalliamaNessuna valutazione finora
- An Annotated Bibliography of Timothy LearyDocumento312 pagineAn Annotated Bibliography of Timothy LearyGeetika CnNessuna valutazione finora
- SASS Prelims 2017 4E5N ADocumento9 pagineSASS Prelims 2017 4E5N ADamien SeowNessuna valutazione finora