Potrebbero piacerti anche
- Document-Oriented Database - Wikipedia PDFDocumento10 pagineDocument-Oriented Database - Wikipedia PDFSofia SerraNessuna valutazione finora
- 3 Ways To Improve Excel Data IntegrityDocumento2 pagine3 Ways To Improve Excel Data IntegrityJacinto Gomez EmbolettiNessuna valutazione finora
- Whats New 7 0 SR2Documento34 pagineWhats New 7 0 SR2Guru SarafNessuna valutazione finora
- Summary Business AnalyticsDocumento24 pagineSummary Business AnalyticsLUIGIANessuna valutazione finora
- Are You Under A DoS or DDoS Attack - Find Out With Netstat !Documento4 pagineAre You Under A DoS or DDoS Attack - Find Out With Netstat !chinku85Nessuna valutazione finora
- Enable TLS 1.2Documento7 pagineEnable TLS 1.2Manuela KuczynskaNessuna valutazione finora
- Dexlab OnePageDocumento1 paginaDexlab OnePageAlessio SorrentoNessuna valutazione finora
- This Is The Fastest Way To Hunt Windows Endpoints PDFDocumento31 pagineThis Is The Fastest Way To Hunt Windows Endpoints PDFozkhan786Nessuna valutazione finora
- Implementing The Account and Financial Dimensions Framework AX2012Documento43 pagineImplementing The Account and Financial Dimensions Framework AX2012Sky Boon Kok LeongNessuna valutazione finora
- Company Profile 2011Documento28 pagineCompany Profile 2011najibjaafarNessuna valutazione finora
- Windows2016 HardeningDocumento5 pagineWindows2016 HardeningansaarNessuna valutazione finora
- Application, Data and Host SecurityDocumento24 pagineApplication, Data and Host SecurityKari AlfaroNessuna valutazione finora
- 3DES - CBC - Sweet32 - Birthday Attacks On 64-Bit Block Ciphers in TLS and OpenVPN PDFDocumento9 pagine3DES - CBC - Sweet32 - Birthday Attacks On 64-Bit Block Ciphers in TLS and OpenVPN PDFsipteckNessuna valutazione finora
- IIS Configuration Settings Checklist Rev1Documento10 pagineIIS Configuration Settings Checklist Rev1Minh Nhut LuuNessuna valutazione finora
- Standing Operating Procedure-FinalDocumento5 pagineStanding Operating Procedure-FinalRaheel KhanNessuna valutazione finora
- CFA Level I Three-Month Study PlanDocumento9 pagineCFA Level I Three-Month Study Plansashavlad100% (1)
- Security Hardening Settings For Windows ServersDocumento5 pagineSecurity Hardening Settings For Windows ServersGophisNessuna valutazione finora
- DataSeer Training ProspectusDocumento25 pagineDataSeer Training ProspectusJose Ramon VillatuyaNessuna valutazione finora
- Satvik-Predictve Analytics Deck - v2Documento52 pagineSatvik-Predictve Analytics Deck - v2curlin13Nessuna valutazione finora
- Store PlanningDocumento12 pagineStore PlanningGladwin JosephNessuna valutazione finora
- Building Balanced Scorecard Strategy MapsDocumento18 pagineBuilding Balanced Scorecard Strategy MapsRaviram NaiduNessuna valutazione finora
- Using Analytics To Enhance A Food Retailer's Shelf-SpaceDocumento22 pagineUsing Analytics To Enhance A Food Retailer's Shelf-SpaceJanaNessuna valutazione finora
- E Book Security LogDocumento101 pagineE Book Security LogohahnetNessuna valutazione finora
- Network CommadnsDocumento8 pagineNetwork Commadnssasha zavatinNessuna valutazione finora
- The United Arab Emirates and Africa: A Pivotal Partnership Amid A "South-South" Commercial RevolutionDocumento36 pagineThe United Arab Emirates and Africa: A Pivotal Partnership Amid A "South-South" Commercial RevolutionJoseph DanaNessuna valutazione finora
- 36 Questions To Answer: The Essentials of A Documented Content Marketing StrategyDocumento16 pagine36 Questions To Answer: The Essentials of A Documented Content Marketing StrategySilvia Beatle SnapeNessuna valutazione finora
- Oea Dell Case Study 1521201 CASE STUDYDocumento11 pagineOea Dell Case Study 1521201 CASE STUDYnreddi555Nessuna valutazione finora
- DataSeer Training Prospectus 20190204Documento25 pagineDataSeer Training Prospectus 20190204Carl Dominick CalubNessuna valutazione finora
- Cheese Concentrate MarketDocumento12 pagineCheese Concentrate MarketNamrataNessuna valutazione finora
- Pestle Analysis QSRDocumento3 paginePestle Analysis QSRJoshua RushNessuna valutazione finora
- Jukka Lintusaari IRU Ertico MaaS WorkhopDocumento17 pagineJukka Lintusaari IRU Ertico MaaS WorkhopanirudhasNessuna valutazione finora
- Generic Risk Manager Job ProfileDocumento2 pagineGeneric Risk Manager Job ProfilebebisatchNessuna valutazione finora
- Security Control Assessment Yes/NoDocumento11 pagineSecurity Control Assessment Yes/NosashiNessuna valutazione finora
- Fractal Analytics - Corporate ReportDocumento2 pagineFractal Analytics - Corporate ReportShashi BhagnariNessuna valutazione finora
- Microsoft Dynamics: Presented by - Deepak.JDocumento20 pagineMicrosoft Dynamics: Presented by - Deepak.JDeepak Prakash JayaNessuna valutazione finora
- E-Business Suite Applications - WebCast Part3Documento109 pagineE-Business Suite Applications - WebCast Part3mouse.lenova mouseNessuna valutazione finora
- Ransomware Containment and Remediation StrategiesDocumento38 pagineRansomware Containment and Remediation StrategiesVaibhav SawantNessuna valutazione finora
- Introduction To Data Warehousing: Pragim TechnologiesDocumento49 pagineIntroduction To Data Warehousing: Pragim TechnologiesajaysperidianNessuna valutazione finora
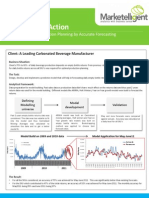
- Analytics in Action - How Marketelligent Helped A Beverage Manufacturer Better Its Production PlanningDocumento2 pagineAnalytics in Action - How Marketelligent Helped A Beverage Manufacturer Better Its Production PlanningMarketelligentNessuna valutazione finora
- Pharmacy Closing ChecklistDocumento43 paginePharmacy Closing ChecklistRedeye AsiaNessuna valutazione finora
- Deception & Detection-On Amazon Reviews DatasetDocumento9 pagineDeception & Detection-On Amazon Reviews Datasetyavar khanNessuna valutazione finora
- Nist Guides TlsDocumento67 pagineNist Guides TlsURJConlineNessuna valutazione finora
- Information Systems and Technology in BusinessDocumento11 pagineInformation Systems and Technology in BusinessZamzam AbdelazimNessuna valutazione finora
- Example Back Up PolicyDocumento11 pagineExample Back Up PolicyConstantin TomaNessuna valutazione finora
- The Top Five Myths of Website Security: A Focus On Small-to-Mid-Sized EnterprisesDocumento9 pagineThe Top Five Myths of Website Security: A Focus On Small-to-Mid-Sized EnterprisesdmenonNessuna valutazione finora
- IT Infrastructure Project Management in Atlanta GA Resume Deborah ThorntonDocumento2 pagineIT Infrastructure Project Management in Atlanta GA Resume Deborah ThorntonDeborahThorntonNessuna valutazione finora
- 3 - IT Department Organization StructureDocumento5 pagine3 - IT Department Organization StructureGurpreet Bansal100% (1)
- Ransomware Prevention RecommendationsDocumento2 pagineRansomware Prevention RecommendationsmufeedNessuna valutazione finora
- Desktop Vulnerability Scan Remediation PlanDocumento2 pagineDesktop Vulnerability Scan Remediation PlanChandra SekharNessuna valutazione finora
- What Is The Difference Between A Virus and A WormDocumento3 pagineWhat Is The Difference Between A Virus and A WormPetr IkhwanNessuna valutazione finora
- GlobalData Keytrendsinculinarytourism 130918-1Documento24 pagineGlobalData Keytrendsinculinarytourism 130918-1raisincookiesNessuna valutazione finora
- Data Warehousing Stages of GrowthDocumento9 pagineData Warehousing Stages of GrowthmwekezajiNessuna valutazione finora
- What Is Network DiagramDocumento7 pagineWhat Is Network DiagramOundo SamNessuna valutazione finora
- WP Impact of Strategic Simulation On Product ProfitabilityDocumento6 pagineWP Impact of Strategic Simulation On Product ProfitabilitymcruzalvNessuna valutazione finora
- Business Strategy - Part 1 and 2Documento34 pagineBusiness Strategy - Part 1 and 2cinderella69Nessuna valutazione finora
- What Is Data DictionaryDocumento2 pagineWhat Is Data DictionaryKabil RockyNessuna valutazione finora
- Unit - IiiDocumento39 pagineUnit - IiiJit AggNessuna valutazione finora
- Elasticsearch: Getting Started With ElasticsearchDocumento6 pagineElasticsearch: Getting Started With ElasticsearchYathindra sheshappaNessuna valutazione finora
- LAAMS Technical Summary Tensar+Documento17 pagineLAAMS Technical Summary Tensar+Janaki RamNessuna valutazione finora
- HST TrainingDocumento11 pagineHST TrainingRamesh BabuNessuna valutazione finora
- JSF + JPA + JasperReports (Ireport) Part 2 - Ramki Java BlogDocumento7 pagineJSF + JPA + JasperReports (Ireport) Part 2 - Ramki Java BlogMartin MurciegoNessuna valutazione finora
- Numbers (0, 1, 2, 3,... ) Are Defined To Be Natural Numbers, Including Zero, That Does Not ContainDocumento9 pagineNumbers (0, 1, 2, 3,... ) Are Defined To Be Natural Numbers, Including Zero, That Does Not ContainRomela EspedidoNessuna valutazione finora
- Air Conditioner: Owner'S ManualDocumento80 pagineAir Conditioner: Owner'S Manualfred MaxNessuna valutazione finora
- Tecumseh Parts List OHV 135Documento5 pagineTecumseh Parts List OHV 135M MNessuna valutazione finora
- Lab Manual of Hydraulics PDFDocumento40 pagineLab Manual of Hydraulics PDFJULIUS CESAR G. CADAONessuna valutazione finora
- 1982 International Rectifier Hexfet Databook PDFDocumento472 pagine1982 International Rectifier Hexfet Databook PDFetmatsudaNessuna valutazione finora
- SOFARSOLAR ModBus-RTU Communication ProtocolDocumento22 pagineSOFARSOLAR ModBus-RTU Communication ProtocolВячеслав ЛарионовNessuna valutazione finora
- Gantt ChartDocumento4 pagineGantt ChartSyed FaridNessuna valutazione finora
- Auto-Tune Pid Temperature & Timer General Specifications: N L1 L2 L3Documento4 pagineAuto-Tune Pid Temperature & Timer General Specifications: N L1 L2 L3sharawany 20Nessuna valutazione finora
- 1 s2.0 0304386X9190055Q MainDocumento32 pagine1 s2.0 0304386X9190055Q MainJordan Ulloa Bello100% (1)
- Calculus 1: CONTINUITYDocumento56 pagineCalculus 1: CONTINUITYMa Lorraine PerezNessuna valutazione finora
- AtomDocumento15 pagineAtomdewi murtasimaNessuna valutazione finora
- Case StudyDocumento10 pagineCase StudyVintage ArtNessuna valutazione finora
- IIM Nagpur Test 1 Version 1 2016Documento6 pagineIIM Nagpur Test 1 Version 1 2016Saksham GoyalNessuna valutazione finora
- Mod 4 Revision Guide 1 Reaction Kinetics AQA A2 ChemistryDocumento5 pagineMod 4 Revision Guide 1 Reaction Kinetics AQA A2 Chemistryviyas07Nessuna valutazione finora
- Python Unit 1Documento18 paginePython Unit 1Rtr. Venkata chetan Joint secretaryNessuna valutazione finora
- 2 Engleza Oscilatii ArmoniceDocumento12 pagine2 Engleza Oscilatii ArmoniceMIRCEA-PAUL TĂNĂSESCUNessuna valutazione finora
- Organic Chemistry - Some Basic Principles and Techniques-1Documento195 pagineOrganic Chemistry - Some Basic Principles and Techniques-1aditya kumar Agarwal100% (1)
- Good 1983Documento352 pagineGood 1983ASDA75% (4)
- Practical - Magnetic - Design (Fill Factor) PDFDocumento20 paginePractical - Magnetic - Design (Fill Factor) PDFAhtasham ChaudhryNessuna valutazione finora
- Backup Olt CodigoDocumento5 pagineBackup Olt CodigoCarlos GomezNessuna valutazione finora
- Physics Lab - Detailed - Answer KeyDocumento6 paginePhysics Lab - Detailed - Answer KeyJasdeepSinghNessuna valutazione finora
- D4304-Syllabus-Neural Networks and Fuzzy SystemsDocumento1 paginaD4304-Syllabus-Neural Networks and Fuzzy Systemsshankar15050% (1)
- Applications of Modern RF PhotonicsDocumento213 pagineApplications of Modern RF PhotonicsrmcmillanNessuna valutazione finora
- TOFD Dead Zone CalculatorDocumento4 pagineTOFD Dead Zone CalculatorWill SmithNessuna valutazione finora
- Kids Curriculum BreakdownDocumento6 pagineKids Curriculum BreakdownSuniel ChhetriNessuna valutazione finora
- FP 3000 PDFDocumento1 paginaFP 3000 PDFClaudio Godoy ZepedaNessuna valutazione finora
- Chapter 1: Coding Decoding: Important Note: It Is Good To Avoid Pre-Defined Coding Rule To Write A Coded MessageDocumento7 pagineChapter 1: Coding Decoding: Important Note: It Is Good To Avoid Pre-Defined Coding Rule To Write A Coded MessageUmamNessuna valutazione finora