Potrebbero piacerti anche
- Oracle 11g R1/R2 Real Application Clusters EssentialsDa EverandOracle 11g R1/R2 Real Application Clusters EssentialsValutazione: 5 su 5 stelle5/5 (1)
- PostgreSQL 15 Cookbook: 100+ expert solutions across scalability, performance optimization, essential commands, cloud provisioning, backup, and recoveryDa EverandPostgreSQL 15 Cookbook: 100+ expert solutions across scalability, performance optimization, essential commands, cloud provisioning, backup, and recoveryNessuna valutazione finora
- Pganalyze Best Practices For Optimizing Postgres Query PerformanceDocumento26 paginePganalyze Best Practices For Optimizing Postgres Query PerformanceLe Tan PhatNessuna valutazione finora
- Dataguard - MyunderstandingDocumento3 pagineDataguard - Myunderstandingabdulgani11Nessuna valutazione finora
- Using Ola Hallengrens SQL Maintenance Scripts PDFDocumento28 pagineUsing Ola Hallengrens SQL Maintenance Scripts PDFHana IbisevicNessuna valutazione finora
- Golden Gate Oracle ReplicationDocumento3 pagineGolden Gate Oracle ReplicationCynthiaNessuna valutazione finora
- Analyze AWR Report in Oracle for Performance IssuesDocumento8 pagineAnalyze AWR Report in Oracle for Performance IssuesAnonymous 8RhRm6Eo7hNessuna valutazione finora
- Oracle 11g R2 RAC and Grid Infrastructure by Rene KundersmaDocumento20 pagineOracle 11g R2 RAC and Grid Infrastructure by Rene Kundersmaittichai100% (1)
- Oracle Data Guard 12cR2Documento176 pagineOracle Data Guard 12cR2Rogério Pereira FalconeNessuna valutazione finora
- AWR Explanation GoodDocumento91 pagineAWR Explanation GoodmaleshgNessuna valutazione finora
- Rman DocumentDocumento11 pagineRman Documentsantababu100% (2)
- Oracle Performance TuningDocumento18 pagineOracle Performance TuningKamalakshi Raj100% (1)
- Interview Question For Oracle DBADocumento111 pagineInterview Question For Oracle DBAVimlendu Kumar100% (1)
- Backup StrategiesDocumento44 pagineBackup StrategiesAman UllahNessuna valutazione finora
- Pgpool-II 1st StepsDocumento12 paginePgpool-II 1st Stepsopenerp_userNessuna valutazione finora
- EDB High Availability Scalability v1.0Documento23 pagineEDB High Availability Scalability v1.0Paohua ChuangNessuna valutazione finora
- Top SQL Server Backup MistakesDocumento10 pagineTop SQL Server Backup MistakesCarlosDuPivatoNessuna valutazione finora
- Rman TutorialDocumento20 pagineRman TutorialRama Krishna PasupulettiNessuna valutazione finora
- High Performance PostgreSQL, Tuning and Optimization Guide - FileId - 160682Documento21 pagineHigh Performance PostgreSQL, Tuning and Optimization Guide - FileId - 160682Alex Jésus Moreira AriasNessuna valutazione finora
- Cassandra NotesDocumento6 pagineCassandra NotesAmit ShahNessuna valutazione finora
- ASM Interview QuestionsDocumento6 pagineASM Interview QuestionsNst TnagarNessuna valutazione finora
- Oracle QsDocumento6 pagineOracle QshellopavaniNessuna valutazione finora
- AWR RPT Reading PDFDocumento64 pagineAWR RPT Reading PDFharsshNessuna valutazione finora
- Top RAC Interview QuestionsDocumento10 pagineTop RAC Interview QuestionsSiva KumarNessuna valutazione finora
- Cheatsheet: Postgresql Monitoring: More Info More InfoDocumento2 pagineCheatsheet: Postgresql Monitoring: More Info More InfoCheck ATNessuna valutazione finora
- 52492-rc071 Postgresql PDFDocumento11 pagine52492-rc071 Postgresql PDFJedt3DNessuna valutazione finora
- Tuning PostgreSQL With PgbenchDocumento11 pagineTuning PostgreSQL With PgbenchSarayNessuna valutazione finora
- Oracle DBA Real Time Interview QuestionsDocumento23 pagineOracle DBA Real Time Interview Questionsmaneesha reddyNessuna valutazione finora
- ASM CommandsDocumento4 pagineASM CommandsHarish NaikNessuna valutazione finora
- Oracle Shell ScriptingDocumento3 pagineOracle Shell Scriptingnamratadhonde1Nessuna valutazione finora
- PostgreSQL As A NoSQL DatabaseDocumento61 paginePostgreSQL As A NoSQL DatabaseIvan VorasNessuna valutazione finora
- 03 Introduction To PostgreSQLDocumento43 pagine03 Introduction To PostgreSQLpaula Sanchez GayetNessuna valutazione finora
- What To Expect in Oracle 19cDocumento42 pagineWhat To Expect in Oracle 19cwalterpotocki100% (1)
- Trobleshoot GRID 1050908.1Documento18 pagineTrobleshoot GRID 1050908.1nandiniNessuna valutazione finora
- Oracle Real Application Clusters (RAC) : RAC Internals, Cache Fusion and Performance TuningDocumento37 pagineOracle Real Application Clusters (RAC) : RAC Internals, Cache Fusion and Performance TuningmadhusribNessuna valutazione finora
- Oracle9i Database - Advanced Backup and Recovery Using RMAN - Student GuideDocumento328 pagineOracle9i Database - Advanced Backup and Recovery Using RMAN - Student Guideacsabo_14521769Nessuna valutazione finora
- Automatic SQL Tuning in Oracle 11g PDFDocumento22 pagineAutomatic SQL Tuning in Oracle 11g PDFNarsimuluAkulaNessuna valutazione finora
- Oracle DBA ChecklistDocumento3 pagineOracle DBA ChecklistmvineetaNessuna valutazione finora
- Oracle PL/SQL Course - Learn Database ProgrammingDocumento26 pagineOracle PL/SQL Course - Learn Database ProgrammingchensuriyanNessuna valutazione finora
- Internals of Active DataGuardDocumento28 pagineInternals of Active DataGuardsaibabu_d100% (1)
- DataGuard MAA New FeaturesDocumento16 pagineDataGuard MAA New Featuresنصر المنصوريNessuna valutazione finora
- RMAN DuplicateDocumento4 pagineRMAN DuplicateDebashis MallickNessuna valutazione finora
- Upgrade To PostgreSQL11Documento36 pagineUpgrade To PostgreSQL11leonard1971Nessuna valutazione finora
- Quick Oracle 9i Performance Tuning Tips & ScriptsDocumento7 pagineQuick Oracle 9i Performance Tuning Tips & ScriptsEder CoutoNessuna valutazione finora
- Extreme Replication - Performance Tuning Oracle GoldenGate by Bobby Curtis (UTOUG 2015 Fall Conference)Documento60 pagineExtreme Replication - Performance Tuning Oracle GoldenGate by Bobby Curtis (UTOUG 2015 Fall Conference)ZULU490Nessuna valutazione finora
- Gridlink RacDocumento21 pagineGridlink RacAngel Freire RamirezNessuna valutazione finora
- HVR User Manual 5.7.cec91698Documento715 pagineHVR User Manual 5.7.cec91698Thaj MohaideenNessuna valutazione finora
- Cloning Database TrainingDocumento16 pagineCloning Database TrainingluckyallyNessuna valutazione finora
- Joe Sack Performance Troubleshooting With Wait StatsDocumento56 pagineJoe Sack Performance Troubleshooting With Wait StatsAamöd ThakürNessuna valutazione finora
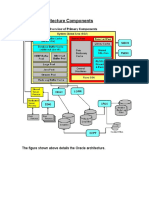
- Database Architecture Oracle DbaDocumento41 pagineDatabase Architecture Oracle DbaImran ShaikhNessuna valutazione finora
- Oracle Cache Fusion Private Inter Connects and Practical Performance Management Considerations in Oracle RacDocumento25 pagineOracle Cache Fusion Private Inter Connects and Practical Performance Management Considerations in Oracle RacKrishna8765Nessuna valutazione finora
- PostgreSQL TutorialDocumento13 paginePostgreSQL TutorialSjsns100% (1)
- Oracle ASM Load Balancing - Anthony NoriegaDocumento48 pagineOracle ASM Load Balancing - Anthony Noriegadiogo_guimaraes0% (1)
- Oracle Rac Upgrade 12cDocumento26 pagineOracle Rac Upgrade 12capi-293702630Nessuna valutazione finora
- Mastering PostgreSQL AdministrationDocumento109 pagineMastering PostgreSQL AdministrationManiSankarNessuna valutazione finora
- How To Make Resume As Fresher Oracle DBA Myths-Mysteries-MemorableDocumento7 pagineHow To Make Resume As Fresher Oracle DBA Myths-Mysteries-Memorablesriraam6Nessuna valutazione finora
- Pro Oracle SQL Development: Best Practices for Writing Advanced QueriesDa EverandPro Oracle SQL Development: Best Practices for Writing Advanced QueriesNessuna valutazione finora
- Windows Server 2012R2Documento55 pagineWindows Server 2012R2Viorel StefanescuNessuna valutazione finora
- Group A Mysql Handout PDFDocumento7 pagineGroup A Mysql Handout PDFAbhishek IcheNessuna valutazione finora
- What Are Arrays in JavaScriptDocumento9 pagineWhat Are Arrays in JavaScriptMiguel LoureiroNessuna valutazione finora
- FortiManager 7.0.0 CLI ReferenceDocumento275 pagineFortiManager 7.0.0 CLI Referencealways_redNessuna valutazione finora
- HD Crash InfoDocumento36 pagineHD Crash Infom_haebeckeNessuna valutazione finora
- Bullet M2 - NetworkDocumento3 pagineBullet M2 - NetworkOscar SanzNessuna valutazione finora
- Intelligent Controller With Extended Applications (2 Readers, 8 Inputs, 4 Outputs)Documento2 pagineIntelligent Controller With Extended Applications (2 Readers, 8 Inputs, 4 Outputs)Saifuddeen TPNessuna valutazione finora
- DB2Documento332 pagineDB2api-26564177100% (1)
- Distinction Task 6.3 - Custom Program DesignDocumento3 pagineDistinction Task 6.3 - Custom Program DesignĐức NguyễnNessuna valutazione finora
- Introduction to Operating Systems ConceptsDocumento97 pagineIntroduction to Operating Systems ConceptsShubham JainNessuna valutazione finora
- Sigma Enterprise - 4G 5G UsecasesDocumento24 pagineSigma Enterprise - 4G 5G UsecasesĐinh Nhất LinhNessuna valutazione finora
- Q1) What Is Polymorphism?Documento71 pagineQ1) What Is Polymorphism?Pankaj SharmaNessuna valutazione finora
- OpenText Media Management 16.2Documento222 pagineOpenText Media Management 16.2Rodrigo SanchezNessuna valutazione finora
- Chapter 09Documento33 pagineChapter 09jackbquick294% (32)
- Technical Guide and Features Onesource eDocumento44 pagineTechnical Guide and Features Onesource ebrunodantas01Nessuna valutazione finora
- Relational Model and Algebra IntroductionDocumento41 pagineRelational Model and Algebra IntroductionAdrian AdrNessuna valutazione finora
- RPSC AcpDocumento2 pagineRPSC AcpSahay AlokNessuna valutazione finora
- DocumentumContentServer 6.5.0 SP3 P24 ReadMeDocumento12 pagineDocumentumContentServer 6.5.0 SP3 P24 ReadMemichaelNessuna valutazione finora
- Web Technology Exam QuestionsDocumento1 paginaWeb Technology Exam QuestionsRamendra ChaudharyNessuna valutazione finora
- DbmsDocumento2 pagineDbmsbhagy finaviyaNessuna valutazione finora
- Preserve LetterDocumento2 paginePreserve LetterNONOPEARSONNessuna valutazione finora
- Angstrom ManualDocumento48 pagineAngstrom ManualTonyandAnthonyNessuna valutazione finora
- Class 1-Introduction To Microprocessor PDFDocumento36 pagineClass 1-Introduction To Microprocessor PDFDeepika AgrawalNessuna valutazione finora
- 17 Database Design Using The REA Data ModelDocumento15 pagine17 Database Design Using The REA Data ModelayutitiekNessuna valutazione finora
- Check Linux Server Configuration and Troubleshoot IssuesDocumento5 pagineCheck Linux Server Configuration and Troubleshoot Issuessopan sonar100% (1)
- Mirth TrainingDocumento45 pagineMirth TrainingPabla Andrea Ceballos NeiraNessuna valutazione finora
- NAC Quiz Attempt ReviewDocumento2 pagineNAC Quiz Attempt ReviewLoraine Peralta50% (2)
- Week 3Documento35 pagineWeek 3Anoo ShresthaNessuna valutazione finora
- 3ADR059056M0201 PB610-B Panel Builder 600 EN PDFDocumento416 pagine3ADR059056M0201 PB610-B Panel Builder 600 EN PDFසම්පත් චන්ද්රරත්නNessuna valutazione finora
- Crane and Hoist Electrification SystemsDocumento2 pagineCrane and Hoist Electrification Systemssajid tahmid HasanNessuna valutazione finora