Potrebbero piacerti anche
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- PDFDocumento10 paginePDFerbariumNessuna valutazione finora
- Hans Belting - The End of The History of Art (1982)Documento126 pagineHans Belting - The End of The History of Art (1982)Ross Wolfe100% (7)
- Book 1518450482Documento14 pagineBook 1518450482rajer13Nessuna valutazione finora
- Jackson V AEGLive - May 10 Transcripts, of Karen Faye-Michael Jackson - Make-up/HairDocumento65 pagineJackson V AEGLive - May 10 Transcripts, of Karen Faye-Michael Jackson - Make-up/HairTeamMichael100% (2)
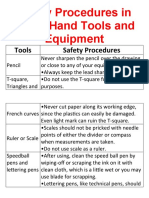
- Safety Procedures in Using Hand Tools and EquipmentDocumento12 pagineSafety Procedures in Using Hand Tools and EquipmentJan IcejimenezNessuna valutazione finora
- Kyle Pape - Between Queer Theory and Native Studies, A Potential For CollaborationDocumento16 pagineKyle Pape - Between Queer Theory and Native Studies, A Potential For CollaborationRafael Alarcón Vidal100% (1)
- Friction: Ultiple Hoice UestionsDocumento5 pagineFriction: Ultiple Hoice Uestionspk2varmaNessuna valutazione finora
- Drive LinesDocumento30 pagineDrive LinesRITESH ROHILLANessuna valutazione finora
- DBMS Lab ManualDocumento57 pagineDBMS Lab ManualNarendh SubramanianNessuna valutazione finora
- FuzzingBluetooth Paul ShenDocumento8 pagineFuzzingBluetooth Paul Shen许昆Nessuna valutazione finora
- Fundamentals of Public Health ManagementDocumento3 pagineFundamentals of Public Health ManagementHPMA globalNessuna valutazione finora
- (Jones) GoodwinDocumento164 pagine(Jones) Goodwinmount2011Nessuna valutazione finora
- Julia Dito ResumeDocumento3 pagineJulia Dito Resumeapi-253713289Nessuna valutazione finora
- Health Post - Exploring The Intersection of Work and Well-Being - A Guide To Occupational Health PsychologyDocumento3 pagineHealth Post - Exploring The Intersection of Work and Well-Being - A Guide To Occupational Health PsychologyihealthmailboxNessuna valutazione finora
- Government College of Nursing Jodhpur: Practice Teaching On-Probability Sampling TechniqueDocumento11 pagineGovernment College of Nursing Jodhpur: Practice Teaching On-Probability Sampling TechniquepriyankaNessuna valutazione finora
- Teaching Profession - Educational PhilosophyDocumento23 pagineTeaching Profession - Educational PhilosophyRon louise PereyraNessuna valutazione finora
- Ccoli: Bra Ica Ol A LDocumento3 pagineCcoli: Bra Ica Ol A LsychaitanyaNessuna valutazione finora
- Chapter 13 (Automatic Transmission)Documento26 pagineChapter 13 (Automatic Transmission)ZIBA KHADIBINessuna valutazione finora
- Cooperative Learning: Complied By: ANGELICA T. ORDINEZADocumento16 pagineCooperative Learning: Complied By: ANGELICA T. ORDINEZAAlexis Kaye GullaNessuna valutazione finora
- Design of Combinational Circuit For Code ConversionDocumento5 pagineDesign of Combinational Circuit For Code ConversionMani BharathiNessuna valutazione finora
- Hướng Dẫn Chấm: Ngày thi: 27 tháng 7 năm 2019 Thời gian làm bài: 180 phút (không kể thời gian giao đề) HDC gồm có 4 trangDocumento4 pagineHướng Dẫn Chấm: Ngày thi: 27 tháng 7 năm 2019 Thời gian làm bài: 180 phút (không kể thời gian giao đề) HDC gồm có 4 trangHưng Quân VõNessuna valutazione finora
- LP For EarthquakeDocumento6 pagineLP For Earthquakejelena jorgeoNessuna valutazione finora
- Topic 3Documento21 pagineTopic 3Ivan SimonNessuna valutazione finora
- Pidsdps 2106Documento174 paginePidsdps 2106Steven Claude TanangunanNessuna valutazione finora
- QuexBook TutorialDocumento14 pagineQuexBook TutorialJeffrey FarillasNessuna valutazione finora
- Z-Purlins: Technical DocumentationDocumento11 pagineZ-Purlins: Technical Documentationardit bedhiaNessuna valutazione finora
- How To Block HTTP DDoS Attack With Cisco ASA FirewallDocumento4 pagineHow To Block HTTP DDoS Attack With Cisco ASA Firewallabdel taibNessuna valutazione finora
- Siemens Make Motor Manual PDFDocumento10 pagineSiemens Make Motor Manual PDFArindam SamantaNessuna valutazione finora
- Fast Track Design and Construction of Bridges in IndiaDocumento10 pagineFast Track Design and Construction of Bridges in IndiaSa ReddiNessuna valutazione finora
- Toeic: Check Your English Vocabulary ForDocumento41 pagineToeic: Check Your English Vocabulary ForEva Ibáñez RamosNessuna valutazione finora