Potrebbero piacerti anche
- Direct Linear Transformation: Practical Applications and Techniques in Computer VisionDa EverandDirect Linear Transformation: Practical Applications and Techniques in Computer VisionNessuna valutazione finora
- Lec. 21 - Zoubin G. Learning Dynamic Bayesian NetworksDocumento31 pagineLec. 21 - Zoubin G. Learning Dynamic Bayesian NetworksAlejandro VasquezNessuna valutazione finora
- Independence Diagrams Thomas P. MinkaDocumento7 pagineIndependence Diagrams Thomas P. MinkaKartik GuptaNessuna valutazione finora
- Analysis of Three-Way TablesDocumento14 pagineAnalysis of Three-Way Tablesvsuarezf2732Nessuna valutazione finora
- Unit 2 Probabilistic ReasoningDocumento21 pagineUnit 2 Probabilistic ReasoningnarmathaapcseNessuna valutazione finora
- Quiz2 ISDS 361BDocumento5 pagineQuiz2 ISDS 361BAnh PhamNessuna valutazione finora
- Slides BnshortDocumento322 pagineSlides BnshortViviana DiasNessuna valutazione finora
- Computer Science Textbook Solutions - 6Documento30 pagineComputer Science Textbook Solutions - 6acc-expertNessuna valutazione finora
- AIML - KE Answer KeyDocumento12 pagineAIML - KE Answer KeyJohnyNessuna valutazione finora
- Spectral Analysis of Signed Graphs For Clustering, Prediction and VisualizationDocumento12 pagineSpectral Analysis of Signed Graphs For Clustering, Prediction and Visualizationsrinivas1956Nessuna valutazione finora
- AIML-Unit 5 NotesDocumento45 pagineAIML-Unit 5 NotesHarshithaNessuna valutazione finora
- Unit 2Documento5 pagineUnit 2Saral ManeNessuna valutazione finora
- Classical LinearReg 000Documento41 pagineClassical LinearReg 000Umair AyazNessuna valutazione finora
- Bayesian Belief Network in Artificial IntelligenceDocumento10 pagineBayesian Belief Network in Artificial IntelligenceALYSSA JOYCE ROMERONessuna valutazione finora
- SN Week9 PDFDocumento3 pagineSN Week9 PDFRajesh KumarNessuna valutazione finora
- DHS2 11revisedDocumento8 pagineDHS2 11revisedAditya RaiNessuna valutazione finora
- Chapter 03 Correlation and RegressionDocumento21 pagineChapter 03 Correlation and RegressionJoseph Baring IIINessuna valutazione finora
- Prob1 00.psodDocumento6 pagineProb1 00.psodSharad JoshiNessuna valutazione finora
- Tugas Ridho 2.100-2.102Documento9 pagineTugas Ridho 2.100-2.102Feby MutiaNessuna valutazione finora
- Model IIDocumento29 pagineModel IIAhmed AbdiNessuna valutazione finora
- A. Díaz-Caro & G. Dowek - Extensional Proofs in A Propositional Logic Modulo Isomorphisms - TCS 977:114172, 2023Documento17 pagineA. Díaz-Caro & G. Dowek - Extensional Proofs in A Propositional Logic Modulo Isomorphisms - TCS 977:114172, 2023Alejandro Díaz-CaroNessuna valutazione finora
- 8s PDFDocumento11 pagine8s PDFደስታ ጌታውNessuna valutazione finora
- Pre-Boolean Algebra, Ordered DSMT and DSM Continuous ModelsDocumento24 paginePre-Boolean Algebra, Ordered DSMT and DSM Continuous ModelsMia AmaliaNessuna valutazione finora
- Social Network Analysis Unit-4Documento21 pagineSocial Network Analysis Unit-4Guribilli VaraprasadNessuna valutazione finora
- Adjacency-Faithfulness and Conservative Causal InferenceDocumento8 pagineAdjacency-Faithfulness and Conservative Causal InferenceSpace DriveNessuna valutazione finora
- Sampleexam 2 QuestionsDocumento5 pagineSampleexam 2 Questionsdungnt0406Nessuna valutazione finora
- Machine-Learning Set 6Documento21 pagineMachine-Learning Set 6Salma AbobashaNessuna valutazione finora
- Bayesian NetworksDocumento7 pagineBayesian NetworksKanav KesarNessuna valutazione finora
- 03 QuestionsDocumento2 pagine03 QuestionsAbdul-Rhman MohamedNessuna valutazione finora
- Final Version Maier 5681Documento31 pagineFinal Version Maier 5681Div DuttaNessuna valutazione finora
- 4.3 Bayesian Belief Network in Artificial IntelligenceDocumento7 pagine4.3 Bayesian Belief Network in Artificial IntelligenceSian YemenNessuna valutazione finora
- Ha Soojung 2009Documento4 pagineHa Soojung 2009sjha613Nessuna valutazione finora
- Abd07 K WidthDocumento12 pagineAbd07 K WidthKevin MondragonNessuna valutazione finora
- Testing The Signi Cance of Attribute InteractionsDocumento8 pagineTesting The Signi Cance of Attribute InteractionselakadiNessuna valutazione finora
- Institute of Engineering and Technology, Lucknow: Special Lab (Kcs-751)Documento37 pagineInstitute of Engineering and Technology, Lucknow: Special Lab (Kcs-751)Hîмanî JayasNessuna valutazione finora
- Institute of Engineering and Technology, Lucknow: Special Lab (Kcs-751)Documento37 pagineInstitute of Engineering and Technology, Lucknow: Special Lab (Kcs-751)Hîмanî JayasNessuna valutazione finora
- On Perfectness in Gaussian Graphical Models: Arash A. Amini, Bryon Aragam, Qing ZhouDocumento15 pagineOn Perfectness in Gaussian Graphical Models: Arash A. Amini, Bryon Aragam, Qing ZhouGaston GBNessuna valutazione finora
- Understanding Intuitionism: WWW - Math.princeton - Edu Nelson Papers - HTMLDocumento20 pagineUnderstanding Intuitionism: WWW - Math.princeton - Edu Nelson Papers - HTMLEpic WinNessuna valutazione finora
- Essential Selfadjointness of The Graph-LaplacianDocumento56 pagineEssential Selfadjointness of The Graph-LaplacianLuis Alberto FuentesNessuna valutazione finora
- Thesis Proposal: Graph Structured Statistical Inference: James SharpnackDocumento20 pagineThesis Proposal: Graph Structured Statistical Inference: James SharpnackaliNessuna valutazione finora
- Regression Analysis mcq1 PDFDocumento9 pagineRegression Analysis mcq1 PDFShi TingNessuna valutazione finora
- Ellie Draves Unc Graph Theory FinalDocumento19 pagineEllie Draves Unc Graph Theory Finalapi-290910215Nessuna valutazione finora
- Introduction To Curve FittingDocumento10 pagineIntroduction To Curve FittingscjofyWFawlroa2r06YFVabfbajNessuna valutazione finora
- MAS202 - Homework For Chapter 13-14Documento7 pagineMAS202 - Homework For Chapter 13-14Bui Van Anh (K15 HL)Nessuna valutazione finora
- Elements in Mathematics, Economics, Basic EngineeringDocumento1.656 pagineElements in Mathematics, Economics, Basic Engineeringkristan7100% (1)
- Good BayesianNetworksPrimerDocumento23 pagineGood BayesianNetworksPrimerpradnya kingeNessuna valutazione finora
- Structure Learning in Graphical ModelingDocumento28 pagineStructure Learning in Graphical ModelingNick NikzadNessuna valutazione finora
- Google Pagerank: The World'S Largest Matrix ComputationDocumento13 pagineGoogle Pagerank: The World'S Largest Matrix ComputationMiuchdavidsNessuna valutazione finora
- Associative PropertyDocumento6 pagineAssociative PropertyNupur PalNessuna valutazione finora
- Electromagnetism Using Geometric Algebra Versus ComponentsDocumento22 pagineElectromagnetism Using Geometric Algebra Versus ComponentsNilson Yecid BautistaNessuna valutazione finora
- E K-Algebras Are Associative K-Algebras Are Obtained by Ignoring Permutations. UsDocumento15 pagineE K-Algebras Are Associative K-Algebras Are Obtained by Ignoring Permutations. UsEpic WinNessuna valutazione finora
- 18CSO106T Data Analysis Using Open Source Tool: Question BankDocumento26 pagine18CSO106T Data Analysis Using Open Source Tool: Question BankShivaditya singhNessuna valutazione finora
- 13 Network IonDocumento23 pagine13 Network Ionmorgoth12Nessuna valutazione finora
- Computing Persistent Homology: Afra Zomorodian and Gunnar CarlssonDocumento15 pagineComputing Persistent Homology: Afra Zomorodian and Gunnar CarlssonJuanjo Fernandez ImazNessuna valutazione finora
- Regression Analysis - VCE Further MathematicsDocumento5 pagineRegression Analysis - VCE Further MathematicsPNessuna valutazione finora
- Bayesian Nonparametrics and The Probabilistic Approach To ModellingDocumento27 pagineBayesian Nonparametrics and The Probabilistic Approach To ModellingTalha YousufNessuna valutazione finora
- PracticeExamRegression3024 PDFDocumento13 paginePracticeExamRegression3024 PDFdungnt0406100% (2)
- 3.5 Coefficients of The Interpolating Polynomial: Interpolation and ExtrapolationDocumento4 pagine3.5 Coefficients of The Interpolating Polynomial: Interpolation and ExtrapolationVinay GuptaNessuna valutazione finora
- CS3491 Unit 2 AimlDocumento21 pagineCS3491 Unit 2 Aimlchandranhema982Nessuna valutazione finora
- 2 Graphical Models in A Nutshell: Daphne Koller, Nir Friedman, Lise Getoor and Ben TaskarDocumento43 pagine2 Graphical Models in A Nutshell: Daphne Koller, Nir Friedman, Lise Getoor and Ben TaskarFahad Ahmad KhanNessuna valutazione finora
- A Quality Improvement Initiative To Engage Older Adults in The DiDocumento128 pagineA Quality Improvement Initiative To Engage Older Adults in The Disara mohamedNessuna valutazione finora
- 01ESS - Introducing Siebel ApplicationsDocumento24 pagine01ESS - Introducing Siebel ApplicationsRajaNessuna valutazione finora
- Final PS-37 Election Duties 06-02-24 1125pm)Documento183 pagineFinal PS-37 Election Duties 06-02-24 1125pm)Muhammad InamNessuna valutazione finora
- Reported Speech StatementsDocumento1 paginaReported Speech StatementsEmilijus Bartasevic100% (1)
- E1979017519 PDFDocumento7 pagineE1979017519 PDFAnant HatkamkarNessuna valutazione finora
- Work Teams and GroupsDocumento6 pagineWork Teams and GroupsFides AvendanNessuna valutazione finora
- Finding Nemo 2Documento103 pagineFinding Nemo 2julianaNessuna valutazione finora
- Mathematics Paper 1 TZ2 HLDocumento16 pagineMathematics Paper 1 TZ2 HLPavlos StavropoulosNessuna valutazione finora
- Quarter 3 Week 6Documento4 pagineQuarter 3 Week 6Ivy Joy San PedroNessuna valutazione finora
- Viva QuestionsDocumento3 pagineViva QuestionssanjayshekarncNessuna valutazione finora
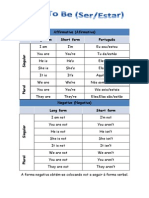
- Affirmative (Afirmativa) Long Form Short Form PortuguêsDocumento3 pagineAffirmative (Afirmativa) Long Form Short Form PortuguêsAnitaYangNessuna valutazione finora
- 2009 Annual Report - NSCBDocumento54 pagine2009 Annual Report - NSCBgracegganaNessuna valutazione finora
- Case Blue Ribbon Service Electrical Specifications Wiring Schematics Gss 1308 CDocumento22 pagineCase Blue Ribbon Service Electrical Specifications Wiring Schematics Gss 1308 Cjasoncastillo060901jtd100% (132)
- Zero Power Factor Method or Potier MethodDocumento1 paginaZero Power Factor Method or Potier MethodMarkAlumbroTrangiaNessuna valutazione finora
- Accounting 110: Acc110Documento19 pagineAccounting 110: Acc110ahoffm05100% (1)
- Playwriting Pedagogy and The Myth of IntrinsicDocumento17 paginePlaywriting Pedagogy and The Myth of IntrinsicCaetano BarsoteliNessuna valutazione finora
- ID2b8b72671-2013 Apush Exam Answer KeyDocumento2 pagineID2b8b72671-2013 Apush Exam Answer KeyAnonymous ajlhvocNessuna valutazione finora
- Syllabus/Course Specifics - Fall 2009: TLT 480: Curricular Design and InnovationDocumento12 pagineSyllabus/Course Specifics - Fall 2009: TLT 480: Curricular Design and InnovationJonel BarrugaNessuna valutazione finora
- Brochure - Digital Banking - New DelhiDocumento4 pagineBrochure - Digital Banking - New Delhiankitgarg13Nessuna valutazione finora
- MAT2355 Final 2002Documento8 pagineMAT2355 Final 2002bojie_97965Nessuna valutazione finora
- A Passage To AfricaDocumento25 pagineA Passage To AfricaJames Reinz100% (2)
- NCPDocumento3 pagineNCPchesca_paunganNessuna valutazione finora
- "What Is A Concept Map?" by (Novak & Cañas, 2008)Documento4 pagine"What Is A Concept Map?" by (Novak & Cañas, 2008)WanieNessuna valutazione finora
- Your Free Buyer Persona TemplateDocumento8 pagineYour Free Buyer Persona Templateel_nakdjoNessuna valutazione finora
- Thesis FulltextDocumento281 pagineThesis FulltextEvgenia MakantasiNessuna valutazione finora
- Awareness and Usage of Internet Banking Facilities in Sri LankaDocumento18 pagineAwareness and Usage of Internet Banking Facilities in Sri LankaTharindu Thathsarana RajapakshaNessuna valutazione finora
- Julie Jacko - Professor of Healthcare InformaticsDocumento1 paginaJulie Jacko - Professor of Healthcare InformaticsjuliejackoNessuna valutazione finora
- Ghalib TimelineDocumento2 pagineGhalib Timelinemaryam-69Nessuna valutazione finora
- Alexander Blok - 'The King in The Square', Slavonic and East European Review, 12 (36), 1934Documento25 pagineAlexander Blok - 'The King in The Square', Slavonic and East European Review, 12 (36), 1934scott brodieNessuna valutazione finora
- Lesson Plan Pumpkin Moon SandDocumento3 pagineLesson Plan Pumpkin Moon Sandapi-273177086Nessuna valutazione finora