Potrebbero piacerti anche
- Relleno de inundación: Relleno de inundación: exploración del terreno dinámico de la visión por computadoraDa EverandRelleno de inundación: Relleno de inundación: exploración del terreno dinámico de la visión por computadoraNessuna valutazione finora
- Geometric modeling in computer: Aided geometric designDa EverandGeometric modeling in computer: Aided geometric designNessuna valutazione finora
- Analisis de AlgoritmosDocumento6 pagineAnalisis de Algoritmossol malacariNessuna valutazione finora
- Algoritmo VorazDocumento5 pagineAlgoritmo VorazRomer Freddy Paredes MaurielNessuna valutazione finora
- Algoritmo de DijkstraDocumento3 pagineAlgoritmo de DijkstranelsonandryevNessuna valutazione finora
- Prim y KruskalDocumento6 paginePrim y KruskalLeo SalazarNessuna valutazione finora
- Árboles de ExpansiónDocumento4 pagineÁrboles de ExpansiónNilton Cruz CornejoNessuna valutazione finora
- Algoritmo de DijkstraDocumento19 pagineAlgoritmo de DijkstraVictor Reyna100% (1)
- Algoritmo de PrimDocumento7 pagineAlgoritmo de PrimAtziry Denisse G NNessuna valutazione finora
- SubalgoritmosDocumento6 pagineSubalgoritmosmartin_rrNessuna valutazione finora
- Algoritmo de DijkstraDocumento7 pagineAlgoritmo de DijkstraErika Xiomara ArrisiagaNessuna valutazione finora
- Algoritmo de PrimDocumento8 pagineAlgoritmo de PrimFrancisco MartínezNessuna valutazione finora
- Aplicación de Arboles de PRIM y KruskalDocumento7 pagineAplicación de Arboles de PRIM y KruskalManuel PeñalozaNessuna valutazione finora
- Control 2Documento4 pagineControl 2claudioNessuna valutazione finora
- AdaDocumento37 pagineAdaPlusMgdvSesaNessuna valutazione finora
- Informe N3-Grace RamirezDocumento16 pagineInforme N3-Grace RamirezThonny AleNessuna valutazione finora
- Codigos de Huffman (Greedy)Documento18 pagineCodigos de Huffman (Greedy)Fredy Alonzo Rojas BerrospiNessuna valutazione finora
- Informe Camino Mas CortoDocumento14 pagineInforme Camino Mas CortoDUVAN FELIPE PARADA RUIZNessuna valutazione finora
- Alg de Floyd-Warshal y Prim1.2Documento12 pagineAlg de Floyd-Warshal y Prim1.2Patricia Lorena FernándezNessuna valutazione finora
- Ejercicios de Consolidacion PP3Documento3 pagineEjercicios de Consolidacion PP3marianly morales martinezNessuna valutazione finora
- Karatsuba Generalizacion EspanolDocumento24 pagineKaratsuba Generalizacion EspanolJuan Pastor RamosNessuna valutazione finora
- Proyecto Final-Matematicas DiscretasDocumento22 pagineProyecto Final-Matematicas DiscretasAletse Solano HermidaNessuna valutazione finora
- Algoritmos Concurrentes y AplicacionesDocumento38 pagineAlgoritmos Concurrentes y AplicacionesAndrés Francisco Ahumada Duarte100% (1)
- Sustentacion FinalDocumento19 pagineSustentacion FinalJuliana DazaNessuna valutazione finora
- Algoritmo de PrimDocumento3 pagineAlgoritmo de PrimWilliamFernandoNessuna valutazione finora
- Algoritmo de DijkstraDocumento7 pagineAlgoritmo de DijkstraHerbert VCNessuna valutazione finora
- Clase 4 Algoritmos de GrafosDocumento20 pagineClase 4 Algoritmos de GrafosCali SolisNessuna valutazione finora
- Algoritmo de KruskalDocumento28 pagineAlgoritmo de KruskalIblingLlanosNessuna valutazione finora
- Algoritmo de StrassenDocumento7 pagineAlgoritmo de StrassenEder León100% (2)
- DijkstraDocumento5 pagineDijkstraCristhian GarciaNessuna valutazione finora
- Mmdi U3 A3 XxyyDocumento7 pagineMmdi U3 A3 XxyyAndres FloresNessuna valutazione finora
- Algoritmo de DijkstraDocumento5 pagineAlgoritmo de DijkstraJairo GusquiNessuna valutazione finora
- Tcedd U4Documento12 pagineTcedd U4Hector LopezNessuna valutazione finora
- Tarea9EstructuraDatos CarlosZepeda 62111620Documento6 pagineTarea9EstructuraDatos CarlosZepeda 62111620Carlos David Zepeda RodriguezNessuna valutazione finora
- Richard Arias NDocumento8 pagineRichard Arias NRichard AriasNessuna valutazione finora
- 5.1 Ejercicios - Complementarios - 1Documento3 pagine5.1 Ejercicios - Complementarios - 1crisclis23Nessuna valutazione finora
- Taller Algebra Lineal y Programación en PythonDocumento6 pagineTaller Algebra Lineal y Programación en PythonJuan diego ValenciaNessuna valutazione finora
- Ejerc6 2Documento8 pagineEjerc6 2romantico2011Nessuna valutazione finora
- Algoritmo de KruskalDocumento4 pagineAlgoritmo de KruskalGerman MariscalNessuna valutazione finora
- Fundamentos Básicos de Matlab - SimulinkDocumento106 pagineFundamentos Básicos de Matlab - Simulinkjcinostroza99Nessuna valutazione finora
- Ejercicios Con OctaveDocumento19 pagineEjercicios Con OctaveEannyNessuna valutazione finora
- Práctica Ciclos WhileDocumento7 paginePráctica Ciclos WhileJazmín LópezNessuna valutazione finora
- Actividad 9-Aplicaciones Prácticas Estructuras Discretas - Grafos y Árboles - Proyecto de ClaseDocumento12 pagineActividad 9-Aplicaciones Prácticas Estructuras Discretas - Grafos y Árboles - Proyecto de ClaseJAMER OLAYANessuna valutazione finora
- Informe de Examen de Suficiencia EDA IIDocumento14 pagineInforme de Examen de Suficiencia EDA IIDayselNessuna valutazione finora
- Algoritmo de DijkstraDocumento29 pagineAlgoritmo de DijkstraPedro NuñezNessuna valutazione finora
- Practica 3Documento10 paginePractica 3dafne yudcovskyNessuna valutazione finora
- Taller 1.. Anexo Guía de Actividad 1 Unidad 1 Analisis Numerico Jhonny Rivera Upc 2 2021Documento2 pagineTaller 1.. Anexo Guía de Actividad 1 Unidad 1 Analisis Numerico Jhonny Rivera Upc 2 2021ALCIVER PEÑALOZA HERRERANessuna valutazione finora
- Algoritmos GRAFOS Ordenar AristasDocumento23 pagineAlgoritmos GRAFOS Ordenar AristasAndres FelipeNessuna valutazione finora
- Ejemplo#1 C-C++ GrafosDocumento4 pagineEjemplo#1 C-C++ GrafosDiego Rudel MonterrozaNessuna valutazione finora
- Clase Math API JavaDocumento13 pagineClase Math API JavaMarco Jaramillo OrtegaNessuna valutazione finora
- Informe 3Documento15 pagineInforme 3delvis mendezNessuna valutazione finora
- Practica 1. Complejidad Algorítmica de Algoritmos Iterativos y RecursivosDocumento10 paginePractica 1. Complejidad Algorítmica de Algoritmos Iterativos y RecursivosFrancisco Xavier Perez SanjuanNessuna valutazione finora
- Algoritmo de Dijkstra - Wikipedia, La Enciclopedia LibreDocumento4 pagineAlgoritmo de Dijkstra - Wikipedia, La Enciclopedia LibreOrlando Rodriguez CrespoNessuna valutazione finora
- AyeddDocumento13 pagineAyeddMatias BoniNessuna valutazione finora
- 66 Problemas Resueltos de Análisis y Diseño de AlgoritmosDocumento82 pagine66 Problemas Resueltos de Análisis y Diseño de AlgoritmosLaenetGalumetteJosephJuniorPaulNessuna valutazione finora
- Clase 2Documento37 pagineClase 2carolina montenegroNessuna valutazione finora
- Algoritmo de DaistraDocumento19 pagineAlgoritmo de DaistraJesus LeDds Pillaca CárdenasNessuna valutazione finora
- Investigacion de Operaciones TRANSPORTE Y REDESDocumento10 pagineInvestigacion de Operaciones TRANSPORTE Y REDESKarina Parra Gil0% (1)
- Capitulo 4Documento24 pagineCapitulo 4Jose Luis Rivas SaromoNessuna valutazione finora
- Instructivo para Instalar El VysorDocumento21 pagineInstructivo para Instalar El VysorPaul ValdezNessuna valutazione finora
- 200427-Programa Analitico Cad400Documento8 pagine200427-Programa Analitico Cad400Alexander Muriel HilariNessuna valutazione finora
- Clase 5 MEDIDAS DE POSICION PDFDocumento24 pagineClase 5 MEDIDAS DE POSICION PDFDENNIS PABEL RAMIRO MAMANI SIMEONNessuna valutazione finora
- Tema08 - Uml MaDocumento21 pagineTema08 - Uml MaLeonardo DiazNessuna valutazione finora
- Monografias Del Trabajo de WordDocumento6 pagineMonografias Del Trabajo de WordroscondezoNessuna valutazione finora
- Estructuras Simples y Dobles Conceptos BasicosDocumento16 pagineEstructuras Simples y Dobles Conceptos BasicosSamuel AlemánNessuna valutazione finora
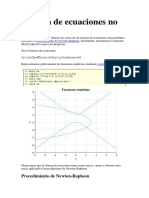
- Sistema de Ecuaciones No LinealesDocumento9 pagineSistema de Ecuaciones No LinealesWanderley Kevin Alccaihuaman Quispe0% (1)
- Bases de Datos Relacionales en La Clinica - v3 PDFDocumento41 pagineBases de Datos Relacionales en La Clinica - v3 PDFAldo Navarro ReyesNessuna valutazione finora
- Aplicacion de La Teoria de Las VibracionesDocumento13 pagineAplicacion de La Teoria de Las Vibracionescarlos ignacio loya sanchezNessuna valutazione finora
- AA1nGuianaprendizajen2021 3160b553c7df549Documento7 pagineAA1nGuianaprendizajen2021 3160b553c7df549JulioNessuna valutazione finora
- Estado Del Arte Internet de Las CosasDocumento4 pagineEstado Del Arte Internet de Las CosasDanielAvilaNessuna valutazione finora
- Regresion CuantilicaDocumento4 pagineRegresion CuantilicaSilvia_Cornejo0986032748Nessuna valutazione finora
- Paso 5 Grupo 212026 - 8Documento17 paginePaso 5 Grupo 212026 - 8julio sorianoNessuna valutazione finora
- Problemas 2Documento6 pagineProblemas 2Angel VargasNessuna valutazione finora
- Os Elementos de La Sección Transversal de Una Carretera Influyen Sobre Sus Características OperativasDocumento34 pagineOs Elementos de La Sección Transversal de Una Carretera Influyen Sobre Sus Características OperativasMariana Villasante VargasNessuna valutazione finora
- BIIN U2 ContenidoDocumento65 pagineBIIN U2 ContenidoPablo PasillasNessuna valutazione finora
- FacturaloPeru - Manual de Usuario - 10-18Documento23 pagineFacturaloPeru - Manual de Usuario - 10-18UnPocoDeTodo PeruNessuna valutazione finora
- Trabajo Avionica - Sistemas de IonDocumento36 pagineTrabajo Avionica - Sistemas de IonKelvin Allan Soler LopezNessuna valutazione finora
- Interpretacion de Planos Semana 4Documento5 pagineInterpretacion de Planos Semana 4Karen CortezNessuna valutazione finora
- Actividad Grupo 3 Salarios Tabla DinamicaDocumento6 pagineActividad Grupo 3 Salarios Tabla DinamicaSandra PizaNessuna valutazione finora
- Semana 8 Planos ElectricoDocumento8 pagineSemana 8 Planos Electricotomas andres gonzalez mancillaNessuna valutazione finora
- Variable Session en ASP .NET - TechClub TajamarDocumento10 pagineVariable Session en ASP .NET - TechClub Tajamaranthony villanuevaNessuna valutazione finora
- Solucion Caso Practico Clase 5Documento8 pagineSolucion Caso Practico Clase 5Boris VélezNessuna valutazione finora
- Sistemas Contable EXPOSICIONDocumento13 pagineSistemas Contable EXPOSICIONAlexis AcsaraNessuna valutazione finora
- Ig en GoogleDocumento20 pagineIg en Googletatis.re.11Nessuna valutazione finora
- Informe Sobre Lista de Chequeo Según Decreto 1072Documento2 pagineInforme Sobre Lista de Chequeo Según Decreto 1072Johanna JirleyNessuna valutazione finora
- TP2 Word Computacion UnlamDocumento1 paginaTP2 Word Computacion UnlamSabrina TorresNessuna valutazione finora
- Introducción Al Análisis de Regresión Simple - EstadíticaDocumento62 pagineIntroducción Al Análisis de Regresión Simple - EstadíticaRafael Meza GarcíaNessuna valutazione finora
- Cambio de v3f Po KDLDocumento64 pagineCambio de v3f Po KDLEcocec Centralita Electronica ComplementariaNessuna valutazione finora
- FacturaDocumento6 pagineFacturaAMPARO INOA SERVICE SRLNessuna valutazione finora