Potrebbero piacerti anche
- UNIT - 1 Advanced Algorithm PDFDocumento43 pagineUNIT - 1 Advanced Algorithm PDFbharat emandiNessuna valutazione finora
- Searching AlgorithmsDocumento5 pagineSearching AlgorithmsTI Journals PublishingNessuna valutazione finora
- AlgorithmsDocumento61 pagineAlgorithmsSergeyChepurinNessuna valutazione finora
- M.C.a. (Sem - II) Paper - I - Data StructuresDocumento132 pagineM.C.a. (Sem - II) Paper - I - Data Structuresbaluchandrashekar2008Nessuna valutazione finora
- Error Detection and CorrectionDocumento38 pagineError Detection and CorrectionKipkirui TopiasNessuna valutazione finora
- Mastering Data Structures and Algorithms in C and C++Da EverandMastering Data Structures and Algorithms in C and C++Nessuna valutazione finora
- Test Portfolio Performance ResearchDocumento302 pagineTest Portfolio Performance ResearchManop Metha100% (1)
- Studying For A Tech Interview SucksDocumento8 pagineStudying For A Tech Interview SucksJoy RahmanNessuna valutazione finora
- DAA Interview Questions and AnswersDocumento9 pagineDAA Interview Questions and AnswersPranjal KumarNessuna valutazione finora
- Searching and SortingDocumento12 pagineSearching and Sortingabc defNessuna valutazione finora
- Research About Data Structures, Searching and Sorting AlgorithmsDocumento8 pagineResearch About Data Structures, Searching and Sorting AlgorithmsOlgaNessuna valutazione finora
- Computational Thinking NotesDocumento49 pagineComputational Thinking NotesCarl MhongweiNessuna valutazione finora
- DAA Questions & AnswersDocumento26 pagineDAA Questions & AnswersTusharNessuna valutazione finora
- Daa Q&aDocumento8 pagineDaa Q&aAryan PrasadNessuna valutazione finora
- AOA Viva QuestionDocumento8 pagineAOA Viva QuestionJay MhatreNessuna valutazione finora
- Bds Notes For Serching SortingDocumento9 pagineBds Notes For Serching SortingsparenileshNessuna valutazione finora
- The Practicality of Search Algorithms Within The Realm of Data Structures.Documento6 pagineThe Practicality of Search Algorithms Within The Realm of Data Structures.Nathaniel Jose Pascual (BSIT 1-D)Nessuna valutazione finora
- Unit - I Divide and Conquer: RecursivelyDocumento10 pagineUnit - I Divide and Conquer: Recursivelyramesh_508Nessuna valutazione finora
- BinarryDocumento3 pagineBinarryRafiullah HaqmalNessuna valutazione finora
- Sorting Algorithms & Data StructuresDocumento4 pagineSorting Algorithms & Data Structuresarceo.ezekiel0Nessuna valutazione finora
- DSA & DAA Fast StudyDocumento6 pagineDSA & DAA Fast StudyrkpythonNessuna valutazione finora
- 8 - 19UITPC301 - A - 7 - 28unit - 5 FundamentalsDocumento2 pagine8 - 19UITPC301 - A - 7 - 28unit - 5 FundamentalsKISHORE ANTHONYNessuna valutazione finora
- DSA Questions: Insertion Adding A Data Item Deletion Removing A Data ItemDocumento7 pagineDSA Questions: Insertion Adding A Data Item Deletion Removing A Data ItemTinotenda ChakareNessuna valutazione finora
- DSA Short NotesDocumento4 pagineDSA Short NotesJitendra ChoudharyNessuna valutazione finora
- Rajarambapu Institute of Technology, Sakharale: "Case Study On Searching Algorithms"Documento11 pagineRajarambapu Institute of Technology, Sakharale: "Case Study On Searching Algorithms"ASasSNessuna valutazione finora
- Data StructureDocumento5 pagineData Structuremohit1485Nessuna valutazione finora
- Algorithms-Analysis Framework Binary SearchDocumento15 pagineAlgorithms-Analysis Framework Binary Searchkaushik.grNessuna valutazione finora
- Lab 04 - Sorting and SearchingDocumento8 pagineLab 04 - Sorting and SearchingYasir NiaziNessuna valutazione finora
- AAD AssignmentDocumento20 pagineAAD Assignment1239 ShrutiNessuna valutazione finora
- Unit 9 Searching: Structure Page NosDocumento10 pagineUnit 9 Searching: Structure Page NosAnup RaghuveerNessuna valutazione finora
- Chapter-2 - Array Searching and SortingDocumento21 pagineChapter-2 - Array Searching and SortingKartik TyagiNessuna valutazione finora
- Sorting and SearchingDocumento17 pagineSorting and Searchingnehavj664Nessuna valutazione finora
- Bridge Notes UNIT 3 P22MCABC2 Data StructuresDocumento23 pagineBridge Notes UNIT 3 P22MCABC2 Data Structuresvathypadma288Nessuna valutazione finora
- Ict HomeworkDocumento15 pagineIct HomeworkКаримов ӘділбекNessuna valutazione finora
- Chapter-5. Sorting and SearchingDocumento7 pagineChapter-5. Sorting and SearchingQuazi Hasnat IrfanNessuna valutazione finora
- Searching AlgorithmsDocumento22 pagineSearching AlgorithmsEvertonNessuna valutazione finora
- Sorting Arranges The Numerical and Alphabetical Data Present in A List in A Specific Order orDocumento4 pagineSorting Arranges The Numerical and Alphabetical Data Present in A List in A Specific Order orSaravanan NallusamyNessuna valutazione finora
- Name: P Surya Narayana Subject: Summer Internship Section: K18Uw REG NO: 11802507 Course Code: Cse443 Topic: Dsa Self PacedDocumento33 pagineName: P Surya Narayana Subject: Summer Internship Section: K18Uw REG NO: 11802507 Course Code: Cse443 Topic: Dsa Self PacedSURYANessuna valutazione finora
- Data Structutes Using C'Documento7 pagineData Structutes Using C'Sumitavo NagNessuna valutazione finora
- Linear SearchDocumento11 pagineLinear SearchSafal BhattaraiNessuna valutazione finora
- Comprehensive Viva VoceDocumento168 pagineComprehensive Viva VoceDHANASEENUVASAN DNessuna valutazione finora
- Sorting CompDocumento18 pagineSorting CompTANISHQ KALENessuna valutazione finora
- Binary Search Algorithm - WikipediaDocumento17 pagineBinary Search Algorithm - WikipediaIoana FarcașNessuna valutazione finora
- Principales Algoritmos de BusquedaDocumento10 paginePrincipales Algoritmos de BusquedaSEBAS OLARTENessuna valutazione finora
- Data Structures and AlgorithmsDocumento6 pagineData Structures and Algorithmsil.outasslaNessuna valutazione finora
- Assignm Ent Number Title Numbe R: Lab Manual - Data Structures 2020 PatternDocumento58 pagineAssignm Ent Number Title Numbe R: Lab Manual - Data Structures 2020 PatternAmey KottawarNessuna valutazione finora
- Internal Sorting:Definition: When The Entire Dataset Can FitDocumento12 pagineInternal Sorting:Definition: When The Entire Dataset Can FitShubham KumarNessuna valutazione finora
- CSC 425 Summary NoteDocumento13 pagineCSC 425 Summary Noteayomidekelly21Nessuna valutazione finora
- Assignment 4 CSE 205Documento8 pagineAssignment 4 CSE 205Dewank SainiNessuna valutazione finora
- Unit 7Documento15 pagineUnit 7Vivekananda Ganjigunta NarayanaNessuna valutazione finora
- Algorithms and Data Structures Sorting AlgorithmsDocumento5 pagineAlgorithms and Data Structures Sorting AlgorithmsYogesh GiriNessuna valutazione finora
- Data Structures Se E&Tc List of PracticalsDocumento23 pagineData Structures Se E&Tc List of Practicalsdhruv_bhattacharya_1Nessuna valutazione finora
- Abstract Data TypeDocumento5 pagineAbstract Data TypeNamal No OorNessuna valutazione finora
- Unit 5 SearchingSortingHashing PDFDocumento53 pagineUnit 5 SearchingSortingHashing PDFAnonymous ab2R0jK0aNessuna valutazione finora
- Part-A 1) What Is Binary Search?: Sorting Algorithm Comparison Sort Quicksort Heapsort Merge SortDocumento9 paginePart-A 1) What Is Binary Search?: Sorting Algorithm Comparison Sort Quicksort Heapsort Merge SortSiddhArth JAinNessuna valutazione finora
- DSA RTU 2022 PaperDocumento15 pagineDSA RTU 2022 PaperAmaan KhokarNessuna valutazione finora
- Hashing: (Data) in A Data Structure To Provide A Faster Way of Finding The Element Using A Hash KeyDocumento12 pagineHashing: (Data) in A Data Structure To Provide A Faster Way of Finding The Element Using A Hash KeyEvertonNessuna valutazione finora
- Algorthim Important QuestionsDocumento9 pagineAlgorthim Important Questionsganesh moorthiNessuna valutazione finora
- Dsa Viva Questions - Coders LodgeDocumento12 pagineDsa Viva Questions - Coders LodgeGulchetan SinghNessuna valutazione finora
- HTML 5 vs. Older HTML Versions: New Doctype, Charset and Page StructureDocumento8 pagineHTML 5 vs. Older HTML Versions: New Doctype, Charset and Page StructurenageshgummadaNessuna valutazione finora
- Lecture 1Documento39 pagineLecture 1Shekhar TiwariNessuna valutazione finora
- HTML 5 vs. Older HTML Versions: New Doctype, Charset and Page StructureDocumento8 pagineHTML 5 vs. Older HTML Versions: New Doctype, Charset and Page StructurenageshgummadaNessuna valutazione finora
- BiometricsPPTPDFDocumento40 pagineBiometricsPPTPDFShekhar TiwariNessuna valutazione finora
- Homework4Documento1 paginaHomework4Shekhar TiwariNessuna valutazione finora
- Homework4Documento1 paginaHomework4Shekhar TiwariNessuna valutazione finora
- Homework4Documento1 paginaHomework4Shekhar TiwariNessuna valutazione finora
- LMECE212PDocumento30 pagineLMECE212PShekhar TiwariNessuna valutazione finora
- Adjoint and Inverse of MatrixDocumento2 pagineAdjoint and Inverse of MatrixAnkur SinghNessuna valutazione finora
- CSE341Documento4 pagineCSE341Shekhar TiwariNessuna valutazione finora
- Features of 8085 MicroprocessorDocumento2 pagineFeatures of 8085 MicroprocessorShekhar TiwariNessuna valutazione finora
- Technical Seminar PresentationDocumento13 pagineTechnical Seminar PresentationShekhar TiwariNessuna valutazione finora
- Cse202 HW1Documento2 pagineCse202 HW1Shekhar TiwariNessuna valutazione finora
- Training Genetic EngineeringDocumento2 pagineTraining Genetic EngineeringShekhar TiwariNessuna valutazione finora
- VTU - B Tech - 18mat21 Advanced Calculus and Numerical Methods - FirstRanker - Com 2Documento3 pagineVTU - B Tech - 18mat21 Advanced Calculus and Numerical Methods - FirstRanker - Com 2Monster ManNessuna valutazione finora
- Dwnload Full Numerical Analysis 10th Edition Burden Solutions Manual PDFDocumento35 pagineDwnload Full Numerical Analysis 10th Edition Burden Solutions Manual PDFmclauglinnelida100% (12)
- Machine Learning Scikit HandsonDocumento4 pagineMachine Learning Scikit HandsonAkshay Sharada Hanmant SuryawanshiNessuna valutazione finora
- Emre Onur Akcan HW3-190302002Documento3 pagineEmre Onur Akcan HW3-190302002EmreOnur AkcanNessuna valutazione finora
- QMB FL. Chap 05Documento32 pagineQMB FL. Chap 05Manula JayawardhanaNessuna valutazione finora
- Control Systems For Robots: Prof. Robert Marmelstein CPSC 527 - Robotics Spring 2010Documento40 pagineControl Systems For Robots: Prof. Robert Marmelstein CPSC 527 - Robotics Spring 2010Ritesh SinghNessuna valutazione finora
- Research Paper by Chirag S ThakerDocumento6 pagineResearch Paper by Chirag S ThakerChirag ThakerNessuna valutazione finora
- Declarative Logic Programming With Primitive Recursive Relations On ListsDocumento14 pagineDeclarative Logic Programming With Primitive Recursive Relations On ListsNtoane Lekuba-Da CubaNessuna valutazione finora
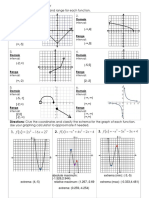
- Directions: Find The Domain and Range For Each FunctionDocumento3 pagineDirections: Find The Domain and Range For Each FunctionKayla IkumaNessuna valutazione finora
- CPM Time Analysis FloatsDocumento23 pagineCPM Time Analysis FloatsHiremathkhushiNessuna valutazione finora
- Deterministic PDA's: Deepak D'SouzaDocumento17 pagineDeterministic PDA's: Deepak D'Souzaashish3586Nessuna valutazione finora
- Flight Fare Prediction Using Machine Learning ApproachDocumento5 pagineFlight Fare Prediction Using Machine Learning ApproachIJRASETPublicationsNessuna valutazione finora
- Week 4 SolutionDocumento10 pagineWeek 4 SolutionbalainsaiNessuna valutazione finora
- Clustered Energy Based Modal Assurance Criterion (CEMAC)Documento4 pagineClustered Energy Based Modal Assurance Criterion (CEMAC)George PapazafeiropoulosNessuna valutazione finora
- Jayden Ambrose - Maths SBA # 2Documento10 pagineJayden Ambrose - Maths SBA # 2jadee9500Nessuna valutazione finora
- 5) Multiple RegressionDocumento8 pagine5) Multiple RegressionSumit MudiNessuna valutazione finora
- SchedulingDocumento55 pagineSchedulingMohan RajNessuna valutazione finora
- Unit Xiii - Analysis of Time Series: Notes StructureDocumento15 pagineUnit Xiii - Analysis of Time Series: Notes StructureNandini JaganNessuna valutazione finora
- Group 6Documento34 pagineGroup 6Naveen KumarNessuna valutazione finora
- CIT 891 TMA 2 Quiz QuestionDocumento3 pagineCIT 891 TMA 2 Quiz QuestionjohnNessuna valutazione finora
- 15 HashTablesDocumento27 pagine15 HashTablesayboaydo26Nessuna valutazione finora
- Sasakian Manifold, K - Contact Riemannian Manifold & Various Curvature Tensor in Contact ManifoldDocumento47 pagineSasakian Manifold, K - Contact Riemannian Manifold & Various Curvature Tensor in Contact Manifolddrdhananjaygupta9Nessuna valutazione finora
- Weatherwax - Conte - Solution - Manual Capitulo 2 y 3Documento59 pagineWeatherwax - Conte - Solution - Manual Capitulo 2 y 3Jorge EstebanNessuna valutazione finora
- UntitledDocumento4 pagineUntitledAB 26Nessuna valutazione finora
- Re PaperDocumento1 paginaRe PaperLearn SamadeshNessuna valutazione finora
- Data Science With PythonDocumento23 pagineData Science With PythonHafiza MariaNessuna valutazione finora
- Experiment-1: AIM: Write A Program To Print "Hello World"Documento24 pagineExperiment-1: AIM: Write A Program To Print "Hello World"Dushyant Kumar RanaNessuna valutazione finora
- Data PreparationDocumento11 pagineData PreparationVivek MunjayasraNessuna valutazione finora