Potrebbero piacerti anche
- Technical Tables for Schools and Colleges: The Commonwealth and International Library Mathematics DivisionDa EverandTechnical Tables for Schools and Colleges: The Commonwealth and International Library Mathematics DivisionNessuna valutazione finora
- n1 n2 Promedio DesviacionDocumento5 paginen1 n2 Promedio DesviacionDayana JaramilloNessuna valutazione finora
- Pokemon GoDocumento3 paginePokemon GoSteve CoinNessuna valutazione finora
- Modelo de Monod Vs HaldaneDocumento30 pagineModelo de Monod Vs Haldanebrodriguez.1704Nessuna valutazione finora
- Class 10 Hindi MarksheetDocumento3 pagineClass 10 Hindi MarksheetLali LalithaNessuna valutazione finora
- Improvement - WelchDocumento9 pagineImprovement - WelchAreeba MalikNessuna valutazione finora
- Experiment No:01 Name of The Experiment: Finding The Average of CT Marks Using MATLABDocumento2 pagineExperiment No:01 Name of The Experiment: Finding The Average of CT Marks Using MATLABShaharior AnikNessuna valutazione finora
- Haul Roads 2hxo9hg 2024 03 13 13 57 06Documento45 pagineHaul Roads 2hxo9hg 2024 03 13 13 57 06hendri sulistiawanNessuna valutazione finora
- Cob LengthDocumento6 pagineCob Lengthhamidaakbar5038Nessuna valutazione finora
- Vi CurveDocumento2 pagineVi CurveBagus NugrohoNessuna valutazione finora
- Calificaciones Cuestionarios Eco Mon 21 I 2021Documento5 pagineCalificaciones Cuestionarios Eco Mon 21 I 2021Alex GallardoNessuna valutazione finora
- Yo-Yo TestDocumento5 pagineYo-Yo TestSrdjan RacicNessuna valutazione finora
- Excel de Sismica de 10 PisosDocumento4 pagineExcel de Sismica de 10 PisoslarryNessuna valutazione finora
- BMI Chart for Boys Ages 0 to 2Documento1 paginaBMI Chart for Boys Ages 0 to 2Ma Rani HaNessuna valutazione finora
- Grocery Store Sales Jan MarDocumento2.317 pagineGrocery Store Sales Jan MarManish SharmaNessuna valutazione finora
- N Problema de Flujo en 2D INICIAR (S/N) Start S Iteracion Iter 600 KX KX 1 KZ KZ 1 H1 h1 10 H2 h2 1 Lineas de Flujo Lflujo 3Documento13 pagineN Problema de Flujo en 2D INICIAR (S/N) Start S Iteracion Iter 600 KX KX 1 KZ KZ 1 H1 h1 10 H2 h2 1 Lineas de Flujo Lflujo 3Daniiel JaramilloNessuna valutazione finora
- Data Dan Grafik Sondir: Nama Proyek: Hari, TGL: Lokasi: Juru Sondir: Nomor Sondir: Kedalaman Ahir: MDocumento7 pagineData Dan Grafik Sondir: Nama Proyek: Hari, TGL: Lokasi: Juru Sondir: Nomor Sondir: Kedalaman Ahir: MIlyas NannmarNessuna valutazione finora
- Data Beban MingguanDocumento9 pagineData Beban MingguanDanielPanggabeanNessuna valutazione finora
- Module 3 RCD Data Toedoe Sept 4 2020Documento11 pagineModule 3 RCD Data Toedoe Sept 4 2020RocisneRocisneNessuna valutazione finora
- Lectura No. Volumen Inicial (LTS) Volumen Final (LTS) Volumen Colectado (LTS)Documento5 pagineLectura No. Volumen Inicial (LTS) Volumen Final (LTS) Volumen Colectado (LTS)Alexander JaraNessuna valutazione finora
- Lectura No. Volumen Inicial (LTS) Volumen Final (LTS) Volumen Colectado (LTS)Documento5 pagineLectura No. Volumen Inicial (LTS) Volumen Final (LTS) Volumen Colectado (LTS)Alexander JaraNessuna valutazione finora
- Question 3.2 & 3. 4 EditedDocumento8 pagineQuestion 3.2 & 3. 4 EditedLouis LieuNessuna valutazione finora
- Eagle Southwest Custom Reroof Select 2013Documento20 pagineEagle Southwest Custom Reroof Select 2013RODRIGO ANTONIO MARQUEZ NAVARRETENessuna valutazione finora
- Rangetop Burner ResultsDocumento4 pagineRangetop Burner Resultskov709324Nessuna valutazione finora
- R16 III B.Tech II Semester MidDocumento119 pagineR16 III B.Tech II Semester MidSunil KumarNessuna valutazione finora
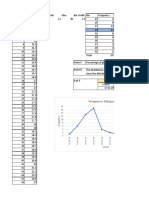
- Frequency Polygon: ScoresDocumento5 pagineFrequency Polygon: ScoresLuisaGomesNessuna valutazione finora
- School of Business, BBA Program Management Information System, MIS 207Documento2 pagineSchool of Business, BBA Program Management Information System, MIS 207shamim islam limonNessuna valutazione finora
- Sistemas Contabilidad Operaciones Economia Business: TotalDocumento26 pagineSistemas Contabilidad Operaciones Economia Business: TotalJs RiveraNessuna valutazione finora
- TR6Documento37 pagineTR6URBIEN Jovencio IIINessuna valutazione finora
- FORMAT MEAN AND MPS IN FILIPINO FOR 7TH GRADEDocumento36 pagineFORMAT MEAN AND MPS IN FILIPINO FOR 7TH GRADERomar SemicNessuna valutazione finora
- Advantage and Disadvantage SimulationDocumento247 pagineAdvantage and Disadvantage SimulationWilliam Henry CaddellNessuna valutazione finora
- Distribution of Data PointsDocumento104 pagineDistribution of Data PointsLuis Alberto YomoNessuna valutazione finora
- Grafica Ruta 3 FanyDocumento5 pagineGrafica Ruta 3 FanyMelanie Rosete CruzNessuna valutazione finora
- TCO Access Go Now Compact ActsDocumento3 pagineTCO Access Go Now Compact ActskeshavNessuna valutazione finora
- PerhitunganDocumento223 paginePerhitunganWidya AriskaNessuna valutazione finora
- Nro Codigo Ex - 1 P1 Prom - 1: Turis MODocumento2 pagineNro Codigo Ex - 1 P1 Prom - 1: Turis MOWalther ChaupiNessuna valutazione finora
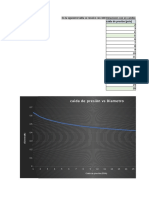
- Caìda de Presiòn (Psia)Documento2 pagineCaìda de Presiòn (Psia)Dilan MatiusNessuna valutazione finora
- 2019 07 Can f1 p2 Timing Secondpracticesessionlaptimes v01Documento7 pagine2019 07 Can f1 p2 Timing Secondpracticesessionlaptimes v01frehanyaqNessuna valutazione finora
- Common courses and specialty subjectsDocumento30 pagineCommon courses and specialty subjectschill kinokoNessuna valutazione finora
- Bimo Pambudi Biodisel GCDocumento1 paginaBimo Pambudi Biodisel GCbimo pambudi astonoNessuna valutazione finora
- Corn PineappleDocumento13 pagineCorn PineappleMariz RonquilloNessuna valutazione finora
- Clases EstadisticaDocumento9 pagineClases EstadisticaDaniel Esteban Contreras HernandezNessuna valutazione finora
- Data Berat PlywoodDocumento13 pagineData Berat PlywoodAndi RismayantiNessuna valutazione finora
- Lesson 6-1-Cost of EquityDocumento97 pagineLesson 6-1-Cost of EquityThanh Huyền TrầnNessuna valutazione finora
- Regression-Analysis Ankit PatawariDocumento2 pagineRegression-Analysis Ankit PatawariAnkit PatawariNessuna valutazione finora
- Severed Books - Mega Dungeon MakerDocumento130 pagineSevered Books - Mega Dungeon MakerandyjazminNessuna valutazione finora
- Tumbukan (N) Pemb. Mistar (MM) Penetrasi (MM) Tumb (Per 25 MM) Nilai CBR (%) Grafik 1 Grafik 2Documento4 pagineTumbukan (N) Pemb. Mistar (MM) Penetrasi (MM) Tumb (Per 25 MM) Nilai CBR (%) Grafik 1 Grafik 2Marcellino ArifinNessuna valutazione finora
- Rank Base 19 EpiiDocumento4 pagineRank Base 19 EpiiJosé Fernando Huamaní GarcíaNessuna valutazione finora
- Chicudado 1Documento24 pagineChicudado 1Jhonatan Rojas MoreanoNessuna valutazione finora
- Lci - LCSDocumento5 pagineLci - LCSMARCO ANTONIO TURPO YANANessuna valutazione finora
- CARDATA1Documento8 pagineCARDATA1Jesse CookNessuna valutazione finora
- AlcoholesDocumento10 pagineAlcoholesKevin PeñaNessuna valutazione finora
- ERM Practice DataDocumento15 pagineERM Practice DataVishal jainNessuna valutazione finora
- GTPDocumento3 pagineGTPRobertIonicaNessuna valutazione finora
- Blue Moon Private Limited (BMPL)Documento7 pagineBlue Moon Private Limited (BMPL)ADAM NUR ALIF MOHD KHALIDNessuna valutazione finora
- Heavy metal concentrations in UK rivers from 1980-2013Documento5 pagineHeavy metal concentrations in UK rivers from 1980-2013FRANK ANDERSON ESPEJO VALDEZNessuna valutazione finora
- V10-B Applied Physics Monday 2pmDocumento2 pagineV10-B Applied Physics Monday 2pmMuhammad Anas ToheedNessuna valutazione finora
- Maximum Quantities of Extinguishing Agents Based On The Largest Dimension BDocumento2 pagineMaximum Quantities of Extinguishing Agents Based On The Largest Dimension BM AliNessuna valutazione finora
- PromedioDocumento1 paginaPromedioisabel vargasNessuna valutazione finora
- Schioetz Tonometer - Conversion Table: 5.5 GM 7.5 GM 10.0 GM 15.0 GM Scale Reading Pressure in MM HG Scale ReadingDocumento1 paginaSchioetz Tonometer - Conversion Table: 5.5 GM 7.5 GM 10.0 GM 15.0 GM Scale Reading Pressure in MM HG Scale Readingcookies landNessuna valutazione finora
- Ethnographic ResearchDocumento36 pagineEthnographic ResearchThảo TuberoseNessuna valutazione finora
- Filed Methods in Psych, ReviewerDocumento32 pagineFiled Methods in Psych, ReviewerKrisha Avorque100% (1)
- Psychology 300-Midterm Exam IDocumento12 paginePsychology 300-Midterm Exam IGurleen RandhawaNessuna valutazione finora
- Marketing Management: 4 Conducting Marketing Research and Forecasting DemandDocumento57 pagineMarketing Management: 4 Conducting Marketing Research and Forecasting DemandVamsi KrishnaNessuna valutazione finora
- Powerpoint Dissertation Proposal Defense OutlineDocumento17 paginePowerpoint Dissertation Proposal Defense OutlineFares EL Deen100% (2)
- Importance of Literature ReviewDocumento4 pagineImportance of Literature Reviewhozul1vohih3100% (1)
- KYAMBOGO UNIVERSITY Reviewed 04.05.2022 - 3Documento23 pagineKYAMBOGO UNIVERSITY Reviewed 04.05.2022 - 3wangolo EmmanuelNessuna valutazione finora
- Research Paper On The Great Depression of The 1930sDocumento8 pagineResearch Paper On The Great Depression of The 1930safnkjdhxlewftq100% (1)
- LESSON - Quantitative Research DesignsDocumento16 pagineLESSON - Quantitative Research DesignsHomer Kurt BugtongNessuna valutazione finora
- Problem 3.6Documento4 pagineProblem 3.6ScribdTranslationsNessuna valutazione finora
- PHD - Advanced Educational StatisticsDocumento8 paginePHD - Advanced Educational StatisticsDenis CadotdotNessuna valutazione finora
- Artikel Skripsi Nailil MunaDocumento17 pagineArtikel Skripsi Nailil MunaNaily&NailaNessuna valutazione finora
- ICSE Class 10 Geography PDFDocumento4 pagineICSE Class 10 Geography PDFVenkatalakshmi NNessuna valutazione finora
- R Code Chi-Square Tests Design ExperimentsDocumento6 pagineR Code Chi-Square Tests Design ExperimentsSiva CNessuna valutazione finora
- Lesson 1 - Chapter 2Documento14 pagineLesson 1 - Chapter 2Darlyn Simon DeleonmasangyaNessuna valutazione finora
- 949 1890 1 SMDocumento10 pagine949 1890 1 SMSholihah BuzzarNessuna valutazione finora
- Scientific Method Review Guide Answer KeyDocumento4 pagineScientific Method Review Guide Answer KeyWilburNessuna valutazione finora
- Operations Reserch Unit 1&2Documento35 pagineOperations Reserch Unit 1&2RoNessuna valutazione finora
- ACFN3111 - Research Methods-Ch05-except QuestionnaireDocumento73 pagineACFN3111 - Research Methods-Ch05-except QuestionnaireKalkidan G/wahidNessuna valutazione finora
- Concept Paper Title Page1Documento5 pagineConcept Paper Title Page1Ella reyNessuna valutazione finora
- The Effect of Lighting On The Worker Productivity: A Study at Malaysia Electronics IndustryDocumento6 pagineThe Effect of Lighting On The Worker Productivity: A Study at Malaysia Electronics IndustryFAIZAL MALEKNessuna valutazione finora
- Course OutlineDocumento2 pagineCourse Outlineميكروسوفت القليوبيةNessuna valutazione finora
- Pretest in Research 2Documento2 paginePretest in Research 2Angelica Basco100% (1)
- Personalised and Adaptive LearningDocumento4 paginePersonalised and Adaptive LearningShreemoyee BhattacharyaNessuna valutazione finora
- A Critical Assessment of Positivism and Normativism in EconomicsDocumento7 pagineA Critical Assessment of Positivism and Normativism in EconomicsSAMEEKSHA SUDHINDRA HOSKOTE 2133361Nessuna valutazione finora
- Dissertation On English Language TeachingDocumento8 pagineDissertation On English Language TeachingWriteMyPaperApaFormatToledo100% (1)
- Legal Research and MethodologyDocumento62 pagineLegal Research and MethodologyBrian ChukwuraNessuna valutazione finora
- Research PresentationDocumento22 pagineResearch PresentationRodel AgcaoiliNessuna valutazione finora
- PPT 05Documento21 paginePPT 05Diaz Hesron Deo SimorangkirNessuna valutazione finora
- Data Analysis and Critiquing Statistics in Quantitative ResearchDocumento2 pagineData Analysis and Critiquing Statistics in Quantitative ResearchStephen Camba0% (1)
- Medical English Dialogues: Clear & Simple Medical English Vocabulary for ESL/EFL LearnersDa EverandMedical English Dialogues: Clear & Simple Medical English Vocabulary for ESL/EFL LearnersNessuna valutazione finora
- 7 Shared Skills for Academic IELTS Speaking-WritingDa Everand7 Shared Skills for Academic IELTS Speaking-WritingValutazione: 5 su 5 stelle5/5 (1)
- 500 Really Useful English Phrases: From Intermediate to AdvancedDa Everand500 Really Useful English Phrases: From Intermediate to AdvancedValutazione: 5 su 5 stelle5/5 (2)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormDa EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormValutazione: 5 su 5 stelle5/5 (5)
- Using English Expressions for Real Life: Stepping Stones to Fluency for Advanced ESL LearnersDa EverandUsing English Expressions for Real Life: Stepping Stones to Fluency for Advanced ESL LearnersValutazione: 5 su 5 stelle5/5 (4)
- IELTS Writing Task 2: a Step-by-Step Guide: Everything You Need to Know: Strategies, Tips and Traps, Ideas and VocabularyDa EverandIELTS Writing Task 2: a Step-by-Step Guide: Everything You Need to Know: Strategies, Tips and Traps, Ideas and VocabularyNessuna valutazione finora
- Phrasal Verbs for TOEFL: Hundreds of Phrasal Verbs in DialoguesDa EverandPhrasal Verbs for TOEFL: Hundreds of Phrasal Verbs in DialoguesNessuna valutazione finora
- Business English Vocabulary Builder: Idioms, Phrases, and Expressions in American EnglishDa EverandBusiness English Vocabulary Builder: Idioms, Phrases, and Expressions in American EnglishValutazione: 4.5 su 5 stelle4.5/5 (6)
- Acing Writing in IGCSE English as a Second Language 0510Da EverandAcing Writing in IGCSE English as a Second Language 0510Nessuna valutazione finora
- Spanish Short Stories For Beginners (Vol 1): Use short stories to learn Spanish the fun way with the bilingual reading natural methodDa EverandSpanish Short Stories For Beginners (Vol 1): Use short stories to learn Spanish the fun way with the bilingual reading natural methodValutazione: 4 su 5 stelle4/5 (18)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsDa EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsValutazione: 4.5 su 5 stelle4.5/5 (3)
- The Big Book of English Expressions and Phrasal Verbs for ESL and English Learners; Phrasal Verbs, English Expressions, Idioms, Slang, Informal and Colloquial Expression: Focus on English Big Book SeriesDa EverandThe Big Book of English Expressions and Phrasal Verbs for ESL and English Learners; Phrasal Verbs, English Expressions, Idioms, Slang, Informal and Colloquial Expression: Focus on English Big Book SeriesValutazione: 5 su 5 stelle5/5 (4)
- Intermediate English Dialogues: Speak American English Like a Native Speaker with these Phrases, Idioms, & ExpressionsDa EverandIntermediate English Dialogues: Speak American English Like a Native Speaker with these Phrases, Idioms, & ExpressionsValutazione: 5 su 5 stelle5/5 (6)
- 49 English Conversation Topics: Lessons with Discussion Questions, Writing Prompts, Idioms & VocabularyDa Everand49 English Conversation Topics: Lessons with Discussion Questions, Writing Prompts, Idioms & VocabularyNessuna valutazione finora
- Advanced English Expressions, Idioms, Collocations, Slang, and Phrasal Verbs: Master American English VocabularyDa EverandAdvanced English Expressions, Idioms, Collocations, Slang, and Phrasal Verbs: Master American English VocabularyValutazione: 5 su 5 stelle5/5 (3)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingDa EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingValutazione: 4.5 su 5 stelle4.5/5 (21)
- Mental Math Secrets - How To Be a Human CalculatorDa EverandMental Math Secrets - How To Be a Human CalculatorValutazione: 5 su 5 stelle5/5 (3)
- 67 ESL Conversation Topics with Questions, Vocabulary, Writing Prompts & More: For Teenagers and AdultsDa Everand67 ESL Conversation Topics with Questions, Vocabulary, Writing Prompts & More: For Teenagers and AdultsValutazione: 4.5 su 5 stelle4.5/5 (6)
- ESL Reading Activities For Kids (6-13): Practical Ideas for the ClassroomDa EverandESL Reading Activities For Kids (6-13): Practical Ideas for the ClassroomValutazione: 5 su 5 stelle5/5 (2)
- English Made Easy Volume One: Learning English through PicturesDa EverandEnglish Made Easy Volume One: Learning English through PicturesValutazione: 4 su 5 stelle4/5 (15)