Potrebbero piacerti anche
- JIU Term-Document MatrixDocumento6 pagineJIU Term-Document MatrixjewarNessuna valutazione finora
- Semantic Syntactic Doc ClassifiersDocumento2 pagineSemantic Syntactic Doc Classifiersmusic2850Nessuna valutazione finora
- Latent Semantic Analysis For Information Retrieval: Khyati Pawde, Niharika Purbey, Shreya Gangan, Lakshmi KurupDocumento4 pagineLatent Semantic Analysis For Information Retrieval: Khyati Pawde, Niharika Purbey, Shreya Gangan, Lakshmi KuruperpublicationNessuna valutazione finora
- Using Semantic Perimeters With Ontologies To Evaluate The Semantic Similarity of Scientific PapersDocumento27 pagineUsing Semantic Perimeters With Ontologies To Evaluate The Semantic Similarity of Scientific PapersYamine KliouiNessuna valutazione finora
- A New Hierarchical Document Clustering Method: Gang Kou Yi PengDocumento4 pagineA New Hierarchical Document Clustering Method: Gang Kou Yi PengRam KumarNessuna valutazione finora
- Can Vector Space Bases Model Context?: Abstract Current Information Retrieval Models Do Not Directly Incorporate ConDocumento11 pagineCan Vector Space Bases Model Context?: Abstract Current Information Retrieval Models Do Not Directly Incorporate ConParagNessuna valutazione finora
- Paper 10Documento5 paginePaper 10Unknown UnknownNessuna valutazione finora
- Personalized Information Retrieval SysteDocumento6 paginePersonalized Information Retrieval Systenofearknight625Nessuna valutazione finora
- Pattern Recognition: Caiyan Jia, Matthew B. Carson, Xiaoyang Wang, Jian YuDocumento13 paginePattern Recognition: Caiyan Jia, Matthew B. Carson, Xiaoyang Wang, Jian YuAbhik NaskarNessuna valutazione finora
- Deng Et Al. - 2019 - Feature Selection For Text Classification A ReviewDocumento20 pagineDeng Et Al. - 2019 - Feature Selection For Text Classification A ReviewGHDaruNessuna valutazione finora
- A Method For Visualising Possible ContextsDocumento8 pagineA Method For Visualising Possible ContextsshigekiNessuna valutazione finora
- Significance of Similarity Measures in Textual Knowledge MiningDocumento3 pagineSignificance of Similarity Measures in Textual Knowledge MiningIIR indiaNessuna valutazione finora
- Wang 2008Documento8 pagineWang 2008ariyan.hossain2208Nessuna valutazione finora
- A Semantic Ontology-Based Document Organizer To Cluster Elearning DocumentsDocumento7 pagineA Semantic Ontology-Based Document Organizer To Cluster Elearning DocumentsCarlos ColettoNessuna valutazione finora
- The Peculiarities of The Text Document Representation, Using Ontology and Tagging-Based Clustering TechniqueDocumento4 pagineThe Peculiarities of The Text Document Representation, Using Ontology and Tagging-Based Clustering TechniqueКонстантин МихайловNessuna valutazione finora
- Survey On Clustering Algorithms For Sentence Level TextDocumento6 pagineSurvey On Clustering Algorithms For Sentence Level TextseventhsensegroupNessuna valutazione finora
- Acm Iconiaac 2014Documento8 pagineAcm Iconiaac 2014veningstonNessuna valutazione finora
- Document Clustering Based On Correlation Preserving IndexingDocumento5 pagineDocument Clustering Based On Correlation Preserving Indexingrocking rakeshNessuna valutazione finora
- Document Clustering Method Based On Visual FeaturesDocumento5 pagineDocument Clustering Method Based On Visual FeaturesrajanNessuna valutazione finora
- K-Means Document Clustering Using Vector Space ModelDocumento5 pagineK-Means Document Clustering Using Vector Space ModelBONFRINGNessuna valutazione finora
- 1 s2.0 S0169023X1730561X MainDocumento17 pagine1 s2.0 S0169023X1730561X Main范红杰Nessuna valutazione finora
- Vector Space Model: An Information Retrieval System: Information Technology Empowering Digital IndiaDocumento3 pagineVector Space Model: An Information Retrieval System: Information Technology Empowering Digital IndiaMayur ShindeNessuna valutazione finora
- 2017 Computing Semantic Similarity of Concepts in Knowledge GraphsDocumento14 pagine2017 Computing Semantic Similarity of Concepts in Knowledge GraphsFAIZ RACHIDNessuna valutazione finora
- Keyword 2Documento5 pagineKeyword 2202002025.jayeshsvmNessuna valutazione finora
- Beyond 512 Tokens: Siamese Multi-Depth Transformer-Based Hierarchical Encoder For Long-Form Document MatchingDocumento10 pagineBeyond 512 Tokens: Siamese Multi-Depth Transformer-Based Hierarchical Encoder For Long-Form Document MatchingJohn PhamvanNessuna valutazione finora
- Similarity-Based Techniques For Text Document ClassificationDocumento8 pagineSimilarity-Based Techniques For Text Document ClassificationijaertNessuna valutazione finora
- Clustering of Bio Medical Scientific PapersDocumento5 pagineClustering of Bio Medical Scientific PapersCaN EroLNessuna valutazione finora
- Document Clustering Using Particle Swarm OptimizationDocumento7 pagineDocument Clustering Using Particle Swarm OptimizationRishi Sharma .Nessuna valutazione finora
- Correlated Topic Models: David M. Blei John D. LaffertyDocumento8 pagineCorrelated Topic Models: David M. Blei John D. Laffertyandrea ramirezNessuna valutazione finora
- Alsmadi-Hoon2019 Article TermWeightingSchemeForShort-te PDFDocumento13 pagineAlsmadi-Hoon2019 Article TermWeightingSchemeForShort-te PDFmurari kumarNessuna valutazione finora
- A Study On Document Classification Using Machine Learning TechniquesDocumento6 pagineA Study On Document Classification Using Machine Learning TechniquesrohitNessuna valutazione finora
- A Study On Document Classification Using Machine Learning TechniquesDocumento6 pagineA Study On Document Classification Using Machine Learning TechniquesrohitNessuna valutazione finora
- NLP Mod-V Q - A (Uploaded by Snaptricks - In)Documento7 pagineNLP Mod-V Q - A (Uploaded by Snaptricks - In)sharan rajNessuna valutazione finora
- Comparing The Performance of SOM With Traditional Methods For Document Clustering Using Wordnet OntologiesDocumento9 pagineComparing The Performance of SOM With Traditional Methods For Document Clustering Using Wordnet OntologiesIJRASETPublicationsNessuna valutazione finora
- 5 - Chen & Fu, 2018Documento4 pagine5 - Chen & Fu, 2018Abu MansyurNessuna valutazione finora
- Text_Classification_Using_Machine_Learning_TechniqDocumento10 pagineText_Classification_Using_Machine_Learning_Techniqgirasebhupendra317Nessuna valutazione finora
- Learning Context For Text CategorizationDocumento9 pagineLearning Context For Text CategorizationLewis TorresNessuna valutazione finora
- Sentence Similarity Based On Semantic NetworksDocumento36 pagineSentence Similarity Based On Semantic NetworksNBA-Comps PlacementsNessuna valutazione finora
- Dynamic - Neural - Networks - For - Text - ClassificationDocumento6 pagineDynamic - Neural - Networks - For - Text - ClassificationDuarte Harris CruzNessuna valutazione finora
- Document Processing: Methods For Semantic Text Similarity AnalysisDocumento6 pagineDocument Processing: Methods For Semantic Text Similarity AnalysisAditya JikamadeNessuna valutazione finora
- Effective Attention Modeling For Neural Relation ExtractionDocumento10 pagineEffective Attention Modeling For Neural Relation ExtractionskandamsNessuna valutazione finora
- A Survey On Text Categorization: International Journal of Computer Trends and Technology-volume3Issue1 - 2012Documento7 pagineA Survey On Text Categorization: International Journal of Computer Trends and Technology-volume3Issue1 - 2012surendiran123Nessuna valutazione finora
- MVS Clustering of Sparse and High Dimensional DataDocumento5 pagineMVS Clustering of Sparse and High Dimensional DataInternational Journal of Application or Innovation in Engineering & ManagementNessuna valutazione finora
- Semantic Text Similarity Using Corpus-Based Word SDocumento26 pagineSemantic Text Similarity Using Corpus-Based Word SGetnete degemuNessuna valutazione finora
- Semi-Structured Documents Mining - A Review and ComparisonDocumento10 pagineSemi-Structured Documents Mining - A Review and ComparisonThales LeviNessuna valutazione finora
- Text Similarity in Vector Space Models: A Comparative StudyDocumento17 pagineText Similarity in Vector Space Models: A Comparative Studyjacobo blanzacoNessuna valutazione finora
- Context Based Document Indexing and Retrieval Using Big Data Analytics - A ReviewDocumento3 pagineContext Based Document Indexing and Retrieval Using Big Data Analytics - A Reviewrahul sharmaNessuna valutazione finora
- Text similarity techniques reviewDocumento6 pagineText similarity techniques reviewMariam WaheedNessuna valutazione finora
- Learning To Rank Short TextDocumento10 pagineLearning To Rank Short TextAlba AlbaNessuna valutazione finora
- Comparative Study On Graph-Based Information Retrieval: The Case of XML DocumentDocumento6 pagineComparative Study On Graph-Based Information Retrieval: The Case of XML DocumentKomal sharmaNessuna valutazione finora
- Nonhierarchical Document Clustering Based On A Tolerance Rough Set ModelDocumento14 pagineNonhierarchical Document Clustering Based On A Tolerance Rough Set ModelDat NguyenNessuna valutazione finora
- Graph Based Representation and Analysis of Text Document: A Survey of TechniquesDocumento8 pagineGraph Based Representation and Analysis of Text Document: A Survey of Techniquesreshma mohanNessuna valutazione finora
- Word Cloud Explorer Text Analytics Based On Word CloudsDocumento10 pagineWord Cloud Explorer Text Analytics Based On Word CloudsCheryl AdaraNessuna valutazione finora
- A Comparative Analysis of Temporal Long Text Similarity: Application To Financial DocumentsDocumento15 pagineA Comparative Analysis of Temporal Long Text Similarity: Application To Financial Documentsmjzaki3379Nessuna valutazione finora
- TF Idf Vs Lsi Vs Multi-Words PDFDocumento8 pagineTF Idf Vs Lsi Vs Multi-Words PDFSaiAshirwadNessuna valutazione finora
- Stop WordsDocumento6 pagineStop WordsANDRES DAVID MESTIZO VALENCIANessuna valutazione finora
- Term WeightingDocumento71 pagineTerm Weightingdawit wolduNessuna valutazione finora
- Distributed Computer Systems: Theory and PracticeDa EverandDistributed Computer Systems: Theory and PracticeValutazione: 4 su 5 stelle4/5 (1)
- UntitledDocumento3 pagineUntitledUno de MadridNessuna valutazione finora
- On The Principles of Parsimony and Self-Consistency For The Emergence of IntelligenceDocumento23 pagineOn The Principles of Parsimony and Self-Consistency For The Emergence of IntelligenceUno de MadridNessuna valutazione finora
- J.S. Bach: The Well Tempered Clavier Remarks On Some of ItDocumento33 pagineJ.S. Bach: The Well Tempered Clavier Remarks On Some of ItUno de MadridNessuna valutazione finora
- What I say-RayCharles 0Documento4 pagineWhat I say-RayCharles 0Uno de MadridNessuna valutazione finora
- Stereo Integrated Amplifier: GB F D E I P SDocumento56 pagineStereo Integrated Amplifier: GB F D E I P SUno de MadridNessuna valutazione finora
- What I say-RayCharles - 1Documento6 pagineWhat I say-RayCharles - 1Uno de MadridNessuna valutazione finora
- The Comprehensive Julia Tutorial - 1 - Intro : Ver Más Ta Compartir 1/9Documento1 paginaThe Comprehensive Julia Tutorial - 1 - Intro : Ver Más Ta Compartir 1/9Uno de MadridNessuna valutazione finora
- BstractDocumento12 pagineBstractUno de MadridNessuna valutazione finora
- Safari - 21 Feb 2021 21:28Documento1 paginaSafari - 21 Feb 2021 21:28Uno de MadridNessuna valutazione finora
- The Well-Tempered Clavier: Composition HistoryDocumento1 paginaThe Well-Tempered Clavier: Composition HistoryUno de MadridNessuna valutazione finora
- Writing essays: A step-by-step guideDocumento18 pagineWriting essays: A step-by-step guideconiNessuna valutazione finora
- R SchemeDocumento1 paginaR SchemeUno de MadridNessuna valutazione finora
- Signed Sealed DeliveredbDocumento1 paginaSigned Sealed DeliveredbUno de MadridNessuna valutazione finora
- What I say-RayCharlesDocumento5 pagineWhat I say-RayCharlesUno de MadridNessuna valutazione finora
- Combining Entropy Measures For Anomaly DetectionDocumento14 pagineCombining Entropy Measures For Anomaly DetectionUno de MadridNessuna valutazione finora
- Schmelzer Ciaccona in A Major - FluteDocumento3 pagineSchmelzer Ciaccona in A Major - FluteUno de MadridNessuna valutazione finora
- J. S. Bach's Great Eighteen Organ Chorales - Russell StinsonDocumento186 pagineJ. S. Bach's Great Eighteen Organ Chorales - Russell StinsonAlexandre Muratori Gonçalves100% (2)
- Schmelzer-Ciaccona-In-A-Major PartituraDocumento4 pagineSchmelzer-Ciaccona-In-A-Major PartituraUno de MadridNessuna valutazione finora
- 1210 2354Documento16 pagine1210 2354Uno de MadridNessuna valutazione finora
- Poincare EmbeddingsDocumento10 paginePoincare EmbeddingsUno de MadridNessuna valutazione finora
- Lab 19 - Network AnalysisDocumento36 pagineLab 19 - Network AnalysisUno de MadridNessuna valutazione finora
- New Svms and Kernels PDFDocumento76 pagineNew Svms and Kernels PDFUno de MadridNessuna valutazione finora
- Signed Sealed DeliveredDocumento3 pagineSigned Sealed DeliveredUno de Madrid78% (9)
- Ain't No Mountain - Piano2Documento2 pagineAin't No Mountain - Piano2Uno de MadridNessuna valutazione finora
- Regression I: Simple Regression: Class 21Documento54 pagineRegression I: Simple Regression: Class 21Uno de MadridNessuna valutazione finora
- Lab 18 - Time Series Anomaly DetectionDocumento37 pagineLab 18 - Time Series Anomaly DetectionUno de MadridNessuna valutazione finora
- P P R G M L: Geomstats A Ython Ackage For Iemannian Eometry in Achine EarningDocumento11 pagineP P R G M L: Geomstats A Ython Ackage For Iemannian Eometry in Achine EarningUno de MadridNessuna valutazione finora
- Bi PlotsDocumento37 pagineBi Plotsaha29Nessuna valutazione finora
- Reynold's Number Flow ExperimentDocumento8 pagineReynold's Number Flow ExperimentPatrick GatelaNessuna valutazione finora
- Sample Feedback IELTS Academic Task 1 Band 6 Double GraphDocumento3 pagineSample Feedback IELTS Academic Task 1 Band 6 Double GraphalinaemmeaNessuna valutazione finora
- Library Management System (Final)Documento88 pagineLibrary Management System (Final)Ariunbat Togtohjargal90% (30)
- Brightline Guiding PrinciplesDocumento16 pagineBrightline Guiding PrinciplesdjozinNessuna valutazione finora
- Lea 201 Coverage Topics in Midterm ExamDocumento40 pagineLea 201 Coverage Topics in Midterm Examshielladelarosa26Nessuna valutazione finora
- User-Centered Website Development: A Human-Computer Interaction ApproachDocumento24 pagineUser-Centered Website Development: A Human-Computer Interaction ApproachKulis KreuznachNessuna valutazione finora
- Accident Causation Theories and ConceptDocumento4 pagineAccident Causation Theories and ConceptShayne Aira AnggongNessuna valutazione finora
- Superior University: 5Mwp Solar Power Plant ProjectDocumento3 pagineSuperior University: 5Mwp Solar Power Plant ProjectdaniyalNessuna valutazione finora
- SEEPZ Special Economic ZoneDocumento2 pagineSEEPZ Special Economic ZonetarachandmaraNessuna valutazione finora
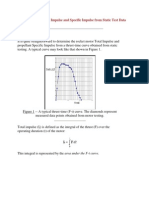
- Determining Total Impulse and Specific Impulse From Static Test DataDocumento4 pagineDetermining Total Impulse and Specific Impulse From Static Test Datajai_selvaNessuna valutazione finora
- Literature Review 5Documento4 pagineLiterature Review 5api-463653994Nessuna valutazione finora
- Lead Magnet 43 Foolproof Strategies To Get More Leads, Win A Ton of New Customers and Double Your Profits in Record Time... (RDocumento189 pagineLead Magnet 43 Foolproof Strategies To Get More Leads, Win A Ton of New Customers and Double Your Profits in Record Time... (RluizdasilvaazevedoNessuna valutazione finora
- Draft of The English Literature ProjectDocumento9 pagineDraft of The English Literature ProjectHarshika Verma100% (1)
- HSPA+ Compressed ModeDocumento10 pagineHSPA+ Compressed ModeAkhtar KhanNessuna valutazione finora
- E200P Operation ManualDocumento26 pagineE200P Operation ManualsharmasourabhNessuna valutazione finora
- Guardplc Certified Function Blocks - Basic Suite: Catalog Number 1753-CfbbasicDocumento110 pagineGuardplc Certified Function Blocks - Basic Suite: Catalog Number 1753-CfbbasicTarun BharadwajNessuna valutazione finora
- CaseHistoriesOnTheApplication of Vacuum PreloadingDocumento25 pagineCaseHistoriesOnTheApplication of Vacuum PreloadingvaishnaviNessuna valutazione finora
- UPGRADEDocumento2 pagineUPGRADEVedansh OswalNessuna valutazione finora
- Green Solvents For Chemistry - William M NelsonDocumento401 pagineGreen Solvents For Chemistry - William M NelsonPhuong Tran100% (4)
- Survey Analyzes India's Toll Collection SystemsDocumento15 pagineSurvey Analyzes India's Toll Collection SystemsmohitvermakspNessuna valutazione finora
- BCM Risk Management and Compliance Training in JakartaDocumento2 pagineBCM Risk Management and Compliance Training in Jakartaindra gNessuna valutazione finora
- cp2021 Inf03p02Documento242 paginecp2021 Inf03p02bahbaguruNessuna valutazione finora
- RoboticsDocumento2 pagineRoboticsCharice AlfaroNessuna valutazione finora
- Exercise No. 7: AIM: To Prepare STATE CHART DIAGRAM For Weather Forecasting System. Requirements: Hardware InterfacesDocumento4 pagineExercise No. 7: AIM: To Prepare STATE CHART DIAGRAM For Weather Forecasting System. Requirements: Hardware InterfacesPriyanshu SinghalNessuna valutazione finora
- Nucleic Acid Isolation System: MolecularDocumento6 pagineNucleic Acid Isolation System: MolecularWarung Sehat Sukahati100% (1)
- Product Catalog: Ductless Mini-Splits, Light Commercial and Multi-Zone SystemsDocumento72 pagineProduct Catalog: Ductless Mini-Splits, Light Commercial and Multi-Zone SystemsFernando ChaddadNessuna valutazione finora
- Fact Sheet Rocket StovesDocumento2 pagineFact Sheet Rocket StovesMorana100% (1)
- Sample Contract Rates MerchantDocumento2 pagineSample Contract Rates MerchantAlan BimantaraNessuna valutazione finora
- Leyte Geothermal v. PNOCDocumento3 pagineLeyte Geothermal v. PNOCAllen Windel BernabeNessuna valutazione finora
- Iqvia PDFDocumento1 paginaIqvia PDFSaksham DabasNessuna valutazione finora