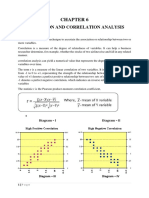
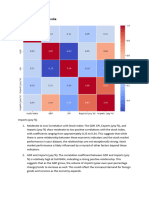
Potrebbero piacerti anche
- Chapter 4: Data AnalysisDocumento11 pagineChapter 4: Data AnalysissaadNessuna valutazione finora
- Interpratation of Regression 2Documento3 pagineInterpratation of Regression 2Adil HassanNessuna valutazione finora
- MBA BA03ergergrergDocumento5 pagineMBA BA03ergergrergsivaNessuna valutazione finora
- Impact of Dividend PolicyDocumento12 pagineImpact of Dividend Policyyashaswisharma68Nessuna valutazione finora
- Topic 3 (2012-13A) MP1Documento78 pagineTopic 3 (2012-13A) MP1Jessica Adharana KurniaNessuna valutazione finora
- Sample Econometrics Research PaperDocumento14 pagineSample Econometrics Research PaperAnuska JayswalNessuna valutazione finora
- Correlation and Regression: Explaining Association and CausationDocumento23 pagineCorrelation and Regression: Explaining Association and CausationParth Rajesh ShethNessuna valutazione finora
- Math 533 Course Project A2Documento7 pagineMath 533 Course Project A2Megan W.Nessuna valutazione finora
- Cigarettes CaseDocumento7 pagineCigarettes CaseSahil NayarNessuna valutazione finora
- Analysis of Manufacturing and Processing CompanyDocumento18 pagineAnalysis of Manufacturing and Processing Companyशिशिर ढकालNessuna valutazione finora
- SPSS ProjectDocumento12 pagineSPSS ProjectRishabh Sethi0% (1)
- Dan Gode-Affect CocDocumento32 pagineDan Gode-Affect CocShanti PertiwiNessuna valutazione finora
- Dizzle 4Documento8 pagineDizzle 4ezioliseNessuna valutazione finora
- Bdmr8043 Cheah Teong KeatDocumento11 pagineBdmr8043 Cheah Teong KeatTeong Keat CheahNessuna valutazione finora
- RegressionDocumento48 pagineRegressionIoana CorinaNessuna valutazione finora
- Relationship Between Inflation and UnemploymentDocumento29 pagineRelationship Between Inflation and Unemploymentnits0007Nessuna valutazione finora
- Granger Causality TestDocumento2 pagineGranger Causality Testimot2Nessuna valutazione finora
- Topic 6 Data Science HandoutDocumento19 pagineTopic 6 Data Science Handoutmeibrahim10Nessuna valutazione finora
- Finance Risk Analytics - Priyanka Sharma - Business ReportDocumento49 pagineFinance Risk Analytics - Priyanka Sharma - Business ReportPriyanka SharmaNessuna valutazione finora
- Business Stat CHAPTER 6Documento5 pagineBusiness Stat CHAPTER 6Natnael AsfawNessuna valutazione finora
- Aishat Acct Chapter FourDocumento8 pagineAishat Acct Chapter Foursadiqmedical160Nessuna valutazione finora
- HW 5, 448Documento16 pagineHW 5, 448pdrogos02100% (1)
- Multiple Regression by AreebaDocumento5 pagineMultiple Regression by AreebaAreeba RaoNessuna valutazione finora
- Correct FypDocumento22 pagineCorrect FypAbeha ChNessuna valutazione finora
- Econometrics Assignment Regression: Does Capital Structure Affects Firm's Performance?Documento3 pagineEconometrics Assignment Regression: Does Capital Structure Affects Firm's Performance?tanishq kansalNessuna valutazione finora
- Data AnalysisDocumento28 pagineData AnalysisDotRev Ibs100% (1)
- Impact of Subsidies and Other Transfers On Poverty and Crop ProductionDocumento7 pagineImpact of Subsidies and Other Transfers On Poverty and Crop ProductionAfrin TonniNessuna valutazione finora
- Interpretation of Eviews RegressionDocumento6 pagineInterpretation of Eviews RegressionRabia Nawaz100% (1)
- Econometrics ExerciseDocumento15 pagineEconometrics ExerciseLetitia VarneyNessuna valutazione finora
- Chapter 10 Regression SlidesDocumento46 pagineChapter 10 Regression SlidesAbhishek KumarNessuna valutazione finora
- Regression AnalysisDocumento21 pagineRegression AnalysisAshish BaniwalNessuna valutazione finora
- Mscfe CRT m2Documento6 pagineMscfe CRT m2Manit Ahlawat100% (1)
- 14 Chapter 5Documento43 pagine14 Chapter 5Neetu KumariNessuna valutazione finora
- Econometrics Analysis Group AssignmentDocumento13 pagineEconometrics Analysis Group AssignmentAaaqil PatelNessuna valutazione finora
- Regression Analysis Can Be Defined As The Process of Developing A MathematicalDocumento21 pagineRegression Analysis Can Be Defined As The Process of Developing A MathematicalAmir Firdaus100% (1)
- North South University: Course: BUS 173 Sec: 06Documento9 pagineNorth South University: Course: BUS 173 Sec: 06Alizay NishatNessuna valutazione finora
- MLR Output Interpretation - W - O - DummyDocumento6 pagineMLR Output Interpretation - W - O - DummyVaibhav AhujaNessuna valutazione finora
- Statistics SPSS ProjectDocumento12 pagineStatistics SPSS Projectrishabhsethi1990Nessuna valutazione finora
- Chapter 14 An Introduction To Multiple Linear Regression: No. of Emails % Discount Sales Customer X X yDocumento9 pagineChapter 14 An Introduction To Multiple Linear Regression: No. of Emails % Discount Sales Customer X X yJayzie LiNessuna valutazione finora
- AJ Department StoreDocumento6 pagineAJ Department StoresoftstixNessuna valutazione finora
- Empirical Results & Discussion:: Table 1: Descriptive StatisticsDocumento5 pagineEmpirical Results & Discussion:: Table 1: Descriptive Statisticssyeda uzmaNessuna valutazione finora
- CF Chapter 11 Excel Master StudentDocumento40 pagineCF Chapter 11 Excel Master Studentjulita08Nessuna valutazione finora
- Capstone ReportDocumento9 pagineCapstone ReportRohit DashNessuna valutazione finora
- What Is Linear RegressionDocumento3 pagineWhat Is Linear Regressionthepirate 52Nessuna valutazione finora
- Chapter-5 Analysis of Results and DiscussionDocumento72 pagineChapter-5 Analysis of Results and Discussionlibison1Nessuna valutazione finora
- Risk Adjusted PerformanceDocumento23 pagineRisk Adjusted PerformanceIrfan U ShahNessuna valutazione finora
- Economic Instructor ManualDocumento30 pagineEconomic Instructor Manualclbrack100% (2)
- Logit RegressionDocumento17 pagineLogit Regressionsmazadamha sulaimanNessuna valutazione finora
- NishaDocumento10 pagineNishaNishanthini SankaranNessuna valutazione finora
- Chapter 14Documento16 pagineChapter 14Dr Bhadrappa HaralayyaNessuna valutazione finora
- Regression Analysis: Interpretation of Regression ModelDocumento22 pagineRegression Analysis: Interpretation of Regression ModelRadith ShakindaNessuna valutazione finora
- Mock Exam Solution Empirical Methods For FinanceDocumento6 pagineMock Exam Solution Empirical Methods For FinanceVilhelm CarlssonNessuna valutazione finora
- FINAL QT PROJECT v1.1Documento8 pagineFINAL QT PROJECT v1.1Harsh DuaNessuna valutazione finora
- Score: Analysing Potential Bankruptcy Threat Using Altman Z-Score: Study of Randomly Selected Borrowers From Psu BanksDocumento8 pagineScore: Analysing Potential Bankruptcy Threat Using Altman Z-Score: Study of Randomly Selected Borrowers From Psu BanksHarsh DuaNessuna valutazione finora
- 4044 4589 1 SMDocumento5 pagine4044 4589 1 SMArzu ZeynalovNessuna valutazione finora
- Data Case Analysis: Ly Anh Tuan-S3818425Documento7 pagineData Case Analysis: Ly Anh Tuan-S3818425tuan lyNessuna valutazione finora
- Minitab Tip Sheet 15Documento5 pagineMinitab Tip Sheet 15ixberisNessuna valutazione finora
- Financial Economics Assignment 1Documento20 pagineFinancial Economics Assignment 1Diana CarilloNessuna valutazione finora
- Ipsos Loyalty MulticollinearityDocumento12 pagineIpsos Loyalty MulticollinearityHashmat حشمت روحیانNessuna valutazione finora
- Method of Data CollectionDocumento1 paginaMethod of Data CollectionAddisu TsegayeNessuna valutazione finora
- This Chapter Will Provide The Readers With An Explanation of The Theoretical Rational About Credit ManagementDocumento2 pagineThis Chapter Will Provide The Readers With An Explanation of The Theoretical Rational About Credit ManagementAddisu TsegayeNessuna valutazione finora
- Supervisory Authority of Bank Credit Risk Management Sound Credit Risk Assessment and Valuation For LoansDocumento1 paginaSupervisory Authority of Bank Credit Risk Management Sound Credit Risk Assessment and Valuation For LoansAddisu TsegayeNessuna valutazione finora
- Research DesignDocumento1 paginaResearch DesignAddisu TsegayeNessuna valutazione finora
- 2.1.1. Research Gap: Employee CompensationDocumento2 pagine2.1.1. Research Gap: Employee CompensationAddisu TsegayeNessuna valutazione finora
- Supervisory Authority of Bank Credit Risk Management Sound Credit Risk Assessment and Valuation For LoansDocumento1 paginaSupervisory Authority of Bank Credit Risk Management Sound Credit Risk Assessment and Valuation For LoansAddisu TsegayeNessuna valutazione finora
- Accounting Is The Process of Recording Financial Transactions Pertaining To A BusinessDocumento1 paginaAccounting Is The Process of Recording Financial Transactions Pertaining To A BusinessAddisu TsegayeNessuna valutazione finora
- Conclusion and Knowledge GapDocumento1 paginaConclusion and Knowledge GapAddisu TsegayeNessuna valutazione finora
- I. Funded Credit Protection A. CollateralDocumento2 pagineI. Funded Credit Protection A. CollateralAddisu TsegayeNessuna valutazione finora
- Credit Risk and Financial DistressDocumento3 pagineCredit Risk and Financial DistressAddisu TsegayeNessuna valutazione finora
- Management Thought Was Developed Due To The Contributions of Many Intellectuals Who Have Different BackgroundDocumento1 paginaManagement Thought Was Developed Due To The Contributions of Many Intellectuals Who Have Different BackgroundAddisu TsegayeNessuna valutazione finora
- Standard Bidding Document Have Three Parts and 9 SectionsDocumento1 paginaStandard Bidding Document Have Three Parts and 9 SectionsAddisu TsegayeNessuna valutazione finora
- Eligible BiddersDocumento3 pagineEligible BiddersAddisu TsegayeNessuna valutazione finora
- Twin Rear Wheels: Dimensions (MM) A Wheel Base 3450 3750 4100 4350 4750Documento2 pagineTwin Rear Wheels: Dimensions (MM) A Wheel Base 3450 3750 4100 4350 4750Addisu TsegayeNessuna valutazione finora
- Johari WindowDocumento28 pagineJohari WindowRajeev ChawlaNessuna valutazione finora
- Departmental Activities Performed Beyond The PlanDocumento1 paginaDepartmental Activities Performed Beyond The PlanAddisu TsegayeNessuna valutazione finora
- Article Review: Strategic Supply Management, Quality Initiatives, and Organizational PerformanceDocumento4 pagineArticle Review: Strategic Supply Management, Quality Initiatives, and Organizational PerformanceAddisu TsegayeNessuna valutazione finora
- Forgetting: Trace Decay Theory of ForgettingDocumento12 pagineForgetting: Trace Decay Theory of ForgettingAddisu TsegayeNessuna valutazione finora
- Yenisehahiwot PDFDocumento97 pagineYenisehahiwot PDFAddisu TsegayeNessuna valutazione finora
- The United Parcel ServiceDocumento1 paginaThe United Parcel ServiceAddisu TsegayeNessuna valutazione finora
- Planned InitiativesDocumento1 paginaPlanned InitiativesAddisu TsegayeNessuna valutazione finora
- Purpose of The ReportDocumento1 paginaPurpose of The ReportAddisu TsegayeNessuna valutazione finora
- Purpose of The ReportDocumento1 paginaPurpose of The ReportAddisu TsegayeNessuna valutazione finora
- Bid Evaluation Report and Recommendation For Award of ContractDocumento11 pagineBid Evaluation Report and Recommendation For Award of ContractAddisu TsegayeNessuna valutazione finora
- Executive SummaryDocumento1 paginaExecutive SummaryAddisu TsegayeNessuna valutazione finora
- Planned InitiativesDocumento1 paginaPlanned InitiativesAddisu TsegayeNessuna valutazione finora
- PDFDocumento159 paginePDFAddisu Tsegaye100% (6)
- Long Term Agreement in ProcurementDocumento24 pagineLong Term Agreement in ProcurementAddisu TsegayeNessuna valutazione finora
- PDFDocumento115 paginePDFAddisu Tsegaye100% (3)
- Bayesian Machine LearningDocumento127 pagineBayesian Machine LearningJohn AlaminaNessuna valutazione finora
- MIT15 097S12 Lec04Documento6 pagineMIT15 097S12 Lec04alokNessuna valutazione finora
- Session 4 Correlation and RegressionDocumento81 pagineSession 4 Correlation and RegressionJecellaEllaServanoNessuna valutazione finora
- GEC05 Module StatisticsDocumento34 pagineGEC05 Module StatisticsAlexs VillafloresNessuna valutazione finora
- Statistik Induktif DasarDocumento17 pagineStatistik Induktif DasarNeneng JuhartiniNessuna valutazione finora
- EstimationDocumento6 pagineEstimationAthulya ManniledamNessuna valutazione finora
- Materials SB: 1+3.3log Log (N)Documento10 pagineMaterials SB: 1+3.3log Log (N)Thu NguyenNessuna valutazione finora
- Assignment # 04 MA2201-Engineering Mathematics IV B.Tech. IV Sem (CSE/IT/CCE)Documento2 pagineAssignment # 04 MA2201-Engineering Mathematics IV B.Tech. IV Sem (CSE/IT/CCE)John WickNessuna valutazione finora
- STAT318 - Data Mining: Dr. Blair RobertsonDocumento39 pagineSTAT318 - Data Mining: Dr. Blair RobertsonCesilyNessuna valutazione finora
- Econometrics Example Questions and SolutionsDocumento5 pagineEconometrics Example Questions and SolutionsAvk11Nessuna valutazione finora
- FEM-TEMPLATE - Workshop 3Documento3 pagineFEM-TEMPLATE - Workshop 3Rojane L. AlcantaraNessuna valutazione finora
- Univariate Time SeriesDocumento83 pagineUnivariate Time SeriesVishnuChaithanyaNessuna valutazione finora
- Question Paper Code:: Reg. No.Documento37 pagineQuestion Paper Code:: Reg. No.Sujith RamNessuna valutazione finora
- Nordpred: Fit Power5 and Poisson Age-Period-Cohort Models For Prediction of Cancer IncidenceDocumento21 pagineNordpred: Fit Power5 and Poisson Age-Period-Cohort Models For Prediction of Cancer IncidenceLeonardo BorgesNessuna valutazione finora
- Neural Correlates of Learning Accommodation and Consolidation in Generalised Anxiety DisorderDocumento8 pagineNeural Correlates of Learning Accommodation and Consolidation in Generalised Anxiety DisorderJ MrNessuna valutazione finora
- Survey PDFDocumento142 pagineSurvey PDFdavid calderonNessuna valutazione finora
- In This PaperDocumento49 pagineIn This Papersazlul02Nessuna valutazione finora
- Trend AnalysisDocumento16 pagineTrend AnalysisNateNessuna valutazione finora
- (FreeCourseWeb - Com) 1493997599Documento386 pagine(FreeCourseWeb - Com) 1493997599MuruganandamGanesanNessuna valutazione finora
- 8 - 29 NotesDocumento2 pagine8 - 29 NotesEthan Shea-StultzNessuna valutazione finora
- Practice of Statistics For Business and Economics 4Th Edition Moore Test Bank Full Chapter PDFDocumento65 paginePractice of Statistics For Business and Economics 4Th Edition Moore Test Bank Full Chapter PDFtintiedraweropw9100% (8)
- DMAIC Cost ReductionDocumento50 pagineDMAIC Cost Reductionrahulkaushikddps365Nessuna valutazione finora
- Research Concept 2Documento8 pagineResearch Concept 2Maryrose TuagiNessuna valutazione finora
- A Cluster Analysis Method For Grouping Means in The Analysis of VarianceDocumento7 pagineA Cluster Analysis Method For Grouping Means in The Analysis of VarianceDudu Mokholo100% (1)
- Chi - Square Test: Dr. Md. NazimDocumento9 pagineChi - Square Test: Dr. Md. Nazimdiksha vermaNessuna valutazione finora
- Linear Regression Hands-OnDocumento27 pagineLinear Regression Hands-OnNishant RandevNessuna valutazione finora
- Bmgt25 - Lec5 - Forecasting Pt. 1Documento55 pagineBmgt25 - Lec5 - Forecasting Pt. 1Ronald ArboledaNessuna valutazione finora
- Stevens 2007 ANCOVA ChapterDocumento35 pagineStevens 2007 ANCOVA ChapterNazia SyedNessuna valutazione finora
- Chow TestDocumento2 pagineChow TestWhitney LeungNessuna valutazione finora
- The War Below: Lithium, Copper, and the Global Battle to Power Our LivesDa EverandThe War Below: Lithium, Copper, and the Global Battle to Power Our LivesValutazione: 4.5 su 5 stelle4.5/5 (8)
- A History of the United States in Five Crashes: Stock Market Meltdowns That Defined a NationDa EverandA History of the United States in Five Crashes: Stock Market Meltdowns That Defined a NationValutazione: 4 su 5 stelle4/5 (11)
- The Infinite Machine: How an Army of Crypto-Hackers Is Building the Next Internet with EthereumDa EverandThe Infinite Machine: How an Army of Crypto-Hackers Is Building the Next Internet with EthereumValutazione: 3 su 5 stelle3/5 (12)
- Narrative Economics: How Stories Go Viral and Drive Major Economic EventsDa EverandNarrative Economics: How Stories Go Viral and Drive Major Economic EventsValutazione: 4.5 su 5 stelle4.5/5 (94)
- The Trillion-Dollar Conspiracy: How the New World Order, Man-Made Diseases, and Zombie Banks Are Destroying AmericaDa EverandThe Trillion-Dollar Conspiracy: How the New World Order, Man-Made Diseases, and Zombie Banks Are Destroying AmericaNessuna valutazione finora
- University of Berkshire Hathaway: 30 Years of Lessons Learned from Warren Buffett & Charlie Munger at the Annual Shareholders MeetingDa EverandUniversity of Berkshire Hathaway: 30 Years of Lessons Learned from Warren Buffett & Charlie Munger at the Annual Shareholders MeetingValutazione: 4.5 su 5 stelle4.5/5 (97)
- The Technology Trap: Capital, Labor, and Power in the Age of AutomationDa EverandThe Technology Trap: Capital, Labor, and Power in the Age of AutomationValutazione: 4.5 su 5 stelle4.5/5 (46)
- Chip War: The Quest to Dominate the World's Most Critical TechnologyDa EverandChip War: The Quest to Dominate the World's Most Critical TechnologyValutazione: 4.5 su 5 stelle4.5/5 (227)
- Doughnut Economics: Seven Ways to Think Like a 21st-Century EconomistDa EverandDoughnut Economics: Seven Ways to Think Like a 21st-Century EconomistValutazione: 4.5 su 5 stelle4.5/5 (37)
- Principles for Dealing with the Changing World Order: Why Nations Succeed or FailDa EverandPrinciples for Dealing with the Changing World Order: Why Nations Succeed or FailValutazione: 4.5 su 5 stelle4.5/5 (237)
- Financial Literacy for All: Disrupting Struggle, Advancing Financial Freedom, and Building a New American Middle ClassDa EverandFinancial Literacy for All: Disrupting Struggle, Advancing Financial Freedom, and Building a New American Middle ClassNessuna valutazione finora
- Look Again: The Power of Noticing What Was Always ThereDa EverandLook Again: The Power of Noticing What Was Always ThereValutazione: 5 su 5 stelle5/5 (3)
- The New Elite: Inside the Minds of the Truly WealthyDa EverandThe New Elite: Inside the Minds of the Truly WealthyValutazione: 4 su 5 stelle4/5 (10)
- The Meth Lunches: Food and Longing in an American CityDa EverandThe Meth Lunches: Food and Longing in an American CityValutazione: 5 su 5 stelle5/5 (5)
- This Changes Everything: Capitalism vs. The ClimateDa EverandThis Changes Everything: Capitalism vs. The ClimateValutazione: 4 su 5 stelle4/5 (349)
- Nudge: The Final Edition: Improving Decisions About Money, Health, And The EnvironmentDa EverandNudge: The Final Edition: Improving Decisions About Money, Health, And The EnvironmentValutazione: 4.5 su 5 stelle4.5/5 (92)
- Deaths of Despair and the Future of CapitalismDa EverandDeaths of Despair and the Future of CapitalismValutazione: 4.5 su 5 stelle4.5/5 (30)
- Economics 101: How the World WorksDa EverandEconomics 101: How the World WorksValutazione: 4.5 su 5 stelle4.5/5 (34)
- Poor Economics: A Radical Rethinking of the Way to Fight Global PovertyDa EverandPoor Economics: A Radical Rethinking of the Way to Fight Global PovertyValutazione: 4.5 su 5 stelle4.5/5 (263)
- Vulture Capitalism: Corporate Crimes, Backdoor Bailouts, and the Death of FreedomDa EverandVulture Capitalism: Corporate Crimes, Backdoor Bailouts, and the Death of FreedomNessuna valutazione finora
- The Myth of the Rational Market: A History of Risk, Reward, and Delusion on Wall StreetDa EverandThe Myth of the Rational Market: A History of Risk, Reward, and Delusion on Wall StreetNessuna valutazione finora
- The Genius of Israel: The Surprising Resilience of a Divided Nation in a Turbulent WorldDa EverandThe Genius of Israel: The Surprising Resilience of a Divided Nation in a Turbulent WorldValutazione: 4 su 5 stelle4/5 (17)