Potrebbero piacerti anche
- Hands-On Azure Data Platform: Building Scalable Enterprise-Grade Relational and Non-Relational database Systems with Azure Data ServicesDa EverandHands-On Azure Data Platform: Building Scalable Enterprise-Grade Relational and Non-Relational database Systems with Azure Data ServicesNessuna valutazione finora
- Understanding Azure Data Factory: Operationalizing Big Data and Advanced Analytics SolutionsDa EverandUnderstanding Azure Data Factory: Operationalizing Big Data and Advanced Analytics SolutionsNessuna valutazione finora
- What Is Azure Data EngineerDocumento74 pagineWhat Is Azure Data EngineerBala Krishna ENessuna valutazione finora
- Azure Data Lake Analytics and U-SQLDocumento17 pagineAzure Data Lake Analytics and U-SQLRahaman AbdulNessuna valutazione finora
- Big Data SE vs. SE of BD SystemsDocumento46 pagineBig Data SE vs. SE of BD SystemsUmm ShahadNessuna valutazione finora
- ABHINAY VARMA PINNAMARAJU - Data EngineeringDocumento6 pagineABHINAY VARMA PINNAMARAJU - Data EngineeringChandra Babu NookalaNessuna valutazione finora
- Jyostna DataEngineer GCEADDocumento5 pagineJyostna DataEngineer GCEADNishant KumarNessuna valutazione finora
- Azure Data FactoryDocumento4 pagineAzure Data FactorysaranajiNessuna valutazione finora
- Valluri Sunitha: Professional SummaryDocumento4 pagineValluri Sunitha: Professional Summarysudhakar reddyNessuna valutazione finora
- The Core Computing Products in Google Cloud Platform IncludeDocumento11 pagineThe Core Computing Products in Google Cloud Platform IncludeSree Charan Mudiya (TCS)Nessuna valutazione finora
- Big Data Tools and TechniquesDocumento12 pagineBig Data Tools and TechniquesNivashNessuna valutazione finora
- SireeshaChalasani DataEngineerDocumento7 pagineSireeshaChalasani DataEngineershanNessuna valutazione finora
- Collaborative ApacheDocumento2 pagineCollaborative ApacheSankalp Sales & Networking Pvt. Ltd.Nessuna valutazione finora
- Naukri Rajasekhar (13y 0m)Documento3 pagineNaukri Rajasekhar (13y 0m)Arup NaskarNessuna valutazione finora
- Azure DatalakeDocumento8 pagineAzure DatalakeRahaman AbdulNessuna valutazione finora
- Syed AhmedDocumento4 pagineSyed Ahmedastitva srivastavaNessuna valutazione finora
- Azure Data Engineer - Samatha GudalaDocumento8 pagineAzure Data Engineer - Samatha GudalaHARSHANessuna valutazione finora
- Srilakshmi ADE ResumeDocumento4 pagineSrilakshmi ADE ResumeSrilakshmi MNessuna valutazione finora
- BDocumento4 pagineBaniruddhaNessuna valutazione finora
- Azure Databricks OverviewDocumento4 pagineAzure Databricks Overviewtsoh100% (1)
- Jagrut Nimmala ResumeDocumento5 pagineJagrut Nimmala ResumeDummy GammyNessuna valutazione finora
- R01 1Documento7 pagineR01 1vitig2Nessuna valutazione finora
- Big Data Analytics - Unit 2Documento10 pagineBig Data Analytics - Unit 2thulasimaninamiNessuna valutazione finora
- Chaitanya - Sr. AWS EngineerDocumento3 pagineChaitanya - Sr. AWS EngineerrecruiterkkNessuna valutazione finora
- Manoj KumarDocumento3 pagineManoj KumarMandeep BakshiNessuna valutazione finora
- DP900 NOTES Parti 1 - 40mn VidéoDocumento11 pagineDP900 NOTES Parti 1 - 40mn VidéoAmir LehmamNessuna valutazione finora
- Name Shivam Prasad Reg No. 15BCE1196Documento8 pagineName Shivam Prasad Reg No. 15BCE1196markNessuna valutazione finora
- Review of Database Management Systems and Their Categories With Use CasesDocumento6 pagineReview of Database Management Systems and Their Categories With Use CasesIJRASETPublicationsNessuna valutazione finora
- BDA Module2-Chapter1Documento21 pagineBDA Module2-Chapter1Lahari bilimaleNessuna valutazione finora
- Data Analytics Unit-3 NotesDocumento21 pagineData Analytics Unit-3 Notes18R11A0530 MUSALE AASHISHNessuna valutazione finora
- Database Design SchemaDocumento13 pagineDatabase Design SchemaCharlee SanchezNessuna valutazione finora
- Machine Learning ServicesDocumento7 pagineMachine Learning ServicesshadiNessuna valutazione finora
- Naukri RaviKumarK (6y 0m)Documento8 pagineNaukri RaviKumarK (6y 0m)Gaurav BhardwajNessuna valutazione finora
- Module 1 Glossary What Is Big DataDocumento2 pagineModule 1 Glossary What Is Big DataHafiszanNessuna valutazione finora
- Unit 2Documento23 pagineUnit 2nosopa5904Nessuna valutazione finora
- Bank MangementDocumento5 pagineBank MangementAlexander MatthewsNessuna valutazione finora
- Naukri BharathPinna (7y 6m)Documento4 pagineNaukri BharathPinna (7y 6m)Arup NaskarNessuna valutazione finora
- Azure Cloud Services: Azure Data Lake StoreDocumento21 pagineAzure Cloud Services: Azure Data Lake StoreParminder Singh KaileyNessuna valutazione finora
- Resume Data EngineerDocumento8 pagineResume Data EngineerMudassir MirzaNessuna valutazione finora
- Big Data PDFDocumento18 pagineBig Data PDFAnushka SinhaNessuna valutazione finora
- Prelims 5Documento7 paginePrelims 5Akshata ChopadeNessuna valutazione finora
- DP900 Full CourseDocumento81 pagineDP900 Full CourseAmir Lehmam100% (1)
- Cheat Sheet DP900Documento7 pagineCheat Sheet DP900Amir LehmamNessuna valutazione finora
- Azure Data FundamentalDocumento81 pagineAzure Data FundamentalKiran YeluruNessuna valutazione finora
- Durgesh Sr. Data Architect / Modeler/BigdataDocumento5 pagineDurgesh Sr. Data Architect / Modeler/BigdataMadhav Garikapati100% (1)
- Saikiran Data - Engineer ResumeDocumento7 pagineSaikiran Data - Engineer Resumeramu_uppadaNessuna valutazione finora
- Tapasvi - Lead GCP Cloud Data EngineerDocumento5 pagineTapasvi - Lead GCP Cloud Data EngineerSri GuruNessuna valutazione finora
- Naukri Vamsi (7y 5m)Documento5 pagineNaukri Vamsi (7y 5m)Arup NaskarNessuna valutazione finora
- CC - Unit - 4Documento2 pagineCC - Unit - 4Faruk MohamedNessuna valutazione finora
- Syed Omer-ResumeDocumento13 pagineSyed Omer-ResumeSanju SinghNessuna valutazione finora
- SSOFTWARES IN DECISION SUPPORT SYSTEMSsDocumento13 pagineSSOFTWARES IN DECISION SUPPORT SYSTEMSsFitha FathimaNessuna valutazione finora
- Fundamentals of Database Systems: (Graph and Browser Databases)Documento18 pagineFundamentals of Database Systems: (Graph and Browser Databases)thecoolguy96Nessuna valutazione finora
- Krishna - Informatica IICS DeveloperDocumento11 pagineKrishna - Informatica IICS DeveloperjavadeveloperumaNessuna valutazione finora
- Cs ProjectDocumento20 pagineCs ProjectAthish J MNessuna valutazione finora
- Module 3Documento6 pagineModule 3Abigail MendezNessuna valutazione finora
- DbmsDocumento44 pagineDbmsvaidehivichareNessuna valutazione finora
- Introduction To DocumentDB A NoSQL JSONDocumento697 pagineIntroduction To DocumentDB A NoSQL JSONAlberto FasceNessuna valutazione finora
- Cloud Bigdata Amand AWSDocumento6 pagineCloud Bigdata Amand AWSshreya arunNessuna valutazione finora
- Resumedata EngineerDocumento3 pagineResumedata EngineerkcmfkgaltNessuna valutazione finora
- Mohit ShivramwarCVDocumento5 pagineMohit ShivramwarCVNoor Ayesha IqbalNessuna valutazione finora
- Frameworks, APIS&Libraries - ExplanationDocumento11 pagineFrameworks, APIS&Libraries - ExplanationPratiksh PatelNessuna valutazione finora
- Algorithm - Writing Lab ReportsDocumento2 pagineAlgorithm - Writing Lab ReportsPratiksh PatelNessuna valutazione finora
- Instructions1 - Uploading New Java Project From Eclipse IDE Onto Github WebsiteDocumento9 pagineInstructions1 - Uploading New Java Project From Eclipse IDE Onto Github WebsitePratiksh PatelNessuna valutazione finora
- 732 Week8 Lecture Slide QuestionsDocumento1 pagina732 Week8 Lecture Slide QuestionsPratiksh PatelNessuna valutazione finora
- Pratiksh Patel's ResumeDocumento2 paginePratiksh Patel's ResumePratiksh PatelNessuna valutazione finora
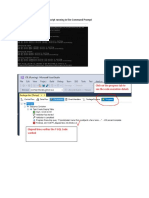
- 1 I Successfully Got The Start Script Running in The Command PromptDocumento1 pagina1 I Successfully Got The Start Script Running in The Command PromptPratiksh PatelNessuna valutazione finora
- Install MS SQL Server Developer EditionDocumento3 pagineInstall MS SQL Server Developer EditionPratiksh PatelNessuna valutazione finora
- Free Learning ResourceDocumento3 pagineFree Learning ResourcePratiksh PatelNessuna valutazione finora
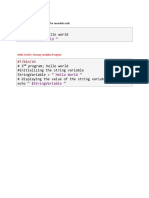
- Data ClearningDocumento1 paginaData ClearningPratiksh PatelNessuna valutazione finora
- Writing A Function: Why Functions Are Better Than ScriptsDocumento1 paginaWriting A Function: Why Functions Are Better Than ScriptsPratiksh PatelNessuna valutazione finora
- Features and Philosophy: Filter Map ReduceDocumento2 pagineFeatures and Philosophy: Filter Map ReducePratiksh PatelNessuna valutazione finora
- Install R (Programming Language) & R Studio (IDE) : 1-Run Button To Execute The Source CodeDocumento1 paginaInstall R (Programming Language) & R Studio (IDE) : 1-Run Button To Execute The Source CodePratiksh PatelNessuna valutazione finora
- Potential Process Failure CausesDocumento1 paginaPotential Process Failure CausesPratiksh PatelNessuna valutazione finora
- Linux ProgrammingDocumento1 paginaLinux ProgrammingPratiksh PatelNessuna valutazione finora
- Smallest Dimension Largest Dimension External Feature of Size Internal Feature of Size Condition Feature of Size Virtual Condition FormulaDocumento2 pagineSmallest Dimension Largest Dimension External Feature of Size Internal Feature of Size Condition Feature of Size Virtual Condition FormulaPratiksh PatelNessuna valutazione finora
- Cost ComparisonDocumento2 pagineCost ComparisonPratiksh PatelNessuna valutazione finora
- Contract Testing With Pact - IoDocumento21 pagineContract Testing With Pact - IoshicabuumNessuna valutazione finora
- GPSRv1.0 - FinalDocumento183 pagineGPSRv1.0 - FinalXavier EtedNessuna valutazione finora
- Computer AssignmentDocumento12 pagineComputer AssignmentPoh Yong WeiNessuna valutazione finora
- Junior Training Sheet V7.0 - READ Row 34 To Make Your Own EDITABLE COPYDocumento159 pagineJunior Training Sheet V7.0 - READ Row 34 To Make Your Own EDITABLE COPYsasasocial3Nessuna valutazione finora
- Project Synopsis For Automatic Timetable GeneratorDocumento5 pagineProject Synopsis For Automatic Timetable GeneratorVikrantManeNessuna valutazione finora
- Computer Networks: by Damera Venkatesh Assistant ProfessorDocumento22 pagineComputer Networks: by Damera Venkatesh Assistant ProfessorTAMMISETTY VIJAY KUMARNessuna valutazione finora
- Perc11 UgDocumento101 paginePerc11 UgDo The DzungNessuna valutazione finora
- The Future of Cryptography Under Quantum Computers: Dartmouth College Computer Science Technical Report TR2002 - 425Documento43 pagineThe Future of Cryptography Under Quantum Computers: Dartmouth College Computer Science Technical Report TR2002 - 425Naveen MithareNessuna valutazione finora
- Sim7020 Series: Simcom Nb-Iot ModuleDocumento3 pagineSim7020 Series: Simcom Nb-Iot ModuleAlejandro DemitiNessuna valutazione finora
- Managing Network SourcesDocumento4 pagineManaging Network Sourcessss pppNessuna valutazione finora
- LAB 1 Crypto Appliqu eDocumento2 pagineLAB 1 Crypto Appliqu eTristan BilotNessuna valutazione finora
- DLD (Assignment 2)Documento12 pagineDLD (Assignment 2)Hamna SajjadNessuna valutazione finora
- Notes On Data Structures and Programming Techniques (CPSC 223, Spring 2018)Documento6 pagineNotes On Data Structures and Programming Techniques (CPSC 223, Spring 2018)Doob StrifeNessuna valutazione finora
- MAJORDocumento24 pagineMAJORC RAHUL RAO.571Nessuna valutazione finora
- Metaplugin ManualDocumento5 pagineMetaplugin ManualandresNessuna valutazione finora
- Picture Compression: EE 545 Dr. David Taggard by Shweta Singh and Eyad SayabalianDocumento9 paginePicture Compression: EE 545 Dr. David Taggard by Shweta Singh and Eyad SayabalianSantoshi SinghNessuna valutazione finora
- Smoke Vs SanityDocumento7 pagineSmoke Vs SanityAmodNessuna valutazione finora
- Flow-X Web-Services - CM - FlowX - Web-ENDocumento31 pagineFlow-X Web-Services - CM - FlowX - Web-ENsindupwNessuna valutazione finora
- Alphavm For Unix User Manual: Date: 28-Feb-2020 Author: Artem Alimarin © 2020, EmuvmDocumento37 pagineAlphavm For Unix User Manual: Date: 28-Feb-2020 Author: Artem Alimarin © 2020, Emuvmabdallah tebibNessuna valutazione finora
- Design and Implementation of A Multiple Agv Scheduling Algorithm For A Job ShopDocumento12 pagineDesign and Implementation of A Multiple Agv Scheduling Algorithm For A Job ShopLord VolragonNessuna valutazione finora
- HP Color LaserJet Managed MFP E78625 E78630 E78635 HP LaserJet Managed MFP E73130 E73135 E73140 Service and Support TrainingDocumento112 pagineHP Color LaserJet Managed MFP E78625 E78630 E78635 HP LaserJet Managed MFP E73130 E73135 E73140 Service and Support TrainingRamcesNessuna valutazione finora
- Computer ProgramsDocumento12 pagineComputer ProgramsMr NoobNessuna valutazione finora
- Rekod TransaksiDocumento6 pagineRekod TransaksiJai KemosabeNessuna valutazione finora
- Memory Layout of C Programs - GeeksforGeeksDocumento5 pagineMemory Layout of C Programs - GeeksforGeeksKrishanu ModakNessuna valutazione finora
- Primepower 200: Midrange ServerDocumento2 paginePrimepower 200: Midrange ServerMariusSibisteanuNessuna valutazione finora
- Cryptography and Network SecurityDocumento55 pagineCryptography and Network SecurityFatima IrfanNessuna valutazione finora
- HLTP Validen20 Ofr Ph1 Nokia 1Documento163 pagineHLTP Validen20 Ofr Ph1 Nokia 1rochdi9991Nessuna valutazione finora
- SAP ODATA V2 Transport and Troubleshooting GuideDocumento37 pagineSAP ODATA V2 Transport and Troubleshooting Guideken761kenNessuna valutazione finora
- Aspirating Smoke Detector Faast Lt-200 EbDocumento2 pagineAspirating Smoke Detector Faast Lt-200 EbAslı AlaçalNessuna valutazione finora