Potrebbero piacerti anche
- A Biologist's Guide to Analysis of DNA Microarray DataDa EverandA Biologist's Guide to Analysis of DNA Microarray DataNessuna valutazione finora
- Norma Hematology Family Brochure ScreenDocumento8 pagineNorma Hematology Family Brochure ScreenamineNessuna valutazione finora
- BM 6010Documento6 pagineBM 6010cydolusNessuna valutazione finora
- Mason - A Read Simulator For Second Generation Sequencing DataDocumento19 pagineMason - A Read Simulator For Second Generation Sequencing DataMin JiaNessuna valutazione finora
- HW4 2023Documento5 pagineHW4 2023writersleedNessuna valutazione finora
- Response 910 Hba1C Results IdentificationDocumento2 pagineResponse 910 Hba1C Results IdentificationDharmesh PatelNessuna valutazione finora
- MSA StudyDocumento15 pagineMSA StudyJAVIERNessuna valutazione finora
- Final Hasnidar - 183145105118Documento5 pagineFinal Hasnidar - 183145105118Husnaeni HusnaNessuna valutazione finora
- Asp 6025Documento8 pagineAsp 6025Chaerul MalikNessuna valutazione finora
- Virtual Steeplechase Exercise Augst 2022 Wacp - MakDocumento16 pagineVirtual Steeplechase Exercise Augst 2022 Wacp - Mak7h6v4jb2mrNessuna valutazione finora
- Illinois Scan ArchitectureDocumento34 pagineIllinois Scan Architectureshri1527Nessuna valutazione finora
- Hasil SPSSDocumento7 pagineHasil SPSSIrfan SaidNessuna valutazione finora
- BX 4000 EbookDocumento6 pagineBX 4000 EbookOo Kenx OoNessuna valutazione finora
- BX 3010 EbookDocumento6 pagineBX 3010 EbookSunand NambiarNessuna valutazione finora
- Manuals TapeStationDocumento6 pagineManuals TapeStationRaquel Ramírez MorenoNessuna valutazione finora
- Round Robin Stda-StdbDocumento17 pagineRound Robin Stda-StdbPlan Entrenamiento GeologiaNessuna valutazione finora
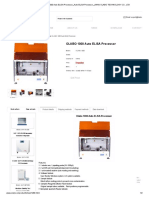
- OLABO 1000 Auto ELISA Processor - Auto ELISA Processor - JINAN OLABO TECHNOLOGY CO., LTDDocumento2 pagineOLABO 1000 Auto ELISA Processor - Auto ELISA Processor - JINAN OLABO TECHNOLOGY CO., LTDomserviceNessuna valutazione finora
- Smart Lite Vet 1A ENGDocumento2 pagineSmart Lite Vet 1A ENGQuốc Tý TrầnNessuna valutazione finora
- ADD-00058823-R1 - ARCHITECT Specifications PDFDocumento6 pagineADD-00058823-R1 - ARCHITECT Specifications PDFMauri SadaniowskiNessuna valutazione finora
- 335 Capability Analysis - BDocumento38 pagine335 Capability Analysis - BAnonymous 7yN43wjlNessuna valutazione finora
- Humacount 5L: Automated Hematology Analyzer - Laser TechnologyDocumento4 pagineHumacount 5L: Automated Hematology Analyzer - Laser TechnologyGarcía XavierNessuna valutazione finora
- Lab3 EnaDocumento11 pagineLab3 EnahamzaNessuna valutazione finora
- Architect: System SpecificationsDocumento6 pagineArchitect: System SpecificationshiwmacrigeeeNessuna valutazione finora
- AFLPDocumento38 pagineAFLPLeandro Silva100% (1)
- Cobas C 311 enDocumento12 pagineCobas C 311 enerikaNessuna valutazione finora
- Ecl 760 Fully Automated Random Access Coagulaon AnalyzerDocumento2 pagineEcl 760 Fully Automated Random Access Coagulaon AnalyzerTrần Văn BìnhNessuna valutazione finora
- Cobas C 311 Brochure Int AgenciesDocumento12 pagineCobas C 311 Brochure Int AgenciesadelNessuna valutazione finora
- Module IV ChecklistDocumento1 paginaModule IV Checklistmahakhadim16Nessuna valutazione finora
- Milos Sfaf 2009Documento54 pagineMilos Sfaf 2009Heloisa PoliseloNessuna valutazione finora
- Speech Recognition ProjectDocumento0 pagineSpeech Recognition ProjectAnand PrajapatiNessuna valutazione finora
- Auto Hematology AnalyzerDocumento2 pagineAuto Hematology Analyzeryalva alvarinoNessuna valutazione finora
- Output 2Documento3 pagineOutput 2itaaaNessuna valutazione finora
- B ATPGDocumento98 pagineB ATPGxinxiang365Nessuna valutazione finora
- Balio Ox-560 Brochure enDocumento4 pagineBalio Ox-560 Brochure enMo AlyNessuna valutazione finora
- Tissue Processor Comparison Spec Sheet V2Documento1 paginaTissue Processor Comparison Spec Sheet V2Ogut AjaNessuna valutazione finora
- Lecture 5Documento18 pagineLecture 5Shivani PatalbansiNessuna valutazione finora
- ADD-00058823-R1 - ARCHITECT Specifications PDFDocumento4 pagineADD-00058823-R1 - ARCHITECT Specifications PDFGita RahvitaNessuna valutazione finora
- Sampling For Biotech Grains: Science. Research. Also, We Thank Thomas Whitaker For Sharing His Draft PaperDocumento8 pagineSampling For Biotech Grains: Science. Research. Also, We Thank Thomas Whitaker For Sharing His Draft PaperMina RemonNessuna valutazione finora
- Balio Ox-580 Brochure en FinalDocumento2 pagineBalio Ox-580 Brochure en Finalphyo waiNessuna valutazione finora
- Calculation AkashDocumento4 pagineCalculation AkashAkash BhowmikNessuna valutazione finora
- Folleto - Epmotion 5075t - Epmotion 5075m - Changing To NGS BaseDocumento4 pagineFolleto - Epmotion 5075t - Epmotion 5075m - Changing To NGS Basepunctt.Nessuna valutazione finora
- DIATRON Abacus 5 LeafletDocumento4 pagineDIATRON Abacus 5 LeafletPopovNessuna valutazione finora
- DIATRON Abacus 5 LeafletDocumento4 pagineDIATRON Abacus 5 LeafletPopovNessuna valutazione finora
- Hasil Analisis HestiDocumento5 pagineHasil Analisis Hestimega watiNessuna valutazione finora
- Stabinger Viscometer:::: Viscometry at Its BestDocumento6 pagineStabinger Viscometer:::: Viscometry at Its BestSupriyo PNessuna valutazione finora
- Uji Univariat YazidDocumento3 pagineUji Univariat Yazidnormalitadwinandia37Nessuna valutazione finora
- Oneway: NotesDocumento5 pagineOneway: Noteswinda wahyuniNessuna valutazione finora
- ExploreDocumento13 pagineExploreVanny PatriciaNessuna valutazione finora
- 2010 - 03 - 2415 - 51 - 00BC-5800 Difference With BC-5500Documento30 pagine2010 - 03 - 2415 - 51 - 00BC-5800 Difference With BC-5500samuel debebeNessuna valutazione finora
- 6 HA-8380V PresentationDocumento19 pagine6 HA-8380V PresentationClient-Products AccountNessuna valutazione finora
- Acl Top Family Brochure - 2.1.2012 - FinalDocumento8 pagineAcl Top Family Brochure - 2.1.2012 - Finalpieterinpretoria391Nessuna valutazione finora
- Analyze The Technique To Detect Multiple Scan Chain Failure: Jhanvi Ravi Sheth, Rahul Mehta, Bhavesh SoniDocumento3 pagineAnalyze The Technique To Detect Multiple Scan Chain Failure: Jhanvi Ravi Sheth, Rahul Mehta, Bhavesh Soniamena fahatNessuna valutazione finora
- 06f A-NormalityTest6507GBMfgv4Documento16 pagine06f A-NormalityTest6507GBMfgv4Tentam RizNessuna valutazione finora
- CA-800 Catalog en SDocumento2 pagineCA-800 Catalog en SOo Kenx OoNessuna valutazione finora
- Application Note Easy Transfer of Your Traditional Western Blot To WesDocumento6 pagineApplication Note Easy Transfer of Your Traditional Western Blot To WesjagaenatorNessuna valutazione finora
- Please Cite This Paper Rather Than This Web Page If You Use The Macro in Research You Are PublishingDocumento3 paginePlease Cite This Paper Rather Than This Web Page If You Use The Macro in Research You Are PublishingVic KeyNessuna valutazione finora
- TALIMAFINALDocumento6 pagineTALIMAFINALRomeo HilisNessuna valutazione finora
- Python For Bioinformatics Cap 4Documento16 paginePython For Bioinformatics Cap 4celialove17Nessuna valutazione finora
- Quality Engineering 06/02/2019 General Recommendations:: Index1 Index2 Index3 Index4Documento15 pagineQuality Engineering 06/02/2019 General Recommendations:: Index1 Index2 Index3 Index4Giuseppe D'AngeloNessuna valutazione finora
- Lecture3 1Documento18 pagineLecture3 1Sneha RudravaramNessuna valutazione finora
- Assignment G2Documento1 paginaAssignment G2Jorge BerumenNessuna valutazione finora
- MIPS Green SheetDocumento2 pagineMIPS Green SheetjasontgameNessuna valutazione finora
- Assignment HDocumento1 paginaAssignment HJorge BerumenNessuna valutazione finora
- Assignment FDocumento1 paginaAssignment FJorge BerumenNessuna valutazione finora
- Assignment A2Documento1 paginaAssignment A2Jorge BerumenNessuna valutazione finora
- Assignment DDocumento1 paginaAssignment DJorge BerumenNessuna valutazione finora
- Lab 5 ReportDocumento4 pagineLab 5 ReportJorge BerumenNessuna valutazione finora
- Lab 3 ReportDocumento2 pagineLab 3 ReportJorge BerumenNessuna valutazione finora
- Lab 6 ReportDocumento4 pagineLab 6 ReportJorge BerumenNessuna valutazione finora
- Lab 2 ReportDocumento3 pagineLab 2 ReportJorge BerumenNessuna valutazione finora
- Lab 1 ReportDocumento4 pagineLab 1 ReportJorge BerumenNessuna valutazione finora
- Class Diagram 1Documento1 paginaClass Diagram 1Jorge BerumenNessuna valutazione finora
- Lab 3Documento2 pagineLab 3Jorge BerumenNessuna valutazione finora
- Final Cheet SheetDocumento2 pagineFinal Cheet SheetJorge BerumenNessuna valutazione finora
- Silverlight Socket Client Source CodeDocumento10 pagineSilverlight Socket Client Source CodeJorge BerumenNessuna valutazione finora
- Lab 2Documento1 paginaLab 2Jorge BerumenNessuna valutazione finora
- Lab 1Documento1 paginaLab 1Jorge BerumenNessuna valutazione finora
- 11 Februn 1Documento2 pagine11 Februn 1soumava palitNessuna valutazione finora
- 2013 BCC SolutionDocumento33 pagine2013 BCC SolutionMaryam RehanNessuna valutazione finora
- Fronting Tomcat With Apache or IIS - Best PracticesDocumento11 pagineFronting Tomcat With Apache or IIS - Best PracticesBan Mai XanhNessuna valutazione finora
- C51 PrimerDocumento194 pagineC51 PrimerD Anand KumarNessuna valutazione finora
- Advia 2120 CD-ROMDocumento6 pagineAdvia 2120 CD-ROMابكر ابو ميلادNessuna valutazione finora
- ODROID Magazine 201402Documento42 pagineODROID Magazine 201402helveciotfNessuna valutazione finora
- 15,16 2 Mark SEQADocumento32 pagine15,16 2 Mark SEQAbhuvi2312Nessuna valutazione finora
- SecureSpan SOA Gateway For Policy GovernanceDocumento2 pagineSecureSpan SOA Gateway For Policy GovernanceLayer7TechNessuna valutazione finora
- LED ButtonDocumento14 pagineLED Buttonlabirint10Nessuna valutazione finora
- WPV 615 Cluster GuideDocumento106 pagineWPV 615 Cluster GuideFernando Rodrigo DriNessuna valutazione finora
- Leostream Data Sheets PDFDocumento2 pagineLeostream Data Sheets PDFAnonymous iTkyPF3Nessuna valutazione finora
- Konica Minolta Bizhub 367 BrochureDocumento4 pagineKonica Minolta Bizhub 367 BrochureAsad Irfan100% (1)
- Pixhawk4 Technical Data Sheet PDFDocumento3 paginePixhawk4 Technical Data Sheet PDFhung dangNessuna valutazione finora
- APDL CommandsDocumento1 paginaAPDL CommandsayalpaniyanNessuna valutazione finora
- SPSADocumento126 pagineSPSAPrateek GuptaNessuna valutazione finora
- Coutloot Mean Stack Developer ChallengeDocumento1 paginaCoutloot Mean Stack Developer ChallengeVinit JainNessuna valutazione finora
- DBA CommandsDocumento414 pagineDBA CommandsArun KumarNessuna valutazione finora
- PI-OPC DA Interface v2.5.1.x Manual-2Documento110 paginePI-OPC DA Interface v2.5.1.x Manual-2MerdekaNessuna valutazione finora
- Tybca SlipsDocumento8 pagineTybca SlipsJobin JosephNessuna valutazione finora
- Finding and Resolving Unconstrained EndpointsDocumento3 pagineFinding and Resolving Unconstrained EndpointsMayur Agarwal100% (5)
- SRSDocumento21 pagineSRSAkshay100% (1)
- ThreadMaster ThreadMaster Monitors Threads and Handle HighDocumento3 pagineThreadMaster ThreadMaster Monitors Threads and Handle Highbrujo_clNessuna valutazione finora
- IPredator - Setting Up OpenVPN On Windows 8 PDFDocumento22 pagineIPredator - Setting Up OpenVPN On Windows 8 PDFCora BlakeNessuna valutazione finora
- JAXBDocumento48 pagineJAXBapi-3750876100% (1)
- Introduction To Static RoutingDocumento25 pagineIntroduction To Static RoutingKashif AmjadNessuna valutazione finora
- Wavelets and Multiresolution: by Dr. Mahua BhattacharyaDocumento39 pagineWavelets and Multiresolution: by Dr. Mahua BhattacharyashubhamNessuna valutazione finora
- Differences Between Abstract Factory Pattern and Factory Method - Stack Overflow PDFDocumento4 pagineDifferences Between Abstract Factory Pattern and Factory Method - Stack Overflow PDFgopi247Nessuna valutazione finora
- Brochure Netwars 2014Documento13 pagineBrochure Netwars 2014x-aceNessuna valutazione finora
- SP3D ModelFormats Global enDocumento7 pagineSP3D ModelFormats Global enJesús Alberto Díaz CostaNessuna valutazione finora
- Windows 7 Platinum Edition File ListDocumento3 pagineWindows 7 Platinum Edition File ListJoshua Partogi0% (1)