Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Trading Services LTD: Bookmap™ MasterclassDocumento9 pagineTrading Services LTD: Bookmap™ MasterclassmohitbguptaNessuna valutazione finora
- Simple Regression QuizDocumento6 pagineSimple Regression QuizKiranmai GogireddyNessuna valutazione finora
- Lecture 4-Quantitative and Qualitative Research MethodologyDocumento13 pagineLecture 4-Quantitative and Qualitative Research MethodologyMaribel Tan-Losloso Nayad0% (1)
- Parts of The Science Investigatory Project Report - Hands-OnDocumento9 pagineParts of The Science Investigatory Project Report - Hands-Onreyandy100% (4)
- Recommended Resources: AppendixDocumento2 pagineRecommended Resources: AppendixmohitbguptaNessuna valutazione finora
- Price Prediction Evolution: From Economic Model To Machine LearningDocumento7 paginePrice Prediction Evolution: From Economic Model To Machine LearningmohitbguptaNessuna valutazione finora
- Individualized Indicator For All: Stock-Wise Technical Indicator Optimization With Stock EmbeddingDocumento9 pagineIndividualized Indicator For All: Stock-Wise Technical Indicator Optimization With Stock EmbeddingmohitbguptaNessuna valutazione finora
- CME Iceberg Order Detection and PredictionDocumento16 pagineCME Iceberg Order Detection and PredictionmohitbguptaNessuna valutazione finora
- Improving S&P Stock Prediction With Time Series Stock SimilarityDocumento14 pagineImproving S&P Stock Prediction With Time Series Stock SimilaritymohitbguptaNessuna valutazione finora
- Dynamic Time Warping Application For Financial Pattern RecognitionDocumento19 pagineDynamic Time Warping Application For Financial Pattern RecognitionmohitbguptaNessuna valutazione finora
- Fraud Ebook Latest - Databricks PDFDocumento14 pagineFraud Ebook Latest - Databricks PDFmohitbguptaNessuna valutazione finora
- Improving Technical Trading Systems by Using A New MATLAB Based Genetic Algorithm ProcedureDocumento6 pagineImproving Technical Trading Systems by Using A New MATLAB Based Genetic Algorithm ProceduremohitbguptaNessuna valutazione finora
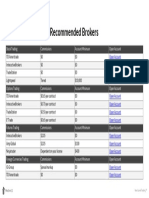
- Recommended Brokers: Stock Trading Commissions Account Minimum Open AccountDocumento1 paginaRecommended Brokers: Stock Trading Commissions Account Minimum Open AccountmohitbguptaNessuna valutazione finora
- SSRN Id3420952Documento53 pagineSSRN Id3420952mohitbguptaNessuna valutazione finora
- Profitable Momentum Trading Strategies For Individual InvestorsDocumento32 pagineProfitable Momentum Trading Strategies For Individual InvestorsmohitbguptaNessuna valutazione finora
- Stockagent: Application of RL From Lunarlander To Stock Price PredictionDocumento5 pagineStockagent: Application of RL From Lunarlander To Stock Price PredictionmohitbguptaNessuna valutazione finora
- Advanced Analysis QuantileRegressionDocumento45 pagineAdvanced Analysis QuantileRegressionmohitbguptaNessuna valutazione finora
- Developed Trading Strategies by Genetic AlgorithmDocumento8 pagineDeveloped Trading Strategies by Genetic AlgorithmmohitbguptaNessuna valutazione finora
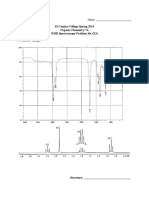
- Chem7a NMR X3Documento13 pagineChem7a NMR X3Annmarie DominguezNessuna valutazione finora
- Marketing in TourismDocumento24 pagineMarketing in TourismYulvina Kusuma PutriNessuna valutazione finora
- Caps 12 Q2 0101 FDDocumento23 pagineCaps 12 Q2 0101 FDGilarie AlisonNessuna valutazione finora
- Biology Homework Helpers PDFDocumento352 pagineBiology Homework Helpers PDFTrúc Hồ100% (1)
- 14 Variable Sampling Plan - StudentDocumento17 pagine14 Variable Sampling Plan - Studentsoonvy100% (1)
- PDF (SG) - EAP 11 - 12 - UNIT 11 - LESSON 3 - Preparing and Administering Data CollectionDocumento15 paginePDF (SG) - EAP 11 - 12 - UNIT 11 - LESSON 3 - Preparing and Administering Data CollectionMira Rochenie CuranNessuna valutazione finora
- Lecture 4 - Principles of Experimental DesignDocumento23 pagineLecture 4 - Principles of Experimental DesignthinagaranNessuna valutazione finora
- Assignment 3Documento3 pagineAssignment 3Trishla GandhiNessuna valutazione finora
- Labmanual For MbaDocumento23 pagineLabmanual For MbarhariharancseNessuna valutazione finora
- Regression Analysis - WikipediaDocumento10 pagineRegression Analysis - WikipediaalejojgNessuna valutazione finora
- Business StatisticsDocumento3 pagineBusiness StatisticsRashida ArshadNessuna valutazione finora
- Dweck & Leggett (1988) A Social-Cognitive ApproachDocumento18 pagineDweck & Leggett (1988) A Social-Cognitive ApproachNicolásAlejandroCortésUaracNessuna valutazione finora
- Topic: ANOVA (Analysis of Variation) : Md. Jiyaul MustafaDocumento49 pagineTopic: ANOVA (Analysis of Variation) : Md. Jiyaul MustafaBhagya PatilNessuna valutazione finora
- The Effects of Mathematics Anxiety On Ac PDFDocumento11 pagineThe Effects of Mathematics Anxiety On Ac PDFMihaela CherejiNessuna valutazione finora
- How To Write A Research ProposalDocumento4 pagineHow To Write A Research ProposalOmer UsmanNessuna valutazione finora
- Analysis of Variance: Testing Equality of Means Across GroupsDocumento7 pagineAnalysis of Variance: Testing Equality of Means Across GroupsMuraliManoharNessuna valutazione finora
- Full Download Research Methods For The Behavioral Sciences 4th Edition Stangor Test BankDocumento35 pagineFull Download Research Methods For The Behavioral Sciences 4th Edition Stangor Test Bankpentorrispro100% (32)
- L09 Measurement Uncertainty in Microbiological Examinations of Foods Technique For Determination of Pathogens - Hilde Skår NorliDocumento20 pagineL09 Measurement Uncertainty in Microbiological Examinations of Foods Technique For Determination of Pathogens - Hilde Skår NorliLe TeoNessuna valutazione finora
- Validation of Pharmaceutical ProcessesDocumento13 pagineValidation of Pharmaceutical ProcessesGULSHAN MADHURNessuna valutazione finora
- Ejercicio de ANOVA CompletoDocumento7 pagineEjercicio de ANOVA CompletoMaximiliano CarrizoNessuna valutazione finora
- Predictive Analytics The Future of Business IntelligenceDocumento8 paginePredictive Analytics The Future of Business Intelligenceapi-26942115100% (3)
- A Short Introduction To The Lindblad Master EquationDocumento28 pagineA Short Introduction To The Lindblad Master EquationOscar Bohórquez100% (1)
- OPRE 6364 Quality Control (Lean Six Sigma) : Six Sigma Measure Data Collection Plan and Gage R&RDocumento18 pagineOPRE 6364 Quality Control (Lean Six Sigma) : Six Sigma Measure Data Collection Plan and Gage R&RGustavo SánchezNessuna valutazione finora
- Individual Project Instructions - 5aDocumento1 paginaIndividual Project Instructions - 5aIkhram JohariNessuna valutazione finora
- Module 3 Ouput - GuidelinesDocumento3 pagineModule 3 Ouput - GuidelinesMartha Nicole MaristelaNessuna valutazione finora
- Educational Technology 1Documento23 pagineEducational Technology 1jepoy swaNessuna valutazione finora
- Anova Lecture Notes 1Documento8 pagineAnova Lecture Notes 1Mian NomiNessuna valutazione finora