Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
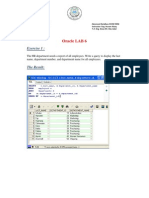
- Oracle Startup and Shutdown PhasesDocumento9 pagineOracle Startup and Shutdown PhasesPILLINAGARAJUNessuna valutazione finora
- Oracle LAB 6 SolutionDocumento7 pagineOracle LAB 6 SolutionMalini SurianarayananNessuna valutazione finora
- Class 1 - E in ERDDocumento33 pagineClass 1 - E in ERDKarthik sivanesanNessuna valutazione finora
- Parallel DBMS VendorsDocumento14 pagineParallel DBMS VendorsJeevanantham GovindarajNessuna valutazione finora
- Ethical Hacking QuizDocumento3 pagineEthical Hacking QuizSushil SharmaNessuna valutazione finora
- Menu Dinamis Framework CI + Template adminLTE + MysqlDocumento2 pagineMenu Dinamis Framework CI + Template adminLTE + MysqlJalem PutroNessuna valutazione finora
- Docu 69874Documento9 pagineDocu 69874pcoffey2240Nessuna valutazione finora
- What Is A Database Management System (Or DBMS) ?: SoftwareDocumento2 pagineWhat Is A Database Management System (Or DBMS) ?: SoftwareMerad HassanNessuna valutazione finora
- Ntfs Cheat Sheets PDFDocumento4 pagineNtfs Cheat Sheets PDFShahadat HossainNessuna valutazione finora
- NB Operation CommandsDocumento4 pagineNB Operation CommandsRajesh YeletiNessuna valutazione finora
- Assignment 1 Practice Example For The ERD and Entity DescriptionDocumento2 pagineAssignment 1 Practice Example For The ERD and Entity DescriptionJayaram Gautam100% (1)
- XII-Informatics Practices SQP 2018-19Documento8 pagineXII-Informatics Practices SQP 2018-19Perfect Guider Madhav AgarwalNessuna valutazione finora
- h15459 WP Powerscale Onefs Storage Efficiency - Pdf.externalDocumento15 pagineh15459 WP Powerscale Onefs Storage Efficiency - Pdf.externalqwrr rewqNessuna valutazione finora
- DBMS SummaryDocumento24 pagineDBMS Summarysupersodi1Nessuna valutazione finora
- Log in CodeDocumento7 pagineLog in CodePhilip CurilanNessuna valutazione finora
- Exercise 2Documento2 pagineExercise 2Hrishikesh ThyagarajanNessuna valutazione finora
- Lab Task by Sahil 031Documento7 pagineLab Task by Sahil 031abdullahNessuna valutazione finora
- Hospital E-Token MGT PRPDocumento16 pagineHospital E-Token MGT PRPMuhammad Bin JabbarNessuna valutazione finora
- W3S SQLDocumento13 pagineW3S SQLHarALevelComputing JNessuna valutazione finora
- Question Text: Correct Mark 1.00 Out of 1.00Documento12 pagineQuestion Text: Correct Mark 1.00 Out of 1.00DominicOrtegaNessuna valutazione finora
- The Emergency Operations of The Solaris For IManager M2000-20090413-B-1.0Documento26 pagineThe Emergency Operations of The Solaris For IManager M2000-20090413-B-1.0akdenizerdemNessuna valutazione finora
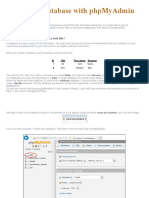
- Create A Database With phpMyAdminDocumento6 pagineCreate A Database With phpMyAdminMunavalli Matt K SNessuna valutazione finora
- PostgreSQL Solaris PKG InstallationDocumento8 paginePostgreSQL Solaris PKG InstallationwasifbukhariNessuna valutazione finora
- Azure Synapse Analytics: Partner WebinarDocumento35 pagineAzure Synapse Analytics: Partner WebinarTirumalesh ReddyNessuna valutazione finora
- Domain Name System: Window Server 2012 R2Documento46 pagineDomain Name System: Window Server 2012 R2Rajat RajputNessuna valutazione finora
- TREEDocumento28 pagineTREEsudhanNessuna valutazione finora
- Visual Basic 6 Client-Server Programming Gold BookDocumento830 pagineVisual Basic 6 Client-Server Programming Gold BookRishiNessuna valutazione finora
- UNIT 4 - Diving Deeper Into The Basics of LaravelDocumento14 pagineUNIT 4 - Diving Deeper Into The Basics of LaravelReynante UrsulumNessuna valutazione finora
- Data Migration For S4HANA-v1.2Documento54 pagineData Migration For S4HANA-v1.2abhi100% (1)
- SQL Crash Course PDFDocumento24 pagineSQL Crash Course PDFArun PanneerNessuna valutazione finora