Potrebbero piacerti anche
- Tute LabDocumento42 pagineTute LabVictorNessuna valutazione finora
- MATLAB for Beginners: A Gentle Approach - Revised EditionDa EverandMATLAB for Beginners: A Gentle Approach - Revised EditionNessuna valutazione finora
- EE 105: MATLAB As An Engineer's Problem Solving ToolDocumento3 pagineEE 105: MATLAB As An Engineer's Problem Solving Toolthinkberry22Nessuna valutazione finora
- CVEN2002 Laboratory ExercisesDocumento41 pagineCVEN2002 Laboratory ExercisesMary DinhNessuna valutazione finora
- Beginning AutoCAD® 2020 Exercise WorkbookDa EverandBeginning AutoCAD® 2020 Exercise WorkbookValutazione: 2.5 su 5 stelle2.5/5 (3)
- Print AbleDocumento14 paginePrint AblevenkyeeeNessuna valutazione finora
- MATLAB for Neuroscientists: An Introduction to Scientific Computing in MATLABDa EverandMATLAB for Neuroscientists: An Introduction to Scientific Computing in MATLABValutazione: 4 su 5 stelle4/5 (1)
- MatlabSession1 PHAS2441Documento5 pagineMatlabSession1 PHAS2441godkid308Nessuna valutazione finora
- Maths For Engineers and Scientists 4: Matlab: 1.1 What Is It?Documento18 pagineMaths For Engineers and Scientists 4: Matlab: 1.1 What Is It?ameerul ahwazNessuna valutazione finora
- Essential MATLAB for Engineers and ScientistsDa EverandEssential MATLAB for Engineers and ScientistsValutazione: 2 su 5 stelle2/5 (2)
- Getting Started With Matlab: 1.1 Starting, Quitting, and Getting HelpDocumento20 pagineGetting Started With Matlab: 1.1 Starting, Quitting, and Getting HelpAhmed N. MusaNessuna valutazione finora
- Advanced Numerical Methods with Matlab 1: Function Approximation and System ResolutionDa EverandAdvanced Numerical Methods with Matlab 1: Function Approximation and System ResolutionNessuna valutazione finora
- Mathematica TutorialDocumento131 pagineMathematica TutorialErdenebaatar KhurelhuuNessuna valutazione finora
- Beginning AutoCAD® 2018: Exercise WorkbookDa EverandBeginning AutoCAD® 2018: Exercise WorkbookValutazione: 1 su 5 stelle1/5 (1)
- Matlabnotes PDFDocumento17 pagineMatlabnotes PDFUmer AbbasNessuna valutazione finora
- Tableau 8.2 Training Manual: From Clutter to ClarityDa EverandTableau 8.2 Training Manual: From Clutter to ClarityNessuna valutazione finora
- Digital Image Processing: Lab Assignements: InstructionsDocumento4 pagineDigital Image Processing: Lab Assignements: InstructionsS. MagidiNessuna valutazione finora
- MATLAB for Beginners: A Gentle Approach - Revised EditionDa EverandMATLAB for Beginners: A Gentle Approach - Revised EditionValutazione: 3.5 su 5 stelle3.5/5 (11)
- Print AbleDocumento12 paginePrint AbleCristian HoreaNessuna valutazione finora
- Learn About Matrices, Arrays, Animations, Graphs, Tables, Simulink, Guis, and Much More. All in One CourseDocumento4 pagineLearn About Matrices, Arrays, Animations, Graphs, Tables, Simulink, Guis, and Much More. All in One CourseAnonymous HhxvQ537xNessuna valutazione finora
- DSP Lab Manual 2023Documento85 pagineDSP Lab Manual 2023tanujsingal945Nessuna valutazione finora
- Introduction To MATLAB: Notes For The Introductory CourseDocumento29 pagineIntroduction To MATLAB: Notes For The Introductory CourseelinerzNessuna valutazione finora
- CFTool TutorialDocumento16 pagineCFTool TutorialvigneshNessuna valutazione finora
- « Introduction to Biomedical Engineering»: СourseDocumento7 pagine« Introduction to Biomedical Engineering»: СourseEbrahim Abd El HadyNessuna valutazione finora
- DIP Lab: Introduction To MATLAB: GoalDocumento7 pagineDIP Lab: Introduction To MATLAB: GoalMohamed El-Mutasim El-FeelNessuna valutazione finora
- Dspaceinsimulink PDFDocumento20 pagineDspaceinsimulink PDFmphaniteja2012Nessuna valutazione finora
- Lab 7Documento5 pagineLab 7Deepak SunkariyaNessuna valutazione finora
- McGraw-Hill - Data Management (Full Textbook Online)Documento664 pagineMcGraw-Hill - Data Management (Full Textbook Online)Varun Shah81% (16)
- Matlab: Historical OverviewDocumento43 pagineMatlab: Historical OverviewDhana JayanNessuna valutazione finora
- Stata DataworkDocumento22 pagineStata Dataworkhasan zahidNessuna valutazione finora
- Matlab Session 1: Practice Problems Which Use These Concepts Can Be Downloaded in PDF FormDocumento21 pagineMatlab Session 1: Practice Problems Which Use These Concepts Can Be Downloaded in PDF FormMac RodgeNessuna valutazione finora
- IB 115 Lab #1: An Introduction To Matlab: You Must Hand in Question 17 and 19 For GradingDocumento9 pagineIB 115 Lab #1: An Introduction To Matlab: You Must Hand in Question 17 and 19 For GradingStacyLiNessuna valutazione finora
- AIML ManualDocumento76 pagineAIML ManualHardik KannadNessuna valutazione finora
- 8.1 Lesson: Raster To Vector Conversion: EightDocumento16 pagine8.1 Lesson: Raster To Vector Conversion: Eightສີສຸວັນ ດວງມະນີNessuna valutazione finora
- Signsls LabDocumento41 pagineSignsls LabAnonymous eWMnRr70q0% (1)
- 01 Matlab Basics1 2019Documento15 pagine01 Matlab Basics1 2019mzt messNessuna valutazione finora
- Matlab-Redes NeuronalesDocumento6 pagineMatlab-Redes NeuronalesRoberto Sanchez ZambranoNessuna valutazione finora
- Tutorial Minitab 15Documento32 pagineTutorial Minitab 15wawan_a_sNessuna valutazione finora
- 250C Lab1Documento6 pagine250C Lab1Vaishalee SinghNessuna valutazione finora
- Fuzzy Labs1and2Documento8 pagineFuzzy Labs1and2BobNessuna valutazione finora
- Matlab Chapter 1Documento14 pagineMatlab Chapter 1Chathura Priyankara WijayarathnaNessuna valutazione finora
- Lab 2Documento4 pagineLab 2geoaamer100% (1)
- FractalyseDocumento13 pagineFractalyseJuan Francisco Durango GrisalesNessuna valutazione finora
- Introduction To Matlab & Signals: ObjectiveDocumento7 pagineIntroduction To Matlab & Signals: Objectiveعمیر بن اصغرNessuna valutazione finora
- Matlab Slides IDocumento27 pagineMatlab Slides IRicky LiunaNessuna valutazione finora
- DV Lab Manual 2022-23Documento10 pagineDV Lab Manual 2022-23FS20IF015Nessuna valutazione finora
- Experiment No. 1 AIM:-To Study MATLAB Commands. THEORY:-MATLAB Is A High Performance Language For Technical ComputingDocumento6 pagineExperiment No. 1 AIM:-To Study MATLAB Commands. THEORY:-MATLAB Is A High Performance Language For Technical ComputingKissan PortalNessuna valutazione finora
- Tips For TKP4140 Project - v0Documento8 pagineTips For TKP4140 Project - v0yeeprietoNessuna valutazione finora
- Introduction To Spectral Analysis and MatlabDocumento14 pagineIntroduction To Spectral Analysis and MatlabmmcNessuna valutazione finora
- Exercise 1: Basic Modelbuilder: C:/Student/Middlesexboro/ParcelsDocumento15 pagineExercise 1: Basic Modelbuilder: C:/Student/Middlesexboro/ParcelsAbu ZyadNessuna valutazione finora
- Error MeasurementDocumento17 pagineError MeasurementRishav KoiralaNessuna valutazione finora
- Experiment 5Documento15 pagineExperiment 5SAYYAMNessuna valutazione finora
- Designing Gui With Matlab: InteractiveDocumento16 pagineDesigning Gui With Matlab: InteractiveNaidan DensmaaNessuna valutazione finora
- Coursework Assignment: LinksDocumento9 pagineCoursework Assignment: LinksXady Saud KhanNessuna valutazione finora
- Matlab PrimerDocumento27 pagineMatlab Primerneit_tadNessuna valutazione finora
- Computer Application 6.0Documento140 pagineComputer Application 6.0George RansunNessuna valutazione finora
- 01 02 Matlab Basics M1 M2 2022Documento28 pagine01 02 Matlab Basics M1 M2 2022Sheeraz AhmedNessuna valutazione finora
- Faculty of Science - Course OutlineDocumento11 pagineFaculty of Science - Course OutlineMallgi34Nessuna valutazione finora
- ENGG 1300 Engineering Mechanics 1: Lab: 2 - Motion of A Rolling DiskDocumento7 pagineENGG 1300 Engineering Mechanics 1: Lab: 2 - Motion of A Rolling DiskMallgi34Nessuna valutazione finora
- Formula Sheet PDFDocumento3 pagineFormula Sheet PDFMallgi34Nessuna valutazione finora
- ENGG1300 Lab Report: Moment of A Rolling Disc: Student Name, z1234567Documento4 pagineENGG1300 Lab Report: Moment of A Rolling Disc: Student Name, z1234567Mallgi34Nessuna valutazione finora
- ENGG1300 Engineering Mechanics 1Documento14 pagineENGG1300 Engineering Mechanics 1Mallgi34Nessuna valutazione finora
- Report Writing Notes: PrefaceDocumento10 pagineReport Writing Notes: PrefaceMallgi34Nessuna valutazione finora
- Example Motor PDFDocumento1 paginaExample Motor PDFMallgi34Nessuna valutazione finora
- Childhood Among The Ferns: Thomas HardyDocumento1 paginaChildhood Among The Ferns: Thomas HardyMallgi34Nessuna valutazione finora
- Melodic DictationDocumento1 paginaMelodic DictationMallgi34Nessuna valutazione finora
- JBGRDocumento29 pagineJBGRMallgi34Nessuna valutazione finora
- Gold Award Reflection: GeneralDocumento1 paginaGold Award Reflection: GeneralMallgi34Nessuna valutazione finora
- Lshort A5Documento146 pagineLshort A5Mallgi34100% (1)
- Research Paper No. 475: // Stanford UniversityDocumento26 pagineResearch Paper No. 475: // Stanford UniversityDat TranNessuna valutazione finora
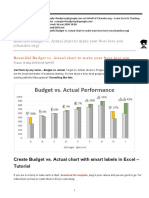
- Budget V Actual ChartDocumento13 pagineBudget V Actual Chartzudan2013Nessuna valutazione finora
- Conquest Tutorial 7 MultidimensionalModelsDocumento20 pagineConquest Tutorial 7 MultidimensionalModelsfafume100% (1)
- Department: Program Name/Code: B TECH/ Course Name/Code:: Question BankDocumento16 pagineDepartment: Program Name/Code: B TECH/ Course Name/Code:: Question BankCameoutNessuna valutazione finora
- 12Documento2 pagine12Carlo ParasNessuna valutazione finora
- Temperature and Relative Humidity Distributions in A Medium-Size Administrative Town in Southwest NiDocumento12 pagineTemperature and Relative Humidity Distributions in A Medium-Size Administrative Town in Southwest Nijoseph ayomideNessuna valutazione finora
- Financial Markets - Chapter 5 - Overview of Risk and ReturnDocumento29 pagineFinancial Markets - Chapter 5 - Overview of Risk and ReturnCharrise BechaydaNessuna valutazione finora
- Factorial Analysis of VarianceDocumento20 pagineFactorial Analysis of VarianceRiza Arifianto MarasabessyNessuna valutazione finora
- Kuliah Minggu-3Documento13 pagineKuliah Minggu-3teesaganNessuna valutazione finora
- Activity On EstimationDocumento2 pagineActivity On EstimationJose BenaventeNessuna valutazione finora
- Macoergonomic Analysis An Design (MEAD) of Worf System ProcessDocumento5 pagineMacoergonomic Analysis An Design (MEAD) of Worf System ProcessHuber AponteNessuna valutazione finora
- STATA CommandsDocumento42 pagineSTATA Commandsmaz_wied74Nessuna valutazione finora
- Quantitative Methods For Business 13th Edition by David R Anderson Ebook PDFDocumento42 pagineQuantitative Methods For Business 13th Edition by David R Anderson Ebook PDFsamantha.ryan702100% (38)
- Multi-Span Prestressed Concrete Girder Bridges W CVRDocumento39 pagineMulti-Span Prestressed Concrete Girder Bridges W CVRSony Jsd100% (1)
- Determining Floor Flatness and Floor Levelness Numbers: Standard Test Method ForDocumento8 pagineDetermining Floor Flatness and Floor Levelness Numbers: Standard Test Method ForBuddhikaNessuna valutazione finora
- Measurement of Non-Circular Home Range: I. JennrichDocumento11 pagineMeasurement of Non-Circular Home Range: I. JennrichDiego UgarteNessuna valutazione finora
- Effects of Using Tagalog As Medium of Instruction in Teaching Grade 6 ScienceDocumento16 pagineEffects of Using Tagalog As Medium of Instruction in Teaching Grade 6 ScienceJasmin GalanoNessuna valutazione finora
- Expectations - NotesDocumento3 pagineExpectations - NotesPranav SuryaNessuna valutazione finora
- AstmDocumento8 pagineAstmramonNessuna valutazione finora
- Quantitative MethodsDocumento18 pagineQuantitative MethodsNikhil SawantNessuna valutazione finora
- Efficient FrontierDocumento7 pagineEfficient Frontierdubuli123Nessuna valutazione finora
- Penelope 2014Documento408 paginePenelope 2014JaviCanteroNessuna valutazione finora
- Project Title: Buying Patterns of Levi's JeansDocumento7 pagineProject Title: Buying Patterns of Levi's JeansVivekananda PalNessuna valutazione finora
- Lesson 6 - Statistics For Data Science - IIDocumento60 pagineLesson 6 - Statistics For Data Science - IIrimbrahimNessuna valutazione finora
- Cambridge International AS & A Level Mathematics: Probability & Statistics 2Documento47 pagineCambridge International AS & A Level Mathematics: Probability & Statistics 2StrixNessuna valutazione finora
- Mca R16-Scet SyllabusDocumento135 pagineMca R16-Scet SyllabusSiva KiranNessuna valutazione finora
- Continued Process Verification (CPV) Signal Responses in Biopharma - Pharmaceutical EngineeringDocumento22 pagineContinued Process Verification (CPV) Signal Responses in Biopharma - Pharmaceutical EngineeringJohn PerezNessuna valutazione finora
- EC212: Introduction To Econometrics Multiple Regression: Estimation (Wooldridge, Ch. 3)Documento76 pagineEC212: Introduction To Econometrics Multiple Regression: Estimation (Wooldridge, Ch. 3)SHUMING ZHUNessuna valutazione finora
- Profit Signals How Evidence Based Decisions Power Six Sigma BreakthroughsDocumento262 pagineProfit Signals How Evidence Based Decisions Power Six Sigma BreakthroughsM. Daniel SloanNessuna valutazione finora
- Mental Math Secrets - How To Be a Human CalculatorDa EverandMental Math Secrets - How To Be a Human CalculatorValutazione: 5 su 5 stelle5/5 (3)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormDa EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormValutazione: 5 su 5 stelle5/5 (5)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeDa EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeValutazione: 4 su 5 stelle4/5 (2)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Da EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Valutazione: 5 su 5 stelle5/5 (1)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsDa EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsValutazione: 4.5 su 5 stelle4.5/5 (3)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldDa EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldValutazione: 3 su 5 stelle3/5 (80)
- Calculus Workbook For Dummies with Online PracticeDa EverandCalculus Workbook For Dummies with Online PracticeValutazione: 3.5 su 5 stelle3.5/5 (8)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingDa EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingValutazione: 4.5 su 5 stelle4.5/5 (21)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Da EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Nessuna valutazione finora
- Images of Mathematics Viewed Through Number, Algebra, and GeometryDa EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryNessuna valutazione finora
- ParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)Da EverandParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)Nessuna valutazione finora
- Interactive Math Notebook Resource Book, Grade 6Da EverandInteractive Math Notebook Resource Book, Grade 6Nessuna valutazione finora
- Math Workshop, Grade K: A Framework for Guided Math and Independent PracticeDa EverandMath Workshop, Grade K: A Framework for Guided Math and Independent PracticeValutazione: 5 su 5 stelle5/5 (1)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsDa EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsValutazione: 3.5 su 5 stelle3.5/5 (9)
- A-level Maths Revision: Cheeky Revision ShortcutsDa EverandA-level Maths Revision: Cheeky Revision ShortcutsValutazione: 3.5 su 5 stelle3.5/5 (8)
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathDa EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathValutazione: 5 su 5 stelle5/5 (1)