Potrebbero piacerti anche
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
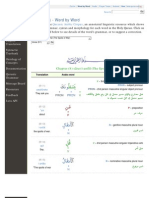
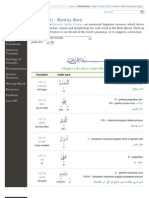
- Verse (7:1) - Word by Word: Quranic Arabic CorpusDocumento440 pagineVerse (7:1) - Word by Word: Quranic Arabic CorpusaminchatNessuna valutazione finora
- Quantitative Historical Linguistics A Corpus Framework (Oxford Studies in Diachronic and Historical Linguistics)Documento247 pagineQuantitative Historical Linguistics A Corpus Framework (Oxford Studies in Diachronic and Historical Linguistics)ChristianNessuna valutazione finora
- Natural Language Processing PDFDocumento170 pagineNatural Language Processing PDFfhmjnuNessuna valutazione finora
- Statistical Natural Language ProcessingDocumento31 pagineStatistical Natural Language ProcessingramlohaniNessuna valutazione finora
- NLTK: The Natural Language Toolkit: Steven Bird Edward LoperDocumento4 pagineNLTK: The Natural Language Toolkit: Steven Bird Edward LoperYash GautamNessuna valutazione finora
- Charles Meyer - English Corpus Linguistics - An IntroductionDocumento185 pagineCharles Meyer - English Corpus Linguistics - An IntroductionMiation93% (15)
- A Dependency Treebank of The Quran Using Traditional Arabic Grammar - IEEE Conference PublicationDocumento7 pagineA Dependency Treebank of The Quran Using Traditional Arabic Grammar - IEEE Conference Publicationوديع القباطيNessuna valutazione finora
- Verse (64:1) - Word by Word: Chapter (64) Sūrat L-Taghābun (Mutual Loss & Gain)Documento30 pagineVerse (64:1) - Word by Word: Chapter (64) Sūrat L-Taghābun (Mutual Loss & Gain)aminchatNessuna valutazione finora
- Verse (8:1) - Word by Word: Quranic Arabic CorpusDocumento162 pagineVerse (8:1) - Word by Word: Quranic Arabic CorpusaminchatNessuna valutazione finora
- Quantitative Aspects of Journal of Quantitative Linguistics.Documento34 pagineQuantitative Aspects of Journal of Quantitative Linguistics.rachelNessuna valutazione finora
- The Python Papers Volume 1, Issue 1Documento16 pagineThe Python Papers Volume 1, Issue 1edexterNessuna valutazione finora
- TLT11 ProceedingsDocumento198 pagineTLT11 ProceedingsRiyaz BhatNessuna valutazione finora
- Conjunct Verbs in Punjabi and Across Indo-Aryan A Corpus StudyDocumento7 pagineConjunct Verbs in Punjabi and Across Indo-Aryan A Corpus Studycamill chemleyNessuna valutazione finora
- Assessing Approaches To Genre ClassificationDocumento72 pagineAssessing Approaches To Genre ClassificationAnonymous RrGVQjNessuna valutazione finora
- Verse (48:1) - Word by Word: Quranic Arabic CorpusDocumento74 pagineVerse (48:1) - Word by Word: Quranic Arabic CorpusaminchatNessuna valutazione finora
- Ch4-Phrase-Structure Grammars and Dependency Grammars PDFDocumento48 pagineCh4-Phrase-Structure Grammars and Dependency Grammars PDFfefwefeNessuna valutazione finora
- Verse (17:1) - Word by Word: Quranic Arabic CorpusDocumento208 pagineVerse (17:1) - Word by Word: Quranic Arabic CorpusaminchatNessuna valutazione finora
- John Benjamins Publishing CompanyDocumento14 pagineJohn Benjamins Publishing CompanyGeorge WalkdenNessuna valutazione finora
- Enhancing Czech Parsing With Verb Valency Frames: March 2013Documento13 pagineEnhancing Czech Parsing With Verb Valency Frames: March 2013Leonardo Santos PereiraNessuna valutazione finora
- Dukes 11 PGRDocumento37 pagineDukes 11 PGRsindurationNessuna valutazione finora
- Applications of Deep Learning To Sentiment Analysis of Movie ReviewsDocumento8 pagineApplications of Deep Learning To Sentiment Analysis of Movie ReviewsTamara KomnenićNessuna valutazione finora
- Naka Kaju WotDocumento4 pagineNaka Kaju WotterreNessuna valutazione finora
- Critical Survey of The Freely Available Arabic Corpora: Wajdi ZaghouaniDocumento8 pagineCritical Survey of The Freely Available Arabic Corpora: Wajdi Zaghouaniوديع القباطيNessuna valutazione finora
- Scaling Up. Using The WWW To Resolve PP Attachment AmbiguitiesDocumento5 pagineScaling Up. Using The WWW To Resolve PP Attachment AmbiguitieslikufaneleNessuna valutazione finora
- Towards An Automated Semiotic Analysis of The Romanian Political DiscourseDocumento30 pagineTowards An Automated Semiotic Analysis of The Romanian Political DiscourseAna MariaNessuna valutazione finora
- TreebankDocumento17 pagineTreebankmiskoscribdNessuna valutazione finora
- Online Visualization of Traditional Quranic Grammar Using Dependency GraphsDocumento15 pagineOnline Visualization of Traditional Quranic Grammar Using Dependency Graphskissangou aboubakrNessuna valutazione finora
- Vilem Mathesius and Functional Sentence Perspective-DefDocumento11 pagineVilem Mathesius and Functional Sentence Perspective-DefvyNessuna valutazione finora
- NLP Unit II NotesDocumento18 pagineNLP Unit II Notesnsyadav89590% (1)
- 018Documento209 pagine018aminchatNessuna valutazione finora