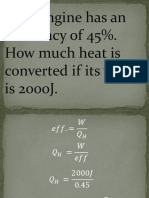Potrebbero piacerti anche
- Your Family Medical History Questionnaire: All About YouDocumento5 pagineYour Family Medical History Questionnaire: All About YouLemuel Glenn BautistaNessuna valutazione finora
- WWW - Ib.academy: Study GuideDocumento122 pagineWWW - Ib.academy: Study GuideHendrikEspinozaLoyola100% (2)
- Gothic Revival ArchitectureDocumento19 pagineGothic Revival ArchitectureAlexandra Maria NeaguNessuna valutazione finora
- Quarter 2-Module 7 Social and Political Stratification: Department of Education Republic of The PhilippinesDocumento21 pagineQuarter 2-Module 7 Social and Political Stratification: Department of Education Republic of The Philippinestricia100% (5)
- ATLS Note Ed 10Documento51 pagineATLS Note Ed 10Nikko Caesario Mauldy Susilo100% (10)
- Aroma TherapyDocumento89 pagineAroma TherapyHemanth Kumar G0% (1)
- Sickle Cell AnemiaDocumento13 pagineSickle Cell Anemiamayra100% (1)
- Second Grading EappDocumento2 pagineSecond Grading EappConnieRoseRamos100% (2)
- Ccounting Basics and Interview Questions AnswersDocumento18 pagineCcounting Basics and Interview Questions AnswersAamir100% (1)
- Module One ChaPTER ONE - PsychDocumento15 pagineModule One ChaPTER ONE - PsychArvella Albay100% (1)
- Tabu Ran NormalDocumento14 pagineTabu Ran NormalSylvia100% (1)
- Analysis of Co-Variance (ANCOVA) and Multivariate Analysis of Co-Variance (Mancova)Documento37 pagineAnalysis of Co-Variance (ANCOVA) and Multivariate Analysis of Co-Variance (Mancova)AC Balio100% (1)
- Introduction To E-Business SystemsDocumento19 pagineIntroduction To E-Business SystemsArtur97% (79)
- Testing For Normality Using SPSS PDFDocumento12 pagineTesting For Normality Using SPSS PDFΧρήστος Ντάνης100% (1)
- Republic Vs CA - Land Titles and Deeds - GR No. 127060Documento3 pagineRepublic Vs CA - Land Titles and Deeds - GR No. 127060Maya Sin-ot ApaliasNessuna valutazione finora
- Case-Control Study: Dr. Sourab Kumar DasDocumento31 pagineCase-Control Study: Dr. Sourab Kumar DasSanjeet SahNessuna valutazione finora
- Qualitative QuantitativeDocumento43 pagineQualitative QuantitativeSultanZebNessuna valutazione finora
- Sampling and Sampling TechniquesDocumento25 pagineSampling and Sampling TechniquesNinoNessuna valutazione finora
- Problems of ResearchDocumento4 pagineProblems of ResearchJuan dela CruzNessuna valutazione finora
- Study DesignsDocumento24 pagineStudy DesignsJasmen Sabroso PasiaNessuna valutazione finora
- LANDBANK Iaccess FAQs PDFDocumento16 pagineLANDBANK Iaccess FAQs PDFYsabella May Sarthou CervantesNessuna valutazione finora
- LANDBANK Iaccess FAQs PDFDocumento16 pagineLANDBANK Iaccess FAQs PDFYsabella May Sarthou CervantesNessuna valutazione finora
- LANDBANK Iaccess FAQs PDFDocumento16 pagineLANDBANK Iaccess FAQs PDFYsabella May Sarthou CervantesNessuna valutazione finora
- LANDBANK Iaccess FAQs PDFDocumento16 pagineLANDBANK Iaccess FAQs PDFYsabella May Sarthou CervantesNessuna valutazione finora
- Chap3 Developing Research ProposalDocumento37 pagineChap3 Developing Research Proposalketema simeNessuna valutazione finora
- Planet Maths 5th - Sample PagesDocumento30 paginePlanet Maths 5th - Sample PagesEdTech Folens48% (29)
- Non Parametric TestsDocumento6 pagineNon Parametric TestsRohit Vishal Kumar100% (9)
- Chapter-7 Sampling DesignDocumento74 pagineChapter-7 Sampling DesignShikha SinghNessuna valutazione finora
- Unit - Iv Research Approaches and Design (Part-1)Documento84 pagineUnit - Iv Research Approaches and Design (Part-1)Raj karthikNessuna valutazione finora
- Sample Informed Consent Form: Instructions To The Student ResearcherDocumento1 paginaSample Informed Consent Form: Instructions To The Student ResearcherSylark100% (1)
- IKM - Sample Size Calculation in Epid Study PDFDocumento7 pagineIKM - Sample Size Calculation in Epid Study PDFcindyNessuna valutazione finora
- Advantages and Disadvantages of Global WarmingDocumento11 pagineAdvantages and Disadvantages of Global WarmingA Aldika Farlis50% (2)
- Research Methodology PDFDocumento250 pagineResearch Methodology PDFRafzeenaNessuna valutazione finora
- Types of Statistical AnalysisDocumento2 pagineTypes of Statistical AnalysispunojanielynNessuna valutazione finora
- Factorial DesignsDocumento23 pagineFactorial Designsrujira1968100% (1)
- Experimental Research DesignDocumento3 pagineExperimental Research Designnabeel100% (1)
- Inferential StatisticsDocumento23 pagineInferential StatisticsAki StephyNessuna valutazione finora
- Dynamics of Disease TransmissionDocumento23 pagineDynamics of Disease TransmissionAkshay SavvasheriNessuna valutazione finora
- Survey Methods in Social InvestigationDocumento1 paginaSurvey Methods in Social InvestigationGuruKPONessuna valutazione finora
- Planning Survey ResearchDocumento6 paginePlanning Survey ResearchOxfamNessuna valutazione finora
- Partial CorrelationDocumento2 paginePartial CorrelationSanjana PrabhuNessuna valutazione finora
- SamplingDocumento41 pagineSamplingShailendra DhakadNessuna valutazione finora
- Experiment ResearchDocumento13 pagineExperiment ResearchmazorodzesNessuna valutazione finora
- Psychology 1: Intro To Psychology Dr. Jay A. GarciaDocumento25 paginePsychology 1: Intro To Psychology Dr. Jay A. GarciaRed MistNessuna valutazione finora
- How To Write A Research ArticleDocumento3 pagineHow To Write A Research Articlejaden rocksNessuna valutazione finora
- Rajiv Gandhi University of Health Sciences Karnataka, BangaloreDocumento13 pagineRajiv Gandhi University of Health Sciences Karnataka, BangaloreJyotiNessuna valutazione finora
- Descriptive Research: Characteristics Value, Importance, and Advantages TechniquesDocumento9 pagineDescriptive Research: Characteristics Value, Importance, and Advantages TechniquesApril MataloteNessuna valutazione finora
- IRM Experimental Research NewDocumento4 pagineIRM Experimental Research Newarum26elshaf100% (1)
- Biostatistics Lect 3Documento10 pagineBiostatistics Lect 3zeashanzaidiNessuna valutazione finora
- Student Feedback On Teachers and Its Practices: 1. Clarify Context and FocusDocumento4 pagineStudent Feedback On Teachers and Its Practices: 1. Clarify Context and FocusVishal KumarNessuna valutazione finora
- Identifying Dependent and Independent VariableDocumento6 pagineIdentifying Dependent and Independent VariableEricka Kyra GonzalesNessuna valutazione finora
- Intra Class Correlation IccDocumento23 pagineIntra Class Correlation IccdariosumandeNessuna valutazione finora
- Parametric & Non-Parametric TestsDocumento34 pagineParametric & Non-Parametric TestsohlyanaartiNessuna valutazione finora
- Ethical Research ConsiderationsDocumento9 pagineEthical Research ConsiderationsJohn Claud HilarioNessuna valutazione finora
- Probability Sampling & Non - Probability SamplingDocumento2 pagineProbability Sampling & Non - Probability SamplingArnea Joy TajoneraNessuna valutazione finora
- Hypothesis TestingDocumento180 pagineHypothesis Testingrns116Nessuna valutazione finora
- ValidityDocumento16 pagineValidityNinasakinah Mp ArzNessuna valutazione finora
- Likert ScaleDocumento2 pagineLikert ScaleIvani KatalNessuna valutazione finora
- VARIABLESDocumento19 pagineVARIABLESBellyJane LarracasNessuna valutazione finora
- 1 Running Head: Research Methods ComparisonsDocumento8 pagine1 Running Head: Research Methods ComparisonsGeorge MainaNessuna valutazione finora
- Ignificance and Types: .3.0 ObjectivesDocumento9 pagineIgnificance and Types: .3.0 ObjectivesJananee RajagopalanNessuna valutazione finora
- Word Social Inequality Essay HealthDocumento8 pagineWord Social Inequality Essay HealthAntoCurranNessuna valutazione finora
- Introduction To Research Methodology FinalDocumento65 pagineIntroduction To Research Methodology FinalabhishekniiftNessuna valutazione finora
- Data CollectionDocumento31 pagineData Collectionvrvasuki100% (2)
- Unit 1 PDFDocumento15 pagineUnit 1 PDFMohammed FarshidNessuna valutazione finora
- Research Methodology 22Documento28 pagineResearch Methodology 22Ahmed MalikNessuna valutazione finora
- Reference Booklet For NutritionistsDocumento27 pagineReference Booklet For NutritionistsChristopher Smith100% (1)
- Public Speaking 1227589720850231 9Documento21 paginePublic Speaking 1227589720850231 9shahrilcangNessuna valutazione finora
- 8) Multilevel AnalysisDocumento41 pagine8) Multilevel AnalysisMulusewNessuna valutazione finora
- Chapter Four Correlation Analysis: Positive or NegativeDocumento15 pagineChapter Four Correlation Analysis: Positive or NegativeSohidul IslamNessuna valutazione finora
- Sampling in Research MethodologyDocumento18 pagineSampling in Research Methodologyselva20Nessuna valutazione finora
- Research Assistant: Passbooks Study GuideDa EverandResearch Assistant: Passbooks Study GuideNessuna valutazione finora
- EXPEREMENTAL Experimental Research Is A StudyDocumento7 pagineEXPEREMENTAL Experimental Research Is A Studybeljanske ocarizaNessuna valutazione finora
- Experimental ResearchDocumento4 pagineExperimental ResearchJeza Estaura CuizonNessuna valutazione finora
- Course Title: Theories of Child and DevelopmentDocumento8 pagineCourse Title: Theories of Child and DevelopmentKitur CarolineNessuna valutazione finora
- Higher Order ThinkingDocumento83 pagineHigher Order Thinkingtangent12Nessuna valutazione finora
- The Resultant With A Dotted Line and Arrowhead. If There Is No Resultant, Write "No R"Documento2 pagineThe Resultant With A Dotted Line and Arrowhead. If There Is No Resultant, Write "No R"tangent12100% (1)
- HW3.1 VectorAdditionWorksheet PDFDocumento4 pagineHW3.1 VectorAdditionWorksheet PDFtangent12Nessuna valutazione finora
- Ef152 Lec301 Temperature Thermal Expansion PDFDocumento4 pagineEf152 Lec301 Temperature Thermal Expansion PDFtangent12Nessuna valutazione finora
- Solution: Chapter 12 ProblemsDocumento5 pagineSolution: Chapter 12 Problemstangent12Nessuna valutazione finora
- Module 2 ThermodynamicsDocumento28 pagineModule 2 ThermodynamicsJoab TorresNessuna valutazione finora
- Or Use Any Search Engine To Get A Picture/photo of The World MapDocumento1 paginaOr Use Any Search Engine To Get A Picture/photo of The World Maptangent12Nessuna valutazione finora
- Sykes Hmo Benefit Plan 2016Documento16 pagineSykes Hmo Benefit Plan 2016Secret SecretNessuna valutazione finora
- BarangaysDocumento4 pagineBarangayslov3m3Nessuna valutazione finora
- Performance Task No. 03Documento1 paginaPerformance Task No. 03tangent12100% (1)
- Nyb Ps Sol 1.compressed PDFDocumento15 pagineNyb Ps Sol 1.compressed PDFtangent12Nessuna valutazione finora
- Nyb Ps Sol 1.compressed PDFDocumento15 pagineNyb Ps Sol 1.compressed PDFtangent12Nessuna valutazione finora
- PDFDocumento1 paginaPDFtangent12Nessuna valutazione finora
- AcucDocumento37 pagineAcuclauraningsihNessuna valutazione finora
- Ans Exmpl Probs1 Thermo PDFDocumento4 pagineAns Exmpl Probs1 Thermo PDFtangent12Nessuna valutazione finora
- Heat Engine QuestionsDocumento12 pagineHeat Engine Questionstangent12Nessuna valutazione finora
- 03 Equilibrium of Concurrent Forces Force TableDocumento6 pagine03 Equilibrium of Concurrent Forces Force TableBenjie Catulin BuceNessuna valutazione finora
- Identifying Controls & Variables Practice Worksheet KeyDocumento2 pagineIdentifying Controls & Variables Practice Worksheet KeyEvaMarieEsperaNessuna valutazione finora
- We Add 20g o-WPS OfficeDocumento1 paginaWe Add 20g o-WPS Officetangent12Nessuna valutazione finora
- Hacking and TecDocumento1 paginaHacking and Tectangent12Nessuna valutazione finora
- Identifying Controls & Variables Practice Worksheet KeyDocumento2 pagineIdentifying Controls & Variables Practice Worksheet KeyEvaMarieEsperaNessuna valutazione finora
- Worksheet - Iden-WPS OfficeDocumento1 paginaWorksheet - Iden-WPS Officetangent12Nessuna valutazione finora
- ReportingDocumento12 pagineReportingtangent12Nessuna valutazione finora
- VolcanoDocumento1 paginaVolcanotangent12Nessuna valutazione finora
- Curr IntroDocumento52 pagineCurr IntroNawafNessuna valutazione finora
- Names of AllahDocumento8 pagineNames of AllahAfshaan BanuNessuna valutazione finora
- Flow ChemistryDocumento6 pagineFlow Chemistryrr1819Nessuna valutazione finora
- Villegas vs. Subido - Case DigestDocumento5 pagineVillegas vs. Subido - Case DigestLouvanne Jessa Orzales BesingaNessuna valutazione finora
- Million-Day Gregorian-Julian Calendar - NotesDocumento10 pagineMillion-Day Gregorian-Julian Calendar - Notesraywood100% (1)
- BSCHMCTT 101Documento308 pagineBSCHMCTT 101JITTUNessuna valutazione finora
- Oration For Jon Kyle ValdehuezaDocumento2 pagineOration For Jon Kyle ValdehuezaJakes ValNessuna valutazione finora
- Full Download Social Animal 14th Edition Aronson Test BankDocumento35 pagineFull Download Social Animal 14th Edition Aronson Test Banknaeensiyev100% (32)
- Mathematics - Grade 9 - First QuarterDocumento9 pagineMathematics - Grade 9 - First QuarterSanty Enril Belardo Jr.Nessuna valutazione finora
- Soal Midtest + Kunci JawabanDocumento28 pagineSoal Midtest + Kunci JawabanYuyun RasulongNessuna valutazione finora
- Spouses Aggabao V. Parulan, Jr. and Parulan G.R. No. 165803, (September 1, 2010) Doctrine (S)Documento9 pagineSpouses Aggabao V. Parulan, Jr. and Parulan G.R. No. 165803, (September 1, 2010) Doctrine (S)RJNessuna valutazione finora
- The Role of Financial System in DevelopmentDocumento5 pagineThe Role of Financial System in DevelopmentCritical ThinkerNessuna valutazione finora
- CBSE Class 12 Business Studies Question Paper 2013 With SolutionsDocumento19 pagineCBSE Class 12 Business Studies Question Paper 2013 With SolutionsManormaNessuna valutazione finora
- Class 12 Accountancy HHDocumento58 pagineClass 12 Accountancy HHkomal barotNessuna valutazione finora
- Tool Stack Template 2013Documento15 pagineTool Stack Template 2013strganeshkumarNessuna valutazione finora
- Unit 2 Foundations of CurriculumDocumento20 pagineUnit 2 Foundations of CurriculumKainat BatoolNessuna valutazione finora
- Ernesto Sirolli - Eenterprise FacilitationDocumento300 pagineErnesto Sirolli - Eenterprise FacilitationFrancis James Leite Marques PereiraNessuna valutazione finora
- Strategi Pencegahan Kecelakaan Di PT VALE Indonesia Presentation To FPP Workshop - APKPI - 12102019Documento35 pagineStrategi Pencegahan Kecelakaan Di PT VALE Indonesia Presentation To FPP Workshop - APKPI - 12102019Eko Maulia MahardikaNessuna valutazione finora
- A Study of The Concept of Future-Proofing in Healtcare Building Asset Menagement and The Role of BIM in Its DeliveryDocumento285 pagineA Study of The Concept of Future-Proofing in Healtcare Building Asset Menagement and The Role of BIM in Its DeliveryFausto FaviaNessuna valutazione finora