Potrebbero piacerti anche
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Portable Document Format Reference Manual - Version 1.1Documento298 paginePortable Document Format Reference Manual - Version 1.1Akihito Hashimoto100% (1)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Johnson Michelle Resume Business Systems AnalystDocumento3 pagineJohnson Michelle Resume Business Systems Analystmichelle johnson100% (1)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Five Stages of Business GrowthDocumento2 pagineThe Five Stages of Business GrowthRachel Honey100% (2)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Wood Working - Plan - Arcade Cabinet PlansDocumento4 pagineWood Working - Plan - Arcade Cabinet Plansgubem100% (1)
- Aix Interview QuestionsDocumento86 pagineAix Interview Questionssumit6in100% (1)
- Iso 10684 PDFDocumento27 pagineIso 10684 PDFAliceNessuna valutazione finora
- Esp SizingDocumento17 pagineEsp SizingAmin ElfatihNessuna valutazione finora
- D601005184 Man 001Documento17 pagineD601005184 Man 001Riski Kurniawan100% (1)
- School of Maritime Studies Vels University Thalambur: Fire Nozzle AimDocumento2 pagineSchool of Maritime Studies Vels University Thalambur: Fire Nozzle AimAayush AgrawalNessuna valutazione finora
- Seventh Edition Cement Hand BookDocumento6 pagineSeventh Edition Cement Hand Booksatfas50% (2)
- Split & Remove Product Automation: Cisco Systems Inc. (Confidential)Documento6 pagineSplit & Remove Product Automation: Cisco Systems Inc. (Confidential)Anusha JNessuna valutazione finora
- Arrears TestDocumento35 pagineArrears TestAnusha JNessuna valutazione finora
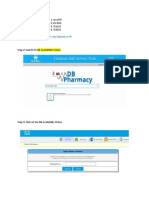
- Step by Step Document of The DB Health CheckupsDocumento3 pagineStep by Step Document of The DB Health CheckupsAnusha JNessuna valutazione finora
- Release Onboarding V1.1Documento25 pagineRelease Onboarding V1.1Anusha JNessuna valutazione finora
- Python Baiscs 17jul 1Documento14 paginePython Baiscs 17jul 1Anusha JNessuna valutazione finora
- Customer Service Delivery HRMS Olympus Integration v1Documento18 pagineCustomer Service Delivery HRMS Olympus Integration v1Anusha JNessuna valutazione finora
- Testing Fresher Resume SamplesDocumento4 pagineTesting Fresher Resume Samplesmanjusha gantaNessuna valutazione finora
- CCWR - 1 CCWR - 2 CCWR - 3 CCWR - 4 Disti Net Price KT - 6 Disti Net Price KT - 7 Disti Net Price KT - 8Documento3 pagineCCWR - 1 CCWR - 2 CCWR - 3 CCWR - 4 Disti Net Price KT - 6 Disti Net Price KT - 7 Disti Net Price KT - 8Anusha JNessuna valutazione finora
- Optical Fiber Communication Notes PDFDocumento254 pagineOptical Fiber Communication Notes PDFPathi YashNessuna valutazione finora
- KT - Simple Present - Answerd QuestionsDocumento16 pagineKT - Simple Present - Answerd QuestionsAnusha JNessuna valutazione finora
- Text Editor Install and Configure: Windows: Notepad++Documento1 paginaText Editor Install and Configure: Windows: Notepad++vijayNessuna valutazione finora
- Freshers ResumeDocumento2 pagineFreshers ResumePramod GolewarNessuna valutazione finora
- Freshers ResumeDocumento2 pagineFreshers ResumePramod GolewarNessuna valutazione finora
- ES Process UpdateDocumento5 pagineES Process UpdateAnusha JNessuna valutazione finora
- Freshers ResumeDocumento2 pagineFreshers ResumePramod GolewarNessuna valutazione finora
- Module 5Documento14 pagineModule 5Anusha JNessuna valutazione finora
- Hanuman Chalisa in KannadaDocumento5 pagineHanuman Chalisa in Kannadasinima3Nessuna valutazione finora
- Optical Fiber Communication NotesDocumento23 pagineOptical Fiber Communication NotesAnusha JNessuna valutazione finora
- Model Paper 1Documento2 pagineModel Paper 1Anusha JNessuna valutazione finora
- Wa0003Documento24 pagineWa0003Anusha JNessuna valutazione finora
- TCS Dress Code 1Documento19 pagineTCS Dress Code 1Anusha JNessuna valutazione finora
- WC LTE 4G Module 5Documento100 pagineWC LTE 4G Module 5Anusha J100% (6)
- TCS Dress Code 1Documento19 pagineTCS Dress Code 1Anusha JNessuna valutazione finora
- Question 1.TCS TRDocumento23 pagineQuestion 1.TCS TRAnusha JNessuna valutazione finora
- Commonly Asked C++ Interview Questions - Set 1: This ThisDocumento5 pagineCommonly Asked C++ Interview Questions - Set 1: This ThisJitendra DalsaniyaNessuna valutazione finora
- Optical Wireless CommunicationDocumento1 paginaOptical Wireless CommunicationAnusha JNessuna valutazione finora
- Blue Eyes Technology: Human Operator Monitoring SystemDocumento17 pagineBlue Eyes Technology: Human Operator Monitoring SystemAnusha JNessuna valutazione finora
- 9 - 11, 8 - 22 PM)Documento11 pagine9 - 11, 8 - 22 PM)Anusha JNessuna valutazione finora
- Hardware QuestionsDocumento10 pagineHardware QuestionssathyajiNessuna valutazione finora
- 1VET954910-910 Arc EliminatorDocumento4 pagine1VET954910-910 Arc EliminatorprotectionworkNessuna valutazione finora
- Canon Ir2200 Ir2800 Ir3300 User ManualDocumento362 pagineCanon Ir2200 Ir2800 Ir3300 User ManualMohamed Kabsha50% (2)
- Andhra Pradesh Public Service CommissionDocumento3 pagineAndhra Pradesh Public Service Commissionb.veenasriNessuna valutazione finora
- 4313 Repair Mainshaft OHDocumento38 pagine4313 Repair Mainshaft OHYasin Noer Huda PNessuna valutazione finora
- Verilog Code For Simple ComputerDocumento7 pagineVerilog Code For Simple ComputerEng'r Safeer AnsarNessuna valutazione finora
- M Af470wDocumento56 pagineM Af470wwilliam lozadaNessuna valutazione finora
- Balkancar PDF Forklift Part Manual DVD Russian LanguageDocumento28 pagineBalkancar PDF Forklift Part Manual DVD Russian Languagetheodorebeck211292idm100% (126)
- Adekolavit 020111Documento18 pagineAdekolavit 020111butidontwanttoNessuna valutazione finora
- Brocas Komet. 410863V0 - PI - EN - ACR - EQDocumento2 pagineBrocas Komet. 410863V0 - PI - EN - ACR - EQMarco SilvaNessuna valutazione finora
- Tugas 11 Bahasa InggrisDocumento2 pagineTugas 11 Bahasa InggrisGesa Ananda Putra BTNFCNessuna valutazione finora
- Enhancing Institutional Mechanism Forum 1: Changing The Context by Jerolet SahagunDocumento2 pagineEnhancing Institutional Mechanism Forum 1: Changing The Context by Jerolet SahagunEJ Henz SahagunNessuna valutazione finora
- Group1: Refrigeration and Air Conditioning Course ProjectDocumento67 pagineGroup1: Refrigeration and Air Conditioning Course Projectdamola2realNessuna valutazione finora
- Elvis Presley y El FBI. Documentos Desclasificados.Documento25 pagineElvis Presley y El FBI. Documentos Desclasificados.Diario 26Nessuna valutazione finora
- Cs Fet Ee Btech PDFDocumento108 pagineCs Fet Ee Btech PDFrakshitNessuna valutazione finora
- 004 - Hadoop Daemons (HDFS Only)Documento3 pagine004 - Hadoop Daemons (HDFS Only)Srinivas ReddyNessuna valutazione finora
- BulkConfigurator PDFDocumento107 pagineBulkConfigurator PDFmatrixfrNessuna valutazione finora
- Abb Relays Catalouge PDFDocumento180 pagineAbb Relays Catalouge PDFABDUL GHAFOORNessuna valutazione finora
- Laboratory Exercise in Computer FundamentalsDocumento2 pagineLaboratory Exercise in Computer FundamentalsGwenn PosoNessuna valutazione finora
- MDGF ModulDocumento2 pagineMDGF ModulZoran NesicNessuna valutazione finora
- Pitting Trenching Activty eDocumento2 paginePitting Trenching Activty eFARHA NAAZNessuna valutazione finora