Potrebbero piacerti anche
- Semiconductor Foundry Services A Complete Guide - 2019 EditionDa EverandSemiconductor Foundry Services A Complete Guide - 2019 EditionNessuna valutazione finora
- An Internship Report On: Organization Study atDocumento18 pagineAn Internship Report On: Organization Study atKiran BabuNessuna valutazione finora
- Project Report Sample (For Reference) Aditya AgrawalDocumento54 pagineProject Report Sample (For Reference) Aditya AgrawalABHINAV IRWIN JOHN-DMNessuna valutazione finora
- T2C of Bajaj FinservDocumento9 pagineT2C of Bajaj FinservabhilashNessuna valutazione finora
- Marketing Strategy of Maruti SuzukiDocumento88 pagineMarketing Strategy of Maruti SuzukiApoorva KohliNessuna valutazione finora
- BIGBAZAARDocumento66 pagineBIGBAZAARmoxfileNessuna valutazione finora
- CRM at Big BazaarDocumento10 pagineCRM at Big BazaarPratik Tambe100% (1)
- A Study of Financial Analysis On FMCG Companies of IndiaDocumento8 pagineA Study of Financial Analysis On FMCG Companies of Indiaviral ChavdaNessuna valutazione finora
- Industry ProfileDocumento5 pagineIndustry ProfileThanga Raja0% (1)
- Marketing - COMPARATIVE STUDY OF CUSTOMERS PERCEPTION FOR HONDA & YAMAHA BIKESDocumento56 pagineMarketing - COMPARATIVE STUDY OF CUSTOMERS PERCEPTION FOR HONDA & YAMAHA BIKESShailabh KhandelwalNessuna valutazione finora
- Organizational Study of SnapdealDocumento13 pagineOrganizational Study of SnapdealShalini SharmaNessuna valutazione finora
- Strategies of Pantaloon Retail (India) LimitedDocumento10 pagineStrategies of Pantaloon Retail (India) LimitedPavan R Kulkarni75% (4)
- A Study On Comparative Analysis On Customer Satisfaction With Respect To Airtel and Reliance Jio ServicesDocumento12 pagineA Study On Comparative Analysis On Customer Satisfaction With Respect To Airtel and Reliance Jio ServicesSection DNessuna valutazione finora
- A Study of Supply Chain Management in Patanjali Ayurveda LTD SypnosisDocumento12 pagineA Study of Supply Chain Management in Patanjali Ayurveda LTD Sypnosisvinod ahlawat100% (1)
- Research Paper On Departmental Stores in MUMBAIDocumento11 pagineResearch Paper On Departmental Stores in MUMBAIankkii100% (2)
- Indian Retail Industry Its Growth Challenges and OpportunitiesDocumento9 pagineIndian Retail Industry Its Growth Challenges and Opportunitieshimanshu5232Nessuna valutazione finora
- Project On Consumer BehaviourDocumento19 pagineProject On Consumer BehavioursarthakNessuna valutazione finora
- Comparative Study of Distribution Channel of Hul': Dissertation Report ONDocumento43 pagineComparative Study of Distribution Channel of Hul': Dissertation Report ONanitin88Nessuna valutazione finora
- Final Sip ReportDocumento72 pagineFinal Sip ReportMohammad ShoebNessuna valutazione finora
- Surf ExcelDocumento77 pagineSurf ExcelSubramanya DgNessuna valutazione finora
- Satya Das SummaryDocumento24 pagineSatya Das SummarySoumika Sree0% (1)
- Project Report On Selling SkillsDocumento8 pagineProject Report On Selling SkillsKaushlendra Kumar PatelNessuna valutazione finora
- Appendix I Questionnaire On Buying Behaviour of Car PurchasersDocumento19 pagineAppendix I Questionnaire On Buying Behaviour of Car PurchasersranjithsteelNessuna valutazione finora
- Project Report On A Study On Customer Satisfaction With Reference To Coco ColaDocumento60 pagineProject Report On A Study On Customer Satisfaction With Reference To Coco Colavabexek859Nessuna valutazione finora
- Online Retail Market Basket AnalysisDocumento51 pagineOnline Retail Market Basket Analysisshivani s sharmaNessuna valutazione finora
- Synopsis On Big BazaarDocumento6 pagineSynopsis On Big BazaarHemant Rajoriya100% (2)
- Adi ShaktiDocumento69 pagineAdi ShaktilakshmiNessuna valutazione finora
- CB - Project Report MarutiDocumento36 pagineCB - Project Report Marutikoushandas19100% (2)
- SDM Report On TOIDocumento21 pagineSDM Report On TOIShashidhar TripathiNessuna valutazione finora
- Literature ReviewDocumento5 pagineLiterature ReviewGauravsNessuna valutazione finora
- Submitted in Partial Fulfillment of The Requirements For The Award of The Degree ofDocumento83 pagineSubmitted in Partial Fulfillment of The Requirements For The Award of The Degree ofAanchal GuptaNessuna valutazione finora
- The Evolution and Structure of The Two-Wheeler Industry in IndiaDocumento1 paginaThe Evolution and Structure of The Two-Wheeler Industry in IndiaSuman KumarNessuna valutazione finora
- Assignment: Sales Organisation Structure of Mahindra SwarajDocumento9 pagineAssignment: Sales Organisation Structure of Mahindra SwarajkaranvirkalraNessuna valutazione finora
- A Study On Customer Satisfaction Towards Departmental Stored in Raipur City Satyajit SarkarDocumento55 pagineA Study On Customer Satisfaction Towards Departmental Stored in Raipur City Satyajit SarkarSATYA07100% (1)
- Maruti SuzukiDocumento9 pagineMaruti SuzukiBaburaj ChoudharyNessuna valutazione finora
- A Study On Consumer Satisfaction in Honda Two WheelersDocumento32 pagineA Study On Consumer Satisfaction in Honda Two WheelersJayasudhan A.SNessuna valutazione finora
- Brand Awareness Big Bazar 79 11Documento69 pagineBrand Awareness Big Bazar 79 11Rahul KumarNessuna valutazione finora
- Project Report Chinese MobileDocumento43 pagineProject Report Chinese Mobileashu548836Nessuna valutazione finora
- CRM Project Report On Globus: Prince Arora 072 Rahul Sharma 078 Varun Mishra 112 Tarun Kumar 121Documento9 pagineCRM Project Report On Globus: Prince Arora 072 Rahul Sharma 078 Varun Mishra 112 Tarun Kumar 121Aditya ParulekarNessuna valutazione finora
- Dissertation Report On Corporate Social Responsibility in Emerging Markets1Documento65 pagineDissertation Report On Corporate Social Responsibility in Emerging Markets1JoNessuna valutazione finora
- 4 - Dainik Bhaskar CaseDocumento13 pagine4 - Dainik Bhaskar CaseGaurav SinghNessuna valutazione finora
- A Project Report On Study On After Sales Service and Customer Satisfaction of The Icici Prudential Life Insurance Company in BancassuraceDocumento34 pagineA Project Report On Study On After Sales Service and Customer Satisfaction of The Icici Prudential Life Insurance Company in BancassuraceSoma Chakraborty100% (1)
- Consumers Perception of Private BrandsDocumento8 pagineConsumers Perception of Private BrandsmanojrajinmbaNessuna valutazione finora
- Fabindia SDMDocumento37 pagineFabindia SDMGreeshmaNessuna valutazione finora
- Attitude of Rural Customers Towards Hero Honda BikesDocumento20 pagineAttitude of Rural Customers Towards Hero Honda BikesAkanksha Srivastava100% (1)
- Customer Relationship Managemnet Strategies AT NokiaDocumento25 pagineCustomer Relationship Managemnet Strategies AT NokiaSaif KhanNessuna valutazione finora
- A Study On Shoplifting and Security Measures in Big BazaarDocumento5 pagineA Study On Shoplifting and Security Measures in Big BazaarGODsml0% (1)
- Future GroupDocumento48 pagineFuture GroupMayur PanchalNessuna valutazione finora
- Cbbe Model On Titan 1Documento4 pagineCbbe Model On Titan 1jaishreeNessuna valutazione finora
- A Summer Internship Report ONDocumento55 pagineA Summer Internship Report ONkalyaniNessuna valutazione finora
- Project: A Study ON Evaluation of Customer Centricity AT Value Format Reliance Fresh Stores DelhiDocumento62 pagineProject: A Study ON Evaluation of Customer Centricity AT Value Format Reliance Fresh Stores DelhiVIJAY KUMARNessuna valutazione finora
- Consumer Perception and Brand Preference For Premium BrandedDocumento66 pagineConsumer Perception and Brand Preference For Premium BrandedanishprabhaNessuna valutazione finora
- "Consumer Buying Behaviour: A Shift From Offline To Online RetailDocumento38 pagine"Consumer Buying Behaviour: A Shift From Offline To Online RetailMohit AgarwalNessuna valutazione finora
- A Study On Online Retailing Challenges and Oppotunitis at Nettyfish Networks PVT.,LTDDocumento6 pagineA Study On Online Retailing Challenges and Oppotunitis at Nettyfish Networks PVT.,LTDIshwaryaNessuna valutazione finora
- Applications of Machine Learning For Prediction of Liver DiseaseDocumento3 pagineApplications of Machine Learning For Prediction of Liver DiseaseATSNessuna valutazione finora
- Irjet V5i4896 PDFDocumento4 pagineIrjet V5i4896 PDFM. Talha NadeemNessuna valutazione finora
- Jurnal SalsaDocumento10 pagineJurnal SalsaSalsa BillaNessuna valutazione finora
- (IJCST-V10I5P50) :DR K. Sailaja, Guttalasandu Vasudeva ReddyDocumento7 pagine(IJCST-V10I5P50) :DR K. Sailaja, Guttalasandu Vasudeva ReddyEighthSenseGroupNessuna valutazione finora
- A Comparative Study On Predicting The Probability of Liver Disease IJERTV8IS100314 PDFDocumento5 pagineA Comparative Study On Predicting The Probability of Liver Disease IJERTV8IS100314 PDFM. Talha NadeemNessuna valutazione finora
- A Tentative Analysis of Liver Disorder Using Data Mining Algorithms J48, Decision Table and Naive BayesDocumento4 pagineA Tentative Analysis of Liver Disorder Using Data Mining Algorithms J48, Decision Table and Naive BayesiirNessuna valutazione finora
- Mary Kay FinalDocumento17 pagineMary Kay Finalharsh0695Nessuna valutazione finora
- The Zombie in The Brain and The Woman Who Died LaughingDocumento40 pagineThe Zombie in The Brain and The Woman Who Died Laughingcory_ruda100% (1)
- Service Manual SM1-76-38.0: Collector Ring, ReconditionDocumento4 pagineService Manual SM1-76-38.0: Collector Ring, ReconditionJorge YuniorNessuna valutazione finora
- Showalter Female MaladyDocumento13 pagineShowalter Female MaladyKevin Sebastian Patarroyo GalindoNessuna valutazione finora
- Modeling, Control and Simulation of A Chain Link Statcom in Emtp-RvDocumento8 pagineModeling, Control and Simulation of A Chain Link Statcom in Emtp-RvBožidar Filipović-GrčićNessuna valutazione finora
- Risk Management Policy StatementDocumento13 pagineRisk Management Policy StatementRatnakumar ManivannanNessuna valutazione finora
- Ear CandlingDocumento2 pagineEar CandlingpowerleaderNessuna valutazione finora
- Module 3 Passive Heating 8.3.18Documento63 pagineModule 3 Passive Heating 8.3.18Aman KashyapNessuna valutazione finora
- Matter and Change 2008 Chapter 14Documento40 pagineMatter and Change 2008 Chapter 14cattmy100% (1)
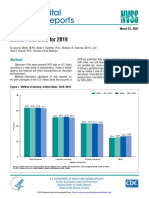
- National Vital Statistics Reports: Births: Final Data For 2019Documento51 pagineNational Vital Statistics Reports: Births: Final Data For 2019Simon ReichNessuna valutazione finora
- French Pharmacopoeia PDFDocumento15 pagineFrench Pharmacopoeia PDFHasan Abu AlhabNessuna valutazione finora
- Chan vs. ChanDocumento2 pagineChan vs. ChanMmm GggNessuna valutazione finora
- Tokyo Fact SheetDocumento17 pagineTokyo Fact Sheethoangnguyen2401Nessuna valutazione finora
- Cat 4401 UkDocumento198 pagineCat 4401 UkJuan Ignacio Sanchez DiazNessuna valutazione finora
- Drug StudyDocumento4 pagineDrug Studysnowyfingers100% (1)
- Using Oxidation States To Describe Redox Changes in A Given Reaction EquationDocumento22 pagineUsing Oxidation States To Describe Redox Changes in A Given Reaction EquationkushanNessuna valutazione finora
- Indian Income Tax Return Acknowledgement: Do Not Send This Acknowledgement To CPC, BengaluruDocumento1 paginaIndian Income Tax Return Acknowledgement: Do Not Send This Acknowledgement To CPC, BengaluruDrsex DrsexNessuna valutazione finora
- Decide If Surrogacy Is The Right ChoiceDocumento13 pagineDecide If Surrogacy Is The Right ChoiceSheen CatayongNessuna valutazione finora
- Epididymo OrchitisDocumento18 pagineEpididymo OrchitisRifqi AlridjalNessuna valutazione finora
- Basic PreservationDocumento14 pagineBasic Preservationrovinj1Nessuna valutazione finora
- How Condensing Boilers WorkDocumento1 paginaHow Condensing Boilers WorkBrianNessuna valutazione finora
- Biological ClassificationDocumento21 pagineBiological ClassificationdeviNessuna valutazione finora
- Two Drugs Are No More Effective Than One To Treat Common Kidney DiseaseDocumento3 pagineTwo Drugs Are No More Effective Than One To Treat Common Kidney DiseaseGlogogeanu Cristina AndreeaNessuna valutazione finora
- Myasthenia Gravis DiseaseDocumento14 pagineMyasthenia Gravis Diseaseapi-482100632Nessuna valutazione finora
- TEC3000 Series On/Off or Floating Fan Coil and Individual Zone Thermostat Controllers With Dehumidification CapabilityDocumento48 pagineTEC3000 Series On/Off or Floating Fan Coil and Individual Zone Thermostat Controllers With Dehumidification CapabilityIvar Denicia DelgadilloNessuna valutazione finora
- Incorporating Developmental Screening and Surveillance of Young Children in Office PracticeDocumento9 pagineIncorporating Developmental Screening and Surveillance of Young Children in Office PracticeakshayajainaNessuna valutazione finora
- Reviewer Crim 3 FinalsDocumento6 pagineReviewer Crim 3 FinalsMaria Rafaella P. DadoNessuna valutazione finora
- PackageDocumento3 paginePackagegvspavan67% (3)
- Implementation Plan SLRPDocumento6 pagineImplementation Plan SLRPAngelina SantosNessuna valutazione finora
- Ocean StarDocumento36 pagineOcean Starrobertshepard1967Nessuna valutazione finora
- Four Battlegrounds: Power in the Age of Artificial IntelligenceDa EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceValutazione: 5 su 5 stelle5/5 (5)
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziDa Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziNessuna valutazione finora
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldDa EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldValutazione: 4.5 su 5 stelle4.5/5 (55)
- Generative AI: The Insights You Need from Harvard Business ReviewDa EverandGenerative AI: The Insights You Need from Harvard Business ReviewValutazione: 4.5 su 5 stelle4.5/5 (2)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveDa EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNessuna valutazione finora
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldDa EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldValutazione: 4.5 su 5 stelle4.5/5 (107)
- Working with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)Da EverandWorking with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)Valutazione: 5 su 5 stelle5/5 (5)
- Make Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryDa EverandMake Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryNessuna valutazione finora
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindDa EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNessuna valutazione finora
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeDa EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeValutazione: 4.5 su 5 stelle4.5/5 (69)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessDa EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNessuna valutazione finora
- The Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsDa EverandThe Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsNessuna valutazione finora
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkDa EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkValutazione: 4 su 5 stelle4/5 (7)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewDa EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewValutazione: 4.5 su 5 stelle4.5/5 (104)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsDa EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsNessuna valutazione finora
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Da EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Nessuna valutazione finora
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesDa EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesValutazione: 4.5 su 5 stelle4.5/5 (13)
- Hands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesDa EverandHands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesNessuna valutazione finora
- T-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerDa EverandT-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerValutazione: 4 su 5 stelle4/5 (4)
- Artificial Intelligence: A Guide for Thinking HumansDa EverandArtificial Intelligence: A Guide for Thinking HumansValutazione: 4.5 su 5 stelle4.5/5 (30)
- The Digital Mind: How Science is Redefining HumanityDa EverandThe Digital Mind: How Science is Redefining HumanityValutazione: 4.5 su 5 stelle4.5/5 (2)
- System Design Interview: 300 Questions And Answers: Prepare And PassDa EverandSystem Design Interview: 300 Questions And Answers: Prepare And PassNessuna valutazione finora
- Python Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionDa EverandPython Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionValutazione: 5 su 5 stelle5/5 (2)
- Artificial Intelligence & Generative AI for Beginners: The Complete GuideDa EverandArtificial Intelligence & Generative AI for Beginners: The Complete GuideValutazione: 5 su 5 stelle5/5 (1)