Potrebbero piacerti anche
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Aviation EnglishDocumento86 pagineAviation Englishtmhoangvna100% (1)
- B34 - VHF Comm VSWR - Test ProcedureDocumento2 pagineB34 - VHF Comm VSWR - Test ProceduretmhoangvnaNessuna valutazione finora
- B33 - VHF Comm Aerial Polar Diag - GRD Test ProcedureDocumento1 paginaB33 - VHF Comm Aerial Polar Diag - GRD Test ProceduretmhoangvnaNessuna valutazione finora
- Long Term Skill Shortage ListDocumento8 pagineLong Term Skill Shortage ListAjesh mohanNessuna valutazione finora
- B30 - VHF Frequncy Selection SystemsDocumento1 paginaB30 - VHF Frequncy Selection SystemstmhoangvnaNessuna valutazione finora
- Diagram List (Index)Documento3 pagineDiagram List (Index)tmhoangvnaNessuna valutazione finora
- B36 - SELCAL Decoder (Marconi AD2880)Documento3 pagineB36 - SELCAL Decoder (Marconi AD2880)tmhoangvnaNessuna valutazione finora
- 3 - Physical Inst. & Systems - OcrDocumento47 pagine3 - Physical Inst. & Systems - OcrtmhoangvnaNessuna valutazione finora
- B32 - VHF Comm Systems - Functional ChecksDocumento2 pagineB32 - VHF Comm Systems - Functional CheckstmhoangvnaNessuna valutazione finora
- C10 - Pulsed & FM Circuits - Table of ContentsDocumento3 pagineC10 - Pulsed & FM Circuits - Table of ContentstmhoangvnaNessuna valutazione finora
- 5 - Radio Aids & Flight Director - OcrDocumento110 pagine5 - Radio Aids & Flight Director - OcrtmhoangvnaNessuna valutazione finora
- 3 - Pitot-Static Inst, System & ADC - OcrDocumento110 pagine3 - Pitot-Static Inst, System & ADC - OcrtmhoangvnaNessuna valutazione finora
- 4 - Engine Instruments - OcrDocumento189 pagine4 - Engine Instruments - OcrtmhoangvnaNessuna valutazione finora
- 5 - Flight Recorder - OcrDocumento19 pagine5 - Flight Recorder - OcrtmhoangvnaNessuna valutazione finora
- Airbus Handling Engine MalfunctionsDocumento17 pagineAirbus Handling Engine Malfunctionsaztec kid100% (1)
- Loi Smile Like Mona LisaDocumento1 paginaLoi Smile Like Mona LisatmhoangvnaNessuna valutazione finora
- Loi Dust in The WindDocumento1 paginaLoi Dust in The WindtmhoangvnaNessuna valutazione finora
- It's Not GoodbyeDocumento2 pagineIt's Not GoodbyeGió BuồnNessuna valutazione finora
- Airbus Handling Engine MalfunctionsDocumento17 pagineAirbus Handling Engine Malfunctionsaztec kid100% (1)
- Loi PerhapsDocumento1 paginaLoi PerhapstmhoangvnaNessuna valutazione finora
- Loi Season in The SunDocumento1 paginaLoi Season in The SuntmhoangvnaNessuna valutazione finora
- Loi Circle in The SandDocumento1 paginaLoi Circle in The SandtmhoangvnaNessuna valutazione finora
- BUSADMIN763 OutlineDocumento5 pagineBUSADMIN763 OutlinetmhoangvnaNessuna valutazione finora
- Loi Have You EverDocumento1 paginaLoi Have You EvertmhoangvnaNessuna valutazione finora
- 03 - Capacity and Constraint Management With AnswersDocumento1 pagina03 - Capacity and Constraint Management With AnswerstmhoangvnaNessuna valutazione finora
- Statistical Formulas For Statistics 1Documento5 pagineStatistical Formulas For Statistics 1Naveed AhmadNessuna valutazione finora
- Imm5257b 1 PDFDocumento1 paginaImm5257b 1 PDFtmhoangvnaNessuna valutazione finora
- Ipod Shuffle 2015 User Guide PDFDocumento30 pagineIpod Shuffle 2015 User Guide PDFLuis Hernando Mojica MendozaNessuna valutazione finora
- BUSADMIN761Documento5 pagineBUSADMIN761tmhoangvnaNessuna valutazione finora
- SCM VNDocumento35 pagineSCM VNtmhoangvnaNessuna valutazione finora
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (73)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (120)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Econometrics I: Dummy Variable Regression ModelsDocumento68 pagineEconometrics I: Dummy Variable Regression ModelsRida7Nessuna valutazione finora
- Discussion 3: AnswerDocumento7 pagineDiscussion 3: Answerحسن الفضيلNessuna valutazione finora
- Chapter Iii: Sampling and Sampling DistributionDocumento4 pagineChapter Iii: Sampling and Sampling DistributionGlecil Joy DalupoNessuna valutazione finora
- Chapter 7 - Regression AnalysisDocumento111 pagineChapter 7 - Regression AnalysisNicole Agustin100% (1)
- Leanmap FREE Hypothesis Testing CalculatorDocumento1 paginaLeanmap FREE Hypothesis Testing CalculatorWixi MundoNessuna valutazione finora
- Wattpad Reading Habit Towards Students Writing Self EfficacyDocumento15 pagineWattpad Reading Habit Towards Students Writing Self EfficacyJanice SarmientoNessuna valutazione finora
- Business Statistics: Quiz On CorrelationDocumento50 pagineBusiness Statistics: Quiz On CorrelationAnchu Theresa JacobNessuna valutazione finora
- Stock Watson 3U ExerciseSolutions Chapter12 StudentsDocumento6 pagineStock Watson 3U ExerciseSolutions Chapter12 Studentsgfdsa123tryaggNessuna valutazione finora
- Collaborative Review Task M2 1Documento19 pagineCollaborative Review Task M2 1Abdullah AbdullahNessuna valutazione finora
- Matching RegressionDocumento6 pagineMatching RegressionYoussef UcefNessuna valutazione finora
- TVPS 3 (Tablas Correctoras)Documento14 pagineTVPS 3 (Tablas Correctoras)Rosa Vilanova100% (3)
- 2 Normal DistributionDocumento39 pagine2 Normal DistributionDANELYN PINGKIANNessuna valutazione finora
- Statistics GlossaryDocumento3 pagineStatistics Glossaryapi-3836734Nessuna valutazione finora
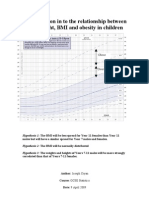
- An Investigation in To The Relationship Between Height, Weight, BMI and Obesity in ChildrenDocumento71 pagineAn Investigation in To The Relationship Between Height, Weight, BMI and Obesity in ChildrenJoe CryanNessuna valutazione finora
- RM RoughDocumento440 pagineRM RoughAditya JainNessuna valutazione finora
- Multidimensional Scale For Measuring Rural LeadershipDocumento7 pagineMultidimensional Scale For Measuring Rural LeadershipDr. Amulya Kumar MohantyNessuna valutazione finora
- Nelson RulesDocumento4 pagineNelson RulesAB GAMINGNessuna valutazione finora
- Econometrics - Chapter 1 - Introduction To Econometrics - Shalabh, IIT KanpurDocumento11 pagineEconometrics - Chapter 1 - Introduction To Econometrics - Shalabh, IIT KanpurNameet JainNessuna valutazione finora
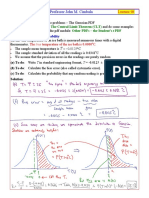
- ME345 Professor John M. Cimbala: The True Temperature of The Ice Bath Is 0.0000 CDocumento4 pagineME345 Professor John M. Cimbala: The True Temperature of The Ice Bath Is 0.0000 Crahmid fareziNessuna valutazione finora
- Dwnload Full Statistics For People Who Think They Hate Statistics 7Th Edition PDFDocumento41 pagineDwnload Full Statistics For People Who Think They Hate Statistics 7Th Edition PDFkimberly.maxwell35595% (21)
- Educ 4 Part 3 Utilization of Assessment Data: CB - CBDocumento6 pagineEduc 4 Part 3 Utilization of Assessment Data: CB - CBKhemme Lapor Chu UbialNessuna valutazione finora
- Limited Depenedt Variable Models and Sample Selection CorrectionsDocumento62 pagineLimited Depenedt Variable Models and Sample Selection CorrectionsAqina SoaresNessuna valutazione finora
- EXAMPLESDocumento342 pagineEXAMPLESBerthony Cerrón YarangaNessuna valutazione finora
- Lesson 8-9 ActivityDocumento18 pagineLesson 8-9 ActivitypotsuNessuna valutazione finora
- Meta Analysis FormulaDocumento16 pagineMeta Analysis Formulachoijohnyxz499Nessuna valutazione finora
- AA7004P - MGT 780 - (EXERCISE 4) Forecasting QUESTION (5-33) A Major Source of Revenue in Texas Is A State Sales Tax On Certain Types of Goods andDocumento18 pagineAA7004P - MGT 780 - (EXERCISE 4) Forecasting QUESTION (5-33) A Major Source of Revenue in Texas Is A State Sales Tax On Certain Types of Goods andAmit BhaskarNessuna valutazione finora
- 21cs54 Tie SimpDocumento5 pagine21cs54 Tie Simprockyv9964Nessuna valutazione finora
- Homogeneity Tests On Daily Rainfall Series in Peninsular MalaysiaDocumento15 pagineHomogeneity Tests On Daily Rainfall Series in Peninsular MalaysiaakhmadfadholiNessuna valutazione finora
- 16 Confidence Interval-1Documento33 pagine16 Confidence Interval-1Online IncomeNessuna valutazione finora
- Quiz 2 Review Questions-1Documento3 pagineQuiz 2 Review Questions-1Steven NguyenNessuna valutazione finora