Potrebbero piacerti anche
- Manual de PowerPivotDocumento155 pagineManual de PowerPivotcayala_284538100% (15)
- Pasos para Elaborar Una Sesión TRECDocumento12 paginePasos para Elaborar Una Sesión TRECElias100% (4)
- Gramática. Thelma Sullivan.Documento407 pagineGramática. Thelma Sullivan.German Gonzalez100% (1)
- SQL Server 2014 Implementación de Una Solución de Business Intelligence (SQL Server, Analysis Services, Power BI... )Documento14 pagineSQL Server 2014 Implementación de Una Solución de Business Intelligence (SQL Server, Analysis Services, Power BI... )rodrigo_leonzNessuna valutazione finora
- Sincronización 5.7L HEMIDocumento10 pagineSincronización 5.7L HEMIEduardoCastilloNessuna valutazione finora
- SQL Server Reporting Services en Espanol PDFDocumento234 pagineSQL Server Reporting Services en Espanol PDFmanuelj_sanchezr100% (1)
- Evaluacion de PoliticasDocumento368 pagineEvaluacion de PoliticasAdrian Galindo CastroNessuna valutazione finora
- La Contabilidad de Costos y El Registro Contable de Proceso ProductivoDocumento20 pagineLa Contabilidad de Costos y El Registro Contable de Proceso ProductivovanessaNessuna valutazione finora
- Ensayo de Pensamiento PedagogicoDocumento4 pagineEnsayo de Pensamiento Pedagogicomilagro rincon50% (2)
- Cuaderno de Trabajo 31 GConocimiento Capital HumanoDocumento115 pagineCuaderno de Trabajo 31 GConocimiento Capital HumanoAnonymous bnbMQmp100% (1)
- 1 Diapostiva Generalidades WawaredDocumento16 pagine1 Diapostiva Generalidades Wawaredmanuelj_sanchezr100% (1)
- Prototipo de Sistema para Seguimiento de Objetos Con Visión ArtificialDocumento107 paginePrototipo de Sistema para Seguimiento de Objetos Con Visión Artificialmanuelj_sanchezrNessuna valutazione finora
- PyObia - Modulo de Segmentacion y Caracterizaacion de Imagines de Saletile - TFC - BOUDRIIYA - EL - HANDRIS - MOHAMMED - SALIMDocumento115 paginePyObia - Modulo de Segmentacion y Caracterizaacion de Imagines de Saletile - TFC - BOUDRIIYA - EL - HANDRIS - MOHAMMED - SALIMmanuelj_sanchezrNessuna valutazione finora
- Recorrido WawaredDocumento15 pagineRecorrido Wawaredmanuelj_sanchezrNessuna valutazione finora
- Ley Universitaria PDFDocumento35 pagineLey Universitaria PDFMarlon Aguilar GomezNessuna valutazione finora
- Cap 008Documento28 pagineCap 008manuelj_sanchezrNessuna valutazione finora
- 15 Lalingsticacognitiva AnlisisyrevisinDocumento177 pagine15 Lalingsticacognitiva AnlisisyrevisinlucasNessuna valutazione finora
- Estadísticas descriptivasDocumento143 pagineEstadísticas descriptivasmanuelj_sanchezrNessuna valutazione finora
- Esta Di SticaDocumento2 pagineEsta Di Sticamanuelj_sanchezrNessuna valutazione finora
- Modelos de Ecuaciones Estructurales PDFDocumento13 pagineModelos de Ecuaciones Estructurales PDFGiulianaNessuna valutazione finora
- Manual General HISDocumento15 pagineManual General HIScchiclotesNessuna valutazione finora
- LibroDocumento70 pagineLibroGreeisi Pilar Herrera CumbiaNessuna valutazione finora
- ArticuloDocumento3 pagineArticulomanuelj_sanchezrNessuna valutazione finora
- Casas Herrer Eduardo - La Red OscuraDocumento253 pagineCasas Herrer Eduardo - La Red OscuraTPH ONLINENessuna valutazione finora
- Mini Manual SQLServerDocumento10 pagineMini Manual SQLServerZuper Boy XzbNessuna valutazione finora
- Población 2017Documento138 paginePoblación 2017manuelj_sanchezrNessuna valutazione finora
- 4 Diapositiva PracticaDocumento1 pagina4 Diapositiva Practicamanuelj_sanchezrNessuna valutazione finora
- Manual General HISDocumento15 pagineManual General HIScchiclotesNessuna valutazione finora
- Diagnostica Medicam Guia MetodologicaDocumento13 pagineDiagnostica Medicam Guia Metodologicamanuelj_sanchezrNessuna valutazione finora
- Resultados de Padron NominalDocumento6 pagineResultados de Padron Nominalmanuelj_sanchezrNessuna valutazione finora
- Libro 1 CAF Capacidades Version WEB-RGB (Protect)Documento412 pagineLibro 1 CAF Capacidades Version WEB-RGB (Protect)manuelj_sanchezrNessuna valutazione finora
- Desarrollo Institucional y ConflictoDocumento392 pagineDesarrollo Institucional y Conflictomanuelj_sanchezrNessuna valutazione finora
- Farmacias InclusivasDocumento2 pagineFarmacias Inclusivasmanuelj_sanchezrNessuna valutazione finora
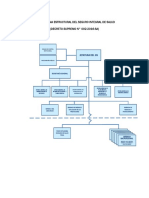
- Organ I Grama 2016Documento1 paginaOrgan I Grama 2016manuelj_sanchezrNessuna valutazione finora
- Alimentacion Del Ganado para Fincas Campesinas PDFDocumento15 pagineAlimentacion Del Ganado para Fincas Campesinas PDFGina MendozaNessuna valutazione finora
- Productos Relacionados: Ibanez SRMD205-SPNDocumento1 paginaProductos Relacionados: Ibanez SRMD205-SPNJuan Clemente Hernandez DelgadoNessuna valutazione finora
- TP Final AntarDocumento9 pagineTP Final AntarmicaelaNessuna valutazione finora
- Guía U1 - U2 Expresión ArtísticaDocumento3 pagineGuía U1 - U2 Expresión ArtísticaDANIELA GONZALEZ RUIZNessuna valutazione finora
- 1 - Libro Titulos Valores - Parte 1 Hasta Pág 31 PDFDocumento26 pagine1 - Libro Titulos Valores - Parte 1 Hasta Pág 31 PDFMaJo Sancheez100% (1)
- 1Documento386 pagine1JoseSantizRuizNessuna valutazione finora
- Purin en RabanoDocumento10 paginePurin en RabanoMike MillaNessuna valutazione finora
- Resistencia y Durabilidad Del Concreto Que Contiene Aridos de Concreto TrituradoDocumento2 pagineResistencia y Durabilidad Del Concreto Que Contiene Aridos de Concreto TrituradoIsaacJorgeRiveraLopeNessuna valutazione finora
- Liderazgo Ps OrganizacionalDocumento5 pagineLiderazgo Ps OrganizacionalTania NuñezNessuna valutazione finora
- Remoción Selectiva de Tejido Cariado en La Dentición Temporal Y Permanente JovenDocumento8 pagineRemoción Selectiva de Tejido Cariado en La Dentición Temporal Y Permanente JovengarciadeluisaNessuna valutazione finora
- Edna Marcela Vera Diaz Actividad2.2 EnsayoDocumento7 pagineEdna Marcela Vera Diaz Actividad2.2 EnsayoMarcela VeraNessuna valutazione finora
- Estructura Del Plan de Selección de PersonalDocumento3 pagineEstructura Del Plan de Selección de PersonalJULI SHARMELY CRUZ ZANABRIANessuna valutazione finora
- Corrección neuropsicológica de alteraciones visoespaciales y su impacto en el aprendizajeDocumento11 pagineCorrección neuropsicológica de alteraciones visoespaciales y su impacto en el aprendizajesamsoto86Nessuna valutazione finora
- PultrusiónDocumento8 paginePultrusiónDaniel VelázquezNessuna valutazione finora
- Informe de ReligionDocumento5 pagineInforme de ReligionJair MontañoNessuna valutazione finora
- Acido Cromico PDFDocumento2 pagineAcido Cromico PDFMagaly RojasNessuna valutazione finora
- T.N.O. Edición No.2Documento60 pagineT.N.O. Edición No.2Tamaulipas Nuestro OrgulloNessuna valutazione finora
- Guia de Práctica 2Documento14 pagineGuia de Práctica 2Mela MelaniaNessuna valutazione finora
- Diferendo marítimo Perú-Chile: antecedentes e historia de la controversiaDocumento19 pagineDiferendo marítimo Perú-Chile: antecedentes e historia de la controversiaCB ChuquizutaNessuna valutazione finora
- 06 Plan 6to Grado - Bloque 5 DosificaciónDocumento76 pagine06 Plan 6to Grado - Bloque 5 DosificaciónErwiin DiazNessuna valutazione finora
- Carlos Seguel TareaS8Documento5 pagineCarlos Seguel TareaS8carlosNessuna valutazione finora
- Recibo de Nomina: Hospitality Services Maya Sa de CVDocumento1 paginaRecibo de Nomina: Hospitality Services Maya Sa de CValfra14septiembreNessuna valutazione finora
- Fundamentosdeadministracin4ed RamirezCRamirezMP2016Documento24 pagineFundamentosdeadministracin4ed RamirezCRamirezMP2016Jimena GalvanNessuna valutazione finora
- SyllabusDocumento10 pagineSyllabusJose Elias Padilla AbadieNessuna valutazione finora
- Presentación Direccion EstrategicaDocumento6 paginePresentación Direccion EstrategicaCindy Paola Pargas De FreitasNessuna valutazione finora