Potrebbero piacerti anche
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- 2020sp93050 SESAPZG527 Solve PDFDocumento10 pagine2020sp93050 SESAPZG527 Solve PDFSayantan PalNessuna valutazione finora
- Interaction DiagramDocumento2 pagineInteraction DiagramSayantan PalNessuna valutazione finora
- LT104 PresentationDocumento28 pagineLT104 PresentationSayantan PalNessuna valutazione finora
- Principles of Artificial Intelligence: Printed BookDocumento1 paginaPrinciples of Artificial Intelligence: Printed BookSayantan PalNessuna valutazione finora
- NAT WBUT (MAKAUT) Short NoteDocumento3 pagineNAT WBUT (MAKAUT) Short NoteSayantan PalNessuna valutazione finora
- BGM@ 9DB 9? 7 89: No Fbo VKW: 3$IBDJKL 7 at @ :BDB (D DEB 9MD G9D7 (9@ at Q 9?: : ?@ 9: Debg / O Q MsDocumento3 pagineBGM@ 9DB 9? 7 89: No Fbo VKW: 3$IBDJKL 7 at @ :BDB (D DEB 9MD G9D7 (9@ at Q 9?: : ?@ 9: Debg / O Q MsSayantan PalNessuna valutazione finora
- Global TerrorismDocumento18 pagineGlobal TerrorismSayantan PalNessuna valutazione finora
- Tcs Pattern Refer This To Get 5 To 7 Questions From This (Study at Your Own Risk)Documento16 pagineTcs Pattern Refer This To Get 5 To 7 Questions From This (Study at Your Own Risk)Sayantan PalNessuna valutazione finora
- LL1 ParsingExamplesDocumento11 pagineLL1 ParsingExamplesSayantan PalNessuna valutazione finora
- Volume - I20.11.12 PDFDocumento297 pagineVolume - I20.11.12 PDFSayantan PalNessuna valutazione finora
- All India Coding Contest 2019Documento4 pagineAll India Coding Contest 2019Sayantan PalNessuna valutazione finora
- VerbalDocumento35 pagineVerbalSayantan PalNessuna valutazione finora
- Java - Chocolate Distribution in A School - Code Review Stack Exchange PDFDocumento4 pagineJava - Chocolate Distribution in A School - Code Review Stack Exchange PDFSayantan PalNessuna valutazione finora
- Final Probable Answers of Following Tricky PassagesDocumento2 pagineFinal Probable Answers of Following Tricky PassagesSayantan PalNessuna valutazione finora
- Notice CTS PDFDocumento1 paginaNotice CTS PDFSayantan PalNessuna valutazione finora
- Particle Swarm Optimization (PSO) - NEWDocumento18 pagineParticle Swarm Optimization (PSO) - NEWSayantan PalNessuna valutazione finora
- Output Screenshots (Unix Distribution Linux Mint Desktop Evironment)Documento4 pagineOutput Screenshots (Unix Distribution Linux Mint Desktop Evironment)Sayantan PalNessuna valutazione finora
- Barcode and QR Code Scanner Using ZBar and OpenCV - Learn OpenCVDocumento8 pagineBarcode and QR Code Scanner Using ZBar and OpenCV - Learn OpenCVSayantan PalNessuna valutazione finora
- C FunctionsDocumento48 pagineC FunctionsSayantan PalNessuna valutazione finora
- Assignment-3 11500116044Documento16 pagineAssignment-3 11500116044Sayantan PalNessuna valutazione finora
- Question BankDocumento1 paginaQuestion BankSayantan PalNessuna valutazione finora
- Running Environment - Linuxmint: Basic Shell Programming (Using Bash .SH Command at Terminal)Documento5 pagineRunning Environment - Linuxmint: Basic Shell Programming (Using Bash .SH Command at Terminal)Sayantan PalNessuna valutazione finora
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Chapter 3Documento36 pagineChapter 3Josh 14Nessuna valutazione finora
- Inception Is Not The Requirements Phase: Applying UML and Patterns Craig LarmanDocumento32 pagineInception Is Not The Requirements Phase: Applying UML and Patterns Craig LarmanAnum KhawajaNessuna valutazione finora
- DARRYL CROPPER Current Resume August2020SHCDocumento8 pagineDARRYL CROPPER Current Resume August2020SHCRajan GuptaNessuna valutazione finora
- "Patel 908-428-5357 " Sr. Business Analyst Professional SummaryDocumento5 pagine"Patel 908-428-5357 " Sr. Business Analyst Professional SummaryJay ReddyNessuna valutazione finora
- Task 1 - BCM Method - Guide V5e FinalDocumento86 pagineTask 1 - BCM Method - Guide V5e Finalilumezianu100% (1)
- ISTQB Certified Tester Foundation Level: - Module 4 of 6: Test Design TechniquesDocumento81 pagineISTQB Certified Tester Foundation Level: - Module 4 of 6: Test Design TechniquesSantosh Rathod100% (1)
- Employee Management System For ASTUDocumento76 pagineEmployee Management System For ASTULungileNessuna valutazione finora
- SE Lab 09 - UpdatedDocumento6 pagineSE Lab 09 - UpdatedAbdulelahNessuna valutazione finora
- RequerimientosDocumento336 pagineRequerimientosKaren GmNessuna valutazione finora
- Online Registration System: Problem StatementDocumento8 pagineOnline Registration System: Problem StatementPrasad BanothNessuna valutazione finora
- BC0057Documento7 pagineBC0057RaviKumarNessuna valutazione finora
- Software Requirements Specification For: Social Networking SiteDocumento20 pagineSoftware Requirements Specification For: Social Networking Sitechuck1993Nessuna valutazione finora
- "Time Table Management System": Project Report OnDocumento24 pagine"Time Table Management System": Project Report OnNITIN RAJ75% (8)
- MuleSoft - Design Best PracticesDocumento20 pagineMuleSoft - Design Best Practicessaikrishnatadiboyina100% (1)
- Fundamentals of Software Engineering PDFDocumento2 pagineFundamentals of Software Engineering PDFBetsegaw Demeke100% (1)
- Amazon Web Services: ProjectDocumento13 pagineAmazon Web Services: ProjectAneelaMalikNessuna valutazione finora
- Unit 1 OoadDocumento104 pagineUnit 1 OoadganeshNessuna valutazione finora
- Questions 1Documento3 pagineQuestions 1dragosNessuna valutazione finora
- 1.1 Problem Definition: Ace Engineering CollegeDocumento54 pagine1.1 Problem Definition: Ace Engineering CollegeUrvik PatelNessuna valutazione finora
- Free CBAP Exam QuestionsDocumento9 pagineFree CBAP Exam QuestionsTechcanvassNessuna valutazione finora
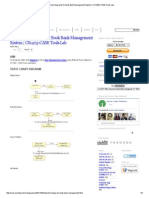
- State Chart Diagrams For Book Bank Management System - CS1403-CASE Tools LabDocumento3 pagineState Chart Diagrams For Book Bank Management System - CS1403-CASE Tools Labanupam20099Nessuna valutazione finora
- Requirement ElicitationDocumento6 pagineRequirement ElicitationJitesh Emmanuel100% (1)
- Session 10 and 11Documento143 pagineSession 10 and 11KuldeepSinghDeoraNessuna valutazione finora
- Mark AnalyseDocumento18 pagineMark AnalysedarbarNessuna valutazione finora
- Proposed Business State: ID RequirementsDocumento4 pagineProposed Business State: ID RequirementsCOMACO DATANessuna valutazione finora
- CI7350 - Assessment 2 - CW Brief 22-23 PDFDocumento5 pagineCI7350 - Assessment 2 - CW Brief 22-23 PDFJohn DavidNessuna valutazione finora
- Effort Estimation TechniquesDocumento18 pagineEffort Estimation TechniquesSANKARA TEJA CSE-2017-21Nessuna valutazione finora
- BIS3003 - Assessment Brief T3, 2021Documento20 pagineBIS3003 - Assessment Brief T3, 2021KushalNessuna valutazione finora
- Software Requirement Specifications: Hotel Management SystemDocumento8 pagineSoftware Requirement Specifications: Hotel Management SystemMinahilNessuna valutazione finora
- 6th Sem Lab ManualDocumento35 pagine6th Sem Lab ManualABHISHEK UPADHYAYNessuna valutazione finora