Potrebbero piacerti anche
- Tree Data StructureDocumento7 pagineTree Data Structuresel&nitNessuna valutazione finora
- Tree Data Structure: Design and Implementation inDocumento21 pagineTree Data Structure: Design and Implementation inAhmedRajputNessuna valutazione finora
- Graph TraversalsDocumento11 pagineGraph TraversalsAnandhaSilambarasan DNessuna valutazione finora
- Topological SortingDocumento8 pagineTopological SortingGeorge fernandez.INessuna valutazione finora
- Trees: 1/34 Data Structures and Algorithms in JavaDocumento34 pagineTrees: 1/34 Data Structures and Algorithms in JavaThịnh TrầnNessuna valutazione finora
- RecursionDocumento38 pagineRecursionanjugaduNessuna valutazione finora
- Modern Web Applications with Next.JS: Learn Advanced Techniques to Build and Deploy Modern, Scalable and Production Ready React Applications with Next.JSDa EverandModern Web Applications with Next.JS: Learn Advanced Techniques to Build and Deploy Modern, Scalable and Production Ready React Applications with Next.JSNessuna valutazione finora
- Ds MaterialDocumento61 pagineDs MaterialSai RamNessuna valutazione finora
- Chapter 9 ArrayDocumento32 pagineChapter 9 ArrayIsse EssiNessuna valutazione finora
- DS Viva QuestionsDocumento6 pagineDS Viva QuestionsDaniel MariadassNessuna valutazione finora
- Merge SortDocumento15 pagineMerge Sortapi-3825559Nessuna valutazione finora
- Computer Notes PDFDocumento49 pagineComputer Notes PDFLorbie Castañeda FrigillanoNessuna valutazione finora
- Data Structure Viva QuestionsDocumento9 pagineData Structure Viva Questionsirfanahmed.dba@gmail.comNessuna valutazione finora
- CS218-Data Structures Final ExamDocumento7 pagineCS218-Data Structures Final ExamRafayGhafoorNessuna valutazione finora
- Big O Algorithm Complexity Cheat SheetDocumento3 pagineBig O Algorithm Complexity Cheat SheetShreyans Pathak100% (1)
- Memory ManagementDocumento33 pagineMemory ManagementlalithaNessuna valutazione finora
- GraphsDocumento3 pagineGraphsRajesh KumarNessuna valutazione finora
- CS 2420 Program 2 - 24 Points Due Fall 2013 Fun With RecursionDocumento4 pagineCS 2420 Program 2 - 24 Points Due Fall 2013 Fun With Recursionishu gargNessuna valutazione finora
- Data Structures Viva QuestionsDocumento8 pagineData Structures Viva QuestionslokiblazerNessuna valutazione finora
- CS1201 Data StructuresDocumento4 pagineCS1201 Data StructuressureshNessuna valutazione finora
- Softathalon Interview QuestionsDocumento11 pagineSoftathalon Interview QuestionsShakshi AgrawalNessuna valutazione finora
- Single Linked ListDocumento11 pagineSingle Linked Listlakshmi.sNessuna valutazione finora
- Data Structure Compiled NoteDocumento53 pagineData Structure Compiled NoteamanuelNessuna valutazione finora
- Arsdigita University Month 8: Theory of Computation Professor Shai Simonson Exam 1 (50 Points)Documento5 pagineArsdigita University Month 8: Theory of Computation Professor Shai Simonson Exam 1 (50 Points)brightstudentNessuna valutazione finora
- PPT On Data StructuresDocumento54 paginePPT On Data Structuresshyma naNessuna valutazione finora
- File Organization in DBMSDocumento23 pagineFile Organization in DBMSsunny sarwara100% (1)
- Classical IPC ProblemsDocumento15 pagineClassical IPC ProblemsFariha Nuzhat MajumdarNessuna valutazione finora
- Red Black Tree MaterialDocumento5 pagineRed Black Tree MaterialAvinash AllaNessuna valutazione finora
- Unit Wise QuestionDocumento2 pagineUnit Wise QuestionMohit SainiNessuna valutazione finora
- Recursion in C: #IncludeDocumento2 pagineRecursion in C: #IncludeDr. T. Veeramakali CSE-STAFFNessuna valutazione finora
- Data Structure Full NotesDocumento72 pagineData Structure Full NotesSuper Hit MoviesNessuna valutazione finora
- Unit 1 - Data Structure - WWW - Rgpvnotes.inDocumento8 pagineUnit 1 - Data Structure - WWW - Rgpvnotes.inAtul Singh YadavNessuna valutazione finora
- 4 Arrays in 'C'Documento19 pagine4 Arrays in 'C'api-3728136100% (10)
- Introduction To Computer Programming ProgrammingDocumento54 pagineIntroduction To Computer Programming ProgrammingSushma VermaNessuna valutazione finora
- Data Structures With C LabDocumento40 pagineData Structures With C LabPradeep Gowda100% (2)
- C Programming EbookDocumento383 pagineC Programming Ebookadci2Nessuna valutazione finora
- C Lab ManualDocumento16 pagineC Lab ManualAnamika T AnilNessuna valutazione finora
- Dsa Viva QuestionsDocumento18 pagineDsa Viva QuestionsSwarali UtekarNessuna valutazione finora
- C Language BasicsDocumento61 pagineC Language Basicsinfotainment100% (1)
- Data Structure Questions BankDocumento30 pagineData Structure Questions BankRj SahooNessuna valutazione finora
- COADocumento137 pagineCOAThonta DariNessuna valutazione finora
- Q.1 Fill in The Blanks:: (Ch#13) Functions Computer Science Part-IIDocumento14 pagineQ.1 Fill in The Blanks:: (Ch#13) Functions Computer Science Part-IIhammad harisNessuna valutazione finora
- A719552767 - 20992 - 7 - 2019 - Lecture10 Python OOPDocumento15 pagineA719552767 - 20992 - 7 - 2019 - Lecture10 Python OOPrahulNessuna valutazione finora
- C++ NotesDocumento7 pagineC++ NoteskumuthaNessuna valutazione finora
- 6 OOP Concepts in Java With ExamplesDocumento15 pagine6 OOP Concepts in Java With Examplesheyraj@gmail.comNessuna valutazione finora
- OOP - Java - Session 1Documento44 pagineOOP - Java - Session 1gauravlkoNessuna valutazione finora
- Ds Lecture NotesDocumento131 pagineDs Lecture Notessrushti mahaleNessuna valutazione finora
- Introduction To C LanguageDocumento9 pagineIntroduction To C LanguagekalaivaniNessuna valutazione finora
- Design of Control UnitDocumento19 pagineDesign of Control UnitArjun Nain100% (1)
- Principles of Operating System Questions and AnswersDocumento15 paginePrinciples of Operating System Questions and Answerskumar nikhilNessuna valutazione finora
- Data Structure and AlgorithmDocumento12 pagineData Structure and Algorithmleah pileoNessuna valutazione finora
- Unit-3 Part - 1Documento37 pagineUnit-3 Part - 1Bandi SirishaNessuna valutazione finora
- I B.SC CS DS Unit IiiDocumento26 pagineI B.SC CS DS Unit Iiiarkaruns_858818340Nessuna valutazione finora
- Data Structure Module 4Documento25 pagineData Structure Module 4ssreeram1312.tempNessuna valutazione finora
- Buet Admission About TreeDocumento26 pagineBuet Admission About TreeOporajitaNessuna valutazione finora
- DSC Mod4Documento21 pagineDSC Mod4Sai DeekshaRNessuna valutazione finora
- Binary TreesDocumento52 pagineBinary TreesG.ChinmayiNessuna valutazione finora
- TreesDocumento125 pagineTreesHarsimran KaurNessuna valutazione finora
- Tree TerminologiesDocumento12 pagineTree TerminologiesSobia BatoolNessuna valutazione finora
- UNIT VtreesDocumento27 pagineUNIT VtreesParashuramBannigidadNessuna valutazione finora
- 1 To 10 DSA 22dce099Documento59 pagine1 To 10 DSA 22dce09922dce099Nessuna valutazione finora
- B+ TreeDocumento5 pagineB+ Treeprut.joshNessuna valutazione finora
- Data Structures Implementation Using C++Documento54 pagineData Structures Implementation Using C++Gagandeep SinghNessuna valutazione finora
- Of Engineering & Technology, Coimbatore of Engineering & Technology, CoimbatoreDocumento1 paginaOf Engineering & Technology, Coimbatore of Engineering & Technology, CoimbatoreNithya SubramanianNessuna valutazione finora
- Transform and Conquer PDFDocumento39 pagineTransform and Conquer PDFFyyrreeNessuna valutazione finora
- B+ Tree RulesDocumento9 pagineB+ Tree RulesPavan Kumar GajavalliNessuna valutazione finora
- Comp 2123 NotesDocumento16 pagineComp 2123 Notesmaxharper26Nessuna valutazione finora
- Linkedlist QuestionsDocumento36 pagineLinkedlist QuestionsoasisdesertNessuna valutazione finora
- Binary Search TreeDocumento17 pagineBinary Search Treeگل گلابNessuna valutazione finora
- AVL Trees: Presentation For Use With The Textbook, by M. T. Goodrich and R. Tamassia, Wiley, 2015Documento14 pagineAVL Trees: Presentation For Use With The Textbook, by M. T. Goodrich and R. Tamassia, Wiley, 2015Keita AmanoNessuna valutazione finora
- Question Bank Subject: CS8391 - Data Structures Sem / Year: Iii Sem/ Ii Year UnitiDocumento3 pagineQuestion Bank Subject: CS8391 - Data Structures Sem / Year: Iii Sem/ Ii Year Uniti5052 - UTHRA .TNessuna valutazione finora
- Multidimensional Search TreesDocumento119 pagineMultidimensional Search TreesrajeswarikannanNessuna valutazione finora
- AVL Trees: Version of September 6, 2016Documento22 pagineAVL Trees: Version of September 6, 2016HIRAN KUMAR SINHANessuna valutazione finora
- Tree Data Structure SlidesDocumento7 pagineTree Data Structure SlidesArshad KhalidNessuna valutazione finora
- Binary Search Tree NotesDocumento7 pagineBinary Search Tree NotesNandana BobanNessuna valutazione finora
- MCQDocumento12 pagineMCQvrushali patilNessuna valutazione finora
- CS301 Finalterm Subjective 2013 Solved - 2Documento16 pagineCS301 Finalterm Subjective 2013 Solved - 2Network Bull100% (2)
- DSADDocumento2 pagineDSADbhavana2264Nessuna valutazione finora
- UNITwiseUniversityQuestion Bank - StudentsDocumento12 pagineUNITwiseUniversityQuestion Bank - StudentsHarshad LokhandeNessuna valutazione finora
- Data Structures Using C++ Lab - Record - II A - Dec 2020Documento68 pagineData Structures Using C++ Lab - Record - II A - Dec 2020SaravananNessuna valutazione finora
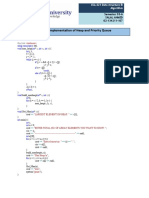
- Lab 11: Implementation of Heap and Priority QueueDocumento3 pagineLab 11: Implementation of Heap and Priority QueuenasirqureshiNessuna valutazione finora
- Big-O Algorithm Complexity Cheat SheetDocumento4 pagineBig-O Algorithm Complexity Cheat SheetPravind KumarNessuna valutazione finora
- Lecture No.12 Data Structures: Dr. Sohail AslamDocumento47 pagineLecture No.12 Data Structures: Dr. Sohail AslamM NOOR MALIKNessuna valutazione finora
- Quicksort On Singly Linked List 14. Iterative Quick Sort 15. Merge Sort For Linked ListDocumento21 pagineQuicksort On Singly Linked List 14. Iterative Quick Sort 15. Merge Sort For Linked ListPRE-GAMERS INC.Nessuna valutazione finora
- Data Structures Algorithms U2Documento92 pagineData Structures Algorithms U2Tan Wei SengNessuna valutazione finora
- k1 (First Node in k2's Left Subtree) Will Be The New Root Y Moves From k1's Right To k2's LeftDocumento36 paginek1 (First Node in k2's Left Subtree) Will Be The New Root Y Moves From k1's Right To k2's LeftM NOOR MALIKNessuna valutazione finora
- Data Structure Exam Sample - 2020Documento12 pagineData Structure Exam Sample - 2020Rewina zerouNessuna valutazione finora
- DBMS - File Organization, Indexing and Hashing NotesDocumento19 pagineDBMS - File Organization, Indexing and Hashing NotesKomal RamtekeNessuna valutazione finora
- Implementation of Queue Using ArrayDocumento42 pagineImplementation of Queue Using Arrayrsgk100% (1)