Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1091)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Chapter 2 Practice AnswersDocumento4 pagineChapter 2 Practice AnswersZeyad Moustafa100% (1)
- Write A Program To Obtain The Topological Ordering of Vertices in A Given DigraphDocumento11 pagineWrite A Program To Obtain The Topological Ordering of Vertices in A Given DigraphGuru GuruNessuna valutazione finora
- Notation For Differentiation - WikipediaDocumento11 pagineNotation For Differentiation - WikipediaTibor VéghNessuna valutazione finora
- Image Quality Assessment of Computer-Generated Images Based On Machine Learning and Soft ComputingDocumento96 pagineImage Quality Assessment of Computer-Generated Images Based On Machine Learning and Soft ComputingRepair CenterNessuna valutazione finora
- Week 2Documento6 pagineWeek 2ROMY JOHN SALVACION BONTANONNessuna valutazione finora
- 2010 KPI Milestone Chart 07 08 09Documento21 pagine2010 KPI Milestone Chart 07 08 09Abas AsmanNessuna valutazione finora
- S3 Ch7 Introduction To Probability QDocumento17 pagineS3 Ch7 Introduction To Probability QF2D 10 FUNG SZE HANGNessuna valutazione finora
- Flight Vehicle LoadsDocumento15 pagineFlight Vehicle LoadsSantosh G Pattanad100% (1)
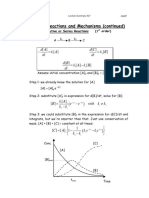
- Consecutive, Series, and Reversible ReactionsDocumento6 pagineConsecutive, Series, and Reversible ReactionsRojo JohnNessuna valutazione finora
- Gretl Ref A4 PDFDocumento226 pagineGretl Ref A4 PDFDianaNessuna valutazione finora
- The Real Number SystemDocumento17 pagineThe Real Number SystemAkia AlexisNessuna valutazione finora
- 3.5 Inverse Trig FunctionsDocumento6 pagine3.5 Inverse Trig FunctionsZazliana Izatti100% (1)
- Tugas English For Math 01Documento4 pagineTugas English For Math 01Danny KusumaNessuna valutazione finora
- Guidelines For Prioritizing Inspections of Aging Plant InfrastructureDocumento100 pagineGuidelines For Prioritizing Inspections of Aging Plant Infrastructurethabiso87100% (2)
- Lesson Plan NBA-Operations ResearchDocumento19 pagineLesson Plan NBA-Operations ResearchsunilmeNessuna valutazione finora
- Engineering StructuresDocumento17 pagineEngineering StructuresJc Medina DonnelliNessuna valutazione finora
- Composition and Resolution of Forces and Condition of Equilibrium of ForcesDocumento13 pagineComposition and Resolution of Forces and Condition of Equilibrium of Forcesdevli falduNessuna valutazione finora
- Engineering Mathematics IIDocumento102 pagineEngineering Mathematics IIIsaac P PlanNessuna valutazione finora
- Fuel 85 (2006) 910-917 WWW - FuelDocumento8 pagineFuel 85 (2006) 910-917 WWW - Fuelmohammed saberNessuna valutazione finora
- Math Solution ManualDocumento46 pagineMath Solution ManualEdzae LilioNessuna valutazione finora
- MCQ'S Engineering Mathematics-II: Differential EquationDocumento21 pagineMCQ'S Engineering Mathematics-II: Differential EquationDurga JoshiNessuna valutazione finora
- 3 - 2 Logarithmic FNS and Their Graphs PDFDocumento29 pagine3 - 2 Logarithmic FNS and Their Graphs PDFAikaterine Simbajon GabisayNessuna valutazione finora
- Testing HypothesisDocumento11 pagineTesting HypothesisSaif KamalNessuna valutazione finora
- Unit 4: Relational Database DesignDocumento19 pagineUnit 4: Relational Database DesignYesudasNessuna valutazione finora
- Topic 3 Tape CorrectionsDocumento38 pagineTopic 3 Tape CorrectionsShaine GaleraNessuna valutazione finora
- Calculation of The Equivalent Resistance and Impedance of The Cylindrical Network Based On Recursion-Transform MethodDocumento12 pagineCalculation of The Equivalent Resistance and Impedance of The Cylindrical Network Based On Recursion-Transform Methodmark_990566444Nessuna valutazione finora
- Ieee TJ Template 17Documento9 pagineIeee TJ Template 17Henry Lois Davila AndradeNessuna valutazione finora
- Introduction To Data StructureDocumento205 pagineIntroduction To Data Structurehim1234567890Nessuna valutazione finora
- Disk Scheduling AlgorithmsDocumento3 pagineDisk Scheduling AlgorithmsAsh hmmmNessuna valutazione finora