Potrebbero piacerti anche
- Base SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesDa EverandBase SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNessuna valutazione finora
- Array Data Structure Lect-3Documento16 pagineArray Data Structure Lect-3Tanmay BaranwalNessuna valutazione finora
- Performance Analysis of Decision Tree ClassifiersDocumento9 paginePerformance Analysis of Decision Tree ClassifiersEighthSenseGroupNessuna valutazione finora
- Unit 2 FodDocumento27 pagineUnit 2 Fodit hodNessuna valutazione finora
- R Language 1st Unit DeepDocumento61 pagineR Language 1st Unit DeepIt's Me100% (1)
- An R Tutorial Starting OutDocumento9 pagineAn R Tutorial Starting OutWendy WeiNessuna valutazione finora
- Chapter 2 Database Quiz Study GuideDocumento8 pagineChapter 2 Database Quiz Study GuideTyler Lee WittenNessuna valutazione finora
- 7.assignment2 DAA Answers Dsatm PDFDocumento19 pagine7.assignment2 DAA Answers Dsatm PDFM.A rajaNessuna valutazione finora
- CS301 Finalterm Subjective 2013 Solved - 2Documento16 pagineCS301 Finalterm Subjective 2013 Solved - 2Network Bull100% (2)
- COMPUTER GRAPHICS AREAS AND APPLICATIONSDocumento22 pagineCOMPUTER GRAPHICS AREAS AND APPLICATIONSJyuNessuna valutazione finora
- Unit3 FDSDocumento33 pagineUnit3 FDSOur Little NestNessuna valutazione finora
- Python LabDocumento27 paginePython LabPrajwal P GNessuna valutazione finora
- RDBMS Concepts and SQL Server IntroductionDocumento58 pagineRDBMS Concepts and SQL Server IntroductionHemanta Kumar Dash100% (1)
- MC0080 Analysis and Design of AlgorithmsDocumento15 pagineMC0080 Analysis and Design of AlgorithmsGaurav Singh JantwalNessuna valutazione finora
- Information Visualization: Dr. Parvathi.R VIT University, ChennaiDocumento73 pagineInformation Visualization: Dr. Parvathi.R VIT University, ChennaisaRIKANessuna valutazione finora
- Machine Learning Lab Assignment Using Weka Name:: Submitted ToDocumento15 pagineMachine Learning Lab Assignment Using Weka Name:: Submitted ToZobahaa HorunkuNessuna valutazione finora
- Topological Sort HomeworkDocumento5 pagineTopological Sort Homeworkabhi74Nessuna valutazione finora
- Data Types in PythonDocumento5 pagineData Types in PythonratheeshbrNessuna valutazione finora
- Dbms Aicte LabDocumento42 pagineDbms Aicte LabKaja AhmadNessuna valutazione finora
- Advanced Cluster Analysis: Clustering High-Dimensional DataDocumento49 pagineAdvanced Cluster Analysis: Clustering High-Dimensional DataPriyanka BhardwajNessuna valutazione finora
- RSTUDIODocumento44 pagineRSTUDIOsamarth agarwalNessuna valutazione finora
- Multimedia Mining PresentationDocumento18 pagineMultimedia Mining PresentationVivek NaragudeNessuna valutazione finora
- 1 IP 12 NOTES PythonPandas 2022 PDFDocumento66 pagine1 IP 12 NOTES PythonPandas 2022 PDFKrrish Kumar100% (3)
- 01 - The Role of Algorithms in ComputingDocumento22 pagine01 - The Role of Algorithms in ComputingHamna YounisNessuna valutazione finora
- R LnaguagerDocumento38 pagineR LnaguagerdwrreNessuna valutazione finora
- C Language BasicsDocumento61 pagineC Language BasicsinfotainmentNessuna valutazione finora
- Introduction To Machine Learning: K-Nearest Neighbor AlgorithmDocumento25 pagineIntroduction To Machine Learning: K-Nearest Neighbor AlgorithmAlwan SiddiqNessuna valutazione finora
- R Basics PDFDocumento10 pagineR Basics PDFSAILY JADHAVNessuna valutazione finora
- AI Problem SolvingDocumento55 pagineAI Problem SolvingRakeshNessuna valutazione finora
- Dept of Computer Science & Engineering LAB Manual For 2008 - 2009 (II - II) 1Documento80 pagineDept of Computer Science & Engineering LAB Manual For 2008 - 2009 (II - II) 1Sai Chaitanya VundrakondaNessuna valutazione finora
- Introduction To OOPS and C++Documento48 pagineIntroduction To OOPS and C++Pooja AnjaliNessuna valutazione finora
- Data Mining - IMT Nagpur-ManishDocumento82 pagineData Mining - IMT Nagpur-ManishSumeet GuptaNessuna valutazione finora
- Prolog ProgramsDocumento41 pagineProlog ProgramsJuhi BansalNessuna valutazione finora
- Merge SortDocumento15 pagineMerge Sortapi-3825559Nessuna valutazione finora
- COSC 3100 Brute Force and Exhaustive Search: Instructor: TanvirDocumento44 pagineCOSC 3100 Brute Force and Exhaustive Search: Instructor: TanvirPuneet MehtaNessuna valutazione finora
- List, Tuple, Set, DictionaryDocumento51 pagineList, Tuple, Set, DictionaryjosephramsingculanNessuna valutazione finora
- R Programming Practical File (1319036)Documento25 pagineR Programming Practical File (1319036)UtkarshNessuna valutazione finora
- ID3 AllanNeymarkDocumento22 pagineID3 AllanNeymarkRajesh KumarNessuna valutazione finora
- DBMS - Transactions ManagementDocumento40 pagineDBMS - Transactions ManagementhariNessuna valutazione finora
- Peer Review Assignment 4: InstructionsDocumento17 paginePeer Review Assignment 4: Instructionshamza omar100% (1)
- Basic PL-SQLDocumento47 pagineBasic PL-SQLTharsiya VijayakumarNessuna valutazione finora
- Data Mining and Business Intelligence Lab ManualDocumento52 pagineData Mining and Business Intelligence Lab ManualVinay JokareNessuna valutazione finora
- Rmarkdown Cheatsheet 2.0Documento2 pagineRmarkdown Cheatsheet 2.0Weid Davinio PanDuroNessuna valutazione finora
- DBMS Unit-1 PPT 1.1 (Introduction, Drawback of File Sysstem, View of Data)Documento4 pagineDBMS Unit-1 PPT 1.1 (Introduction, Drawback of File Sysstem, View of Data)lightNessuna valutazione finora
- Complexity of An Algorithm Lect-2.ppsDocumento21 pagineComplexity of An Algorithm Lect-2.ppsTanmay BaranwalNessuna valutazione finora
- Data Structures and Algorithms: Complexity Analysis/Algorithm AnalysisDocumento22 pagineData Structures and Algorithms: Complexity Analysis/Algorithm AnalysisMuhammad AmmarNessuna valutazione finora
- Data Mining Lab ManualDocumento2 pagineData Mining Lab Manualakbar2694Nessuna valutazione finora
- Data Mining HandoutDocumento4 pagineData Mining HandoutjasleenNessuna valutazione finora
- Introduction To Data MiningDocumento19 pagineIntroduction To Data MiningAyan ChakravortyNessuna valutazione finora
- Laboratory Exercises in Image Processing: Contrast Stretching TechniquesDocumento9 pagineLaboratory Exercises in Image Processing: Contrast Stretching TechniquesKaustav MitraNessuna valutazione finora
- Learn Recursion Concepts and TechniquesDocumento38 pagineLearn Recursion Concepts and TechniquesanjugaduNessuna valutazione finora
- 715ECT04 Embedded Systems 2M & 16MDocumento32 pagine715ECT04 Embedded Systems 2M & 16Msumathi0% (1)
- Python Generators Explained: How to Create and Use Generators in PythonDocumento8 paginePython Generators Explained: How to Create and Use Generators in PythonNaga Pradeep VeerisettyNessuna valutazione finora
- Relational Algebra CalculusDocumento40 pagineRelational Algebra CalculusMinh_Tran_7326100% (1)
- Ssad Notes-Ii BcaDocumento68 pagineSsad Notes-Ii Bcaraj kumarNessuna valutazione finora
- Lecture 02 Complexity AnalysisDocumento15 pagineLecture 02 Complexity AnalysisMuhammad AmmarNessuna valutazione finora
- Java InterfaceDocumento14 pagineJava InterfaceSR ChaudharyNessuna valutazione finora
- Graphics ProgrammingDocumento13 pagineGraphics Programmingkalia_prmlNessuna valutazione finora
- Structured programming Complete Self-Assessment GuideDa EverandStructured programming Complete Self-Assessment GuideNessuna valutazione finora
- Database Management Systems NotesDocumento195 pagineDatabase Management Systems NotesAltafAhmed2706Nessuna valutazione finora
- Unit 1Documento89 pagineUnit 1Ashok Kumar KumaresanNessuna valutazione finora
- Programming in C++ and Data Structures - 5Documento1 paginaProgramming in C++ and Data Structures - 5Karthikeyan RamajayamNessuna valutazione finora
- Syllabus JavaDocumento1 paginaSyllabus JavaKarthikeyan RamajayamNessuna valutazione finora
- Data Flow Diagra1Documento3 pagineData Flow Diagra1Karthikeyan RamajayamNessuna valutazione finora
- DMDocumento3 pagineDMKarthikeyan RamajayamNessuna valutazione finora
- What Is A Database Management SystemDocumento4 pagineWhat Is A Database Management SystemKarthikeyan RamajayamNessuna valutazione finora
- Programming in C++ and Data Structures - 2Documento1 paginaProgramming in C++ and Data Structures - 2Karthikeyan RamajayamNessuna valutazione finora
- Programming in C++ and Data Structures - 1Documento2 pagineProgramming in C++ and Data Structures - 1Karthikeyan RamajayamNessuna valutazione finora
- Multiplexing in Mobile ComputingDocumento5 pagineMultiplexing in Mobile ComputingKarthikeyan RamajayamNessuna valutazione finora
- Basic Arithmetic OperationsDocumento1 paginaBasic Arithmetic OperationsKarthikeyan RamajayamNessuna valutazione finora
- Example Program 2 - Adding User Numbers Program: Code When Btnadd Is ClickedDocumento2 pagineExample Program 2 - Adding User Numbers Program: Code When Btnadd Is ClickedKarthikeyan RamajayamNessuna valutazione finora
- Artificial Intelligence Notes PDFDocumento2 pagineArtificial Intelligence Notes PDFKarthikeyan Ramajayam100% (2)
- Basic Arithmetic FunctionsDocumento7 pagineBasic Arithmetic FunctionsKarthikeyan RamajayamNessuna valutazione finora
- Calculations With VectorsDocumento6 pagineCalculations With VectorsKarthikeyan RamajayamNessuna valutazione finora
- Example 4 - Finding The Average of Numbers in A ListDocumento2 pagineExample 4 - Finding The Average of Numbers in A ListKarthikeyan RamajayamNessuna valutazione finora
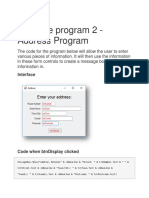
- Example Program 2 - Address Program: InterfaceDocumento6 pagineExample Program 2 - Address Program: InterfaceKarthikeyan RamajayamNessuna valutazione finora
- Iteration - Condition Controlled: WHILE LoopsDocumento3 pagineIteration - Condition Controlled: WHILE LoopsKarthikeyan RamajayamNessuna valutazione finora
- Example program checks capital city of England is LondonDocumento2 pagineExample program checks capital city of England is LondonKarthikeyan RamajayamNessuna valutazione finora
- Difference Between VB and VBDocumento2 pagineDifference Between VB and VBKarthikeyan RamajayamNessuna valutazione finora
- vb.netDocumento2 paginevb.netKarthikeyan RamajayamNessuna valutazione finora
- Example Program 1 VBDocumento2 pagineExample Program 1 VBKarthikeyan RamajayamNessuna valutazione finora
- Introduction To AspDocumento1 paginaIntroduction To AspKarthikeyan RamajayamNessuna valutazione finora
- Difference Between VB and VBDocumento2 pagineDifference Between VB and VBKarthikeyan RamajayamNessuna valutazione finora
- CLS Specification Ensures .NET InteroperabilityDocumento2 pagineCLS Specification Ensures .NET InteroperabilityKarthikeyan RamajayamNessuna valutazione finora
- Data Flow Diagra1Documento3 pagineData Flow Diagra1Karthikeyan RamajayamNessuna valutazione finora
- Introduction To AspDocumento1 paginaIntroduction To AspKarthikeyan RamajayamNessuna valutazione finora
- Keel User ManualDocumento26 pagineKeel User ManualKarthikeyan RamajayamNessuna valutazione finora
- Dot Net2Documento1 paginaDot Net2Karthikeyan RamajayamNessuna valutazione finora
- Switch Brocade 7250Documento128 pagineSwitch Brocade 7250Thanh Kieu TienNessuna valutazione finora
- RFP (FMS, Amc & CMC) DailDocumento16 pagineRFP (FMS, Amc & CMC) DailShaikh Saeed AlamNessuna valutazione finora
- Design Analysis of Water Distribution Network in Ilorin Using GIS and Hydraulic ModelingDocumento13 pagineDesign Analysis of Water Distribution Network in Ilorin Using GIS and Hydraulic ModelingAmbesaNessuna valutazione finora
- Aisya Nadya Damarcha: Pengantar Ilmu Komputer Cs IupDocumento4 pagineAisya Nadya Damarcha: Pengantar Ilmu Komputer Cs IupAisya Nadya DamarchaNessuna valutazione finora
- MetaheuristicDocumento8 pagineMetaheuristicjohn949Nessuna valutazione finora
- Project Management LeadershipDocumento24 pagineProject Management LeadershipYuanj ZenNessuna valutazione finora
- Getting Started With Data Governance: August 2008Documento12 pagineGetting Started With Data Governance: August 2008Ilán Antoni Horna GomezNessuna valutazione finora
- Guidance of Construction Sequence Simulation For VDC (Twinmotion)Documento26 pagineGuidance of Construction Sequence Simulation For VDC (Twinmotion)451081986Nessuna valutazione finora
- Session 1 M.I.S Class KoDocumento27 pagineSession 1 M.I.S Class KoRoland John MarzanNessuna valutazione finora
- Skripsi FatahDocumento66 pagineSkripsi FatahKhilmy AnjastiarNessuna valutazione finora
- Electropneumatic Positioner Mounting InstructionsDocumento44 pagineElectropneumatic Positioner Mounting InstructionsAji SarNessuna valutazione finora
- AirwayDocumento3.238 pagineAirwayNuno Filipe ÁlvaresNessuna valutazione finora
- Profile PDFDocumento16 pagineProfile PDFAndriGunawanSaputraNessuna valutazione finora
- Trio Mxtend: Up To Three Radios in One Top Performing ChipDocumento37 pagineTrio Mxtend: Up To Three Radios in One Top Performing ChipscribdrbbNessuna valutazione finora
- 2017 Summer Camp Day4 Part1Documento34 pagine2017 Summer Camp Day4 Part1gusatNessuna valutazione finora
- Tugas Ke-3 (Minggu 7 / Sesi 12) : Firstnam E Lastnam E Address City Country Marital Companyname Department CodyDocumento3 pagineTugas Ke-3 (Minggu 7 / Sesi 12) : Firstnam E Lastnam E Address City Country Marital Companyname Department CodyNaufall DidyNessuna valutazione finora
- VX 32Documento14 pagineVX 32Petar StuparNessuna valutazione finora
- MDCPS 6th Grade Math Year SyllabusDocumento3 pagineMDCPS 6th Grade Math Year Syllabusknieblas2366Nessuna valutazione finora
- 01 清华大学专属PPT模板Documento28 pagine01 清华大学专属PPT模板欣怡周Nessuna valutazione finora
- Basics of Revit - Electrical ModellingDocumento109 pagineBasics of Revit - Electrical ModellingMoideen Thashreef100% (1)
- Snapdragon 435 Processor Product BriefDocumento2 pagineSnapdragon 435 Processor Product BriefKudangamukNessuna valutazione finora
- Manual de Aire Acondicionado Carrier GratisDocumento5 pagineManual de Aire Acondicionado Carrier GratisJosé Manuel PérezNessuna valutazione finora
- Information Technology Solved MCQs Past PapersDocumento10 pagineInformation Technology Solved MCQs Past Paperskawash50% (2)
- VHDL Reference ManualDocumento502 pagineVHDL Reference Manualashlesha_vcNessuna valutazione finora
- CAble Ampacity Calculations IEEE ConferenceDocumento7 pagineCAble Ampacity Calculations IEEE Conference10rodriguezNessuna valutazione finora
- h14556 Dell Emc Powermax Vmax All Flash SRDF Metro Overview Best PracticesDocumento77 pagineh14556 Dell Emc Powermax Vmax All Flash SRDF Metro Overview Best PracticespeymanNessuna valutazione finora
- Documax A3300Documento221 pagineDocumax A3300Ed MosherNessuna valutazione finora
- Amadeus For Supervisors Quick RefDocumento10 pagineAmadeus For Supervisors Quick RefAHMED ALRADAEENessuna valutazione finora
- Magnum Brochure 175-275 Pto HPDocumento24 pagineMagnum Brochure 175-275 Pto HPDenis HernandezNessuna valutazione finora
- How To Stabilize The Execution Plan Using SQL PLAN BaselineDocumento3 pagineHow To Stabilize The Execution Plan Using SQL PLAN BaselinenizamNessuna valutazione finora