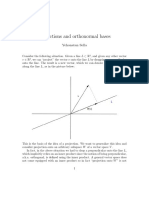
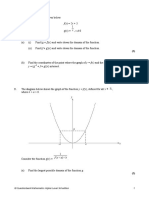
Potrebbero piacerti anche
- The Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64Da EverandThe Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64Nessuna valutazione finora
- (Drew A. Hudec) The Grassmannian As A Projective Variety PDFDocumento11 pagine(Drew A. Hudec) The Grassmannian As A Projective Variety PDFEladio Escobedo de pruebat.orgNessuna valutazione finora
- 5 Tensor ProductsDocumento22 pagine5 Tensor ProductsEmkafsNessuna valutazione finora
- L9 Vectors in SpaceDocumento4 pagineL9 Vectors in SpaceKhmer ChamNessuna valutazione finora
- 5 Linear Transformations: 5.1 Basic Definitions and ExamplesDocumento10 pagine5 Linear Transformations: 5.1 Basic Definitions and ExamplesBhimesh JettiNessuna valutazione finora
- Transformation Geometry Module: Fajar ArwadiDocumento60 pagineTransformation Geometry Module: Fajar ArwadiMifdatul KhusnaNessuna valutazione finora
- Santiago Ca NEZDocumento4 pagineSantiago Ca NEZSourav ShekharNessuna valutazione finora
- Lecture Notes 13: 2.9 The Covariant Derivative, Lie Bracket, and Rie-Mann Curvature Tensor of RDocumento6 pagineLecture Notes 13: 2.9 The Covariant Derivative, Lie Bracket, and Rie-Mann Curvature Tensor of RSanjeev ShuklaNessuna valutazione finora
- Chapter 3Documento4 pagineChapter 3pibivNessuna valutazione finora
- La2 8Documento5 pagineLa2 8Roy VeseyNessuna valutazione finora
- Linear Transformations and OperatorsDocumento18 pagineLinear Transformations and Operatorsabd 01Nessuna valutazione finora
- Homework #4, Sec 11.1 and 11.2Documento5 pagineHomework #4, Sec 11.1 and 11.2Masaya Sato100% (3)
- Lectures On Linear AlgebraDocumento101 pagineLectures On Linear AlgebraMaciej PogorzelskiNessuna valutazione finora
- The Spectral Theorem and Beyond: Guillaume Pouliot August 23, 2008Documento19 pagineThe Spectral Theorem and Beyond: Guillaume Pouliot August 23, 2008Epic WinNessuna valutazione finora
- Spectral Measures and The Spectral Theorem: 1 Preliminary Facts About Hilbert SpacesDocumento10 pagineSpectral Measures and The Spectral Theorem: 1 Preliminary Facts About Hilbert SpacesEpic WinNessuna valutazione finora
- 2 Vector Spaces: V V V VDocumento7 pagine2 Vector Spaces: V V V Vaba3abaNessuna valutazione finora
- Projection MatricesDocumento31 pagineProjection MatricesJasper LuNessuna valutazione finora
- Rosas-Ortiz: 1 Linear SpacesDocumento20 pagineRosas-Ortiz: 1 Linear SpacesJaime TiburcioNessuna valutazione finora
- Math 115 Ah ProjectionsDocumento7 pagineMath 115 Ah ProjectionsMaximo Gonzalo MeroNessuna valutazione finora
- 18.952 Differential FormsDocumento63 pagine18.952 Differential FormsAngelo OppioNessuna valutazione finora
- Abstract Linear Algebra, Fall 2011 - Solutions To Problems IDocumento3 pagineAbstract Linear Algebra, Fall 2011 - Solutions To Problems ISourav BanerjeeNessuna valutazione finora
- Connections and Covariant DerivativesDocumento8 pagineConnections and Covariant DerivativesNguyễn Duy KhánhNessuna valutazione finora
- Teorema e SpectralDocumento1 paginaTeorema e SpectralWalter Andrés Páez GaviriaNessuna valutazione finora
- MAT 217 Lecture 4 PDFDocumento3 pagineMAT 217 Lecture 4 PDFCarlo KaramNessuna valutazione finora
- I Sem2 EN Burlayenko LC 31-03-20inerproductDocumento9 pagineI Sem2 EN Burlayenko LC 31-03-20inerproductVAHID VAHIDNessuna valutazione finora
- AA Affine SpacesDocumento22 pagineAA Affine SpacesxerenusNessuna valutazione finora
- 1 Linear Spaces: Summer Propaedeutic CourseDocumento15 pagine1 Linear Spaces: Summer Propaedeutic CourseJuan P HDNessuna valutazione finora
- 0.1 Review of Axler's AlgorithmDocumento6 pagine0.1 Review of Axler's AlgorithmDickNessuna valutazione finora
- 1 Self-Adjoint Transformations: Lecture 5: October 12, 2021Documento4 pagine1 Self-Adjoint Transformations: Lecture 5: October 12, 2021Pushkaraj PanseNessuna valutazione finora
- Appendix 1Documento4 pagineAppendix 1Priyatham GangapatnamNessuna valutazione finora
- CS1113: Foundations of Computer Science II: Course NotesDocumento14 pagineCS1113: Foundations of Computer Science II: Course NotesCameronNessuna valutazione finora
- Assignment-2 Name-Asha Kumari Jakhar Subject code-ECN511 Enrollment No.-20915003Documento10 pagineAssignment-2 Name-Asha Kumari Jakhar Subject code-ECN511 Enrollment No.-20915003Asha JakharNessuna valutazione finora
- Typeset by AMS-TEXDocumento2 pagineTypeset by AMS-TEXYanh VissuetNessuna valutazione finora
- Classical Propositional Logic (PL) : IntroductionDocumento14 pagineClassical Propositional Logic (PL) : Introductionshivam banyalNessuna valutazione finora
- Assignment 1: January 27, 2020Documento3 pagineAssignment 1: January 27, 2020Ankush RoyNessuna valutazione finora
- Chapter 7 - Geometry of Lines and Planes: 7.1 - IntroductionDocumento4 pagineChapter 7 - Geometry of Lines and Planes: 7.1 - IntroductionLexNessuna valutazione finora
- Are The Groups R and R × R Isomorphic?Documento2 pagineAre The Groups R and R × R Isomorphic?Akshay KumarNessuna valutazione finora
- PDC Primary Decomposition THMDocumento3 paginePDC Primary Decomposition THMBhupi.SamNessuna valutazione finora
- Linear AlgebraDocumento18 pagineLinear AlgebraT BlackNessuna valutazione finora
- ReportDocumento8 pagineReportJunrel J Lasib DabiNessuna valutazione finora
- 76 - Sample - Chapter Kunci M2K3 No 9Documento94 pagine76 - Sample - Chapter Kunci M2K3 No 9Rachmat HidayatNessuna valutazione finora
- 4 C7 C0 CF2 D 01Documento14 pagine4 C7 C0 CF2 D 01Dylan ChappNessuna valutazione finora
- 6 Gram-Schmidt Procedure, QR-factorization, Orthog-Onal Projections, Least SquareDocumento13 pagine6 Gram-Schmidt Procedure, QR-factorization, Orthog-Onal Projections, Least SquareAna Paula RomeiraNessuna valutazione finora
- Linear Algebra Done Right - SolutionsDocumento9 pagineLinear Algebra Done Right - SolutionsfunkageNessuna valutazione finora
- 1 Rayleigh Quotients: Eigenvalues As Optimization: Lecture 6: October 14, 2021Documento4 pagine1 Rayleigh Quotients: Eigenvalues As Optimization: Lecture 6: October 14, 2021Pushkaraj PanseNessuna valutazione finora
- Sec10 PDFDocumento5 pagineSec10 PDFRaouf BouchoukNessuna valutazione finora
- Solution Manual For Manifolds, Tensor and Forms ( P. Rentein) PDFDocumento170 pagineSolution Manual For Manifolds, Tensor and Forms ( P. Rentein) PDFAnonymous bZtJlFvPtpNessuna valutazione finora
- Spanning and Linear IndependenceDocumento6 pagineSpanning and Linear IndependenceRoger PoolNessuna valutazione finora
- Section 7-3Documento11 pagineSection 7-3lehongphucworkNessuna valutazione finora
- ALA - Assignment 3 2Documento2 pagineALA - Assignment 3 2Ravi VedicNessuna valutazione finora
- ALA - Assignment 3 2Documento2 pagineALA - Assignment 3 2Ravi VedicNessuna valutazione finora
- 1.2 Vector OperationsDocumento5 pagine1.2 Vector OperationsJoana Rose Dela CruzNessuna valutazione finora
- Lecture 08 - Tensor Space Theory I: Over A Field (Schuller's Geometric Anatomy of Theoretical Physics)Documento15 pagineLecture 08 - Tensor Space Theory I: Over A Field (Schuller's Geometric Anatomy of Theoretical Physics)Simon ReaNessuna valutazione finora
- 1 Orthogonality and Orthonormality: Lecture 4: October 7, 2021Documento3 pagine1 Orthogonality and Orthonormality: Lecture 4: October 7, 2021Pushkaraj PanseNessuna valutazione finora
- Linear Algebra Question PaperDocumento3 pagineLinear Algebra Question PaperShripad BhatNessuna valutazione finora
- Lax Milgram Theorem - Universität BaselDocumento23 pagineLax Milgram Theorem - Universität Baselkarthikvs88Nessuna valutazione finora
- Hahn BanDocumento9 pagineHahn BanTaffohouo Nwaffeu Yves ValdezNessuna valutazione finora
- Vector SpacesDocumento10 pagineVector SpacesAbsensi RidwanNessuna valutazione finora
- Operations On Complex Vector Spaces 1.16 Direct Sums and HomomorphismsDocumento5 pagineOperations On Complex Vector Spaces 1.16 Direct Sums and HomomorphismsOscar Alarcon CelyNessuna valutazione finora
- Bili Near Forms 1Documento15 pagineBili Near Forms 1vijayakumar2k93983Nessuna valutazione finora
- Trigonometric IdentitiesDocumento34 pagineTrigonometric Identitiesjzand999Nessuna valutazione finora
- 45 5 Inverse of A MatrixDocumento10 pagine45 5 Inverse of A Matrixapi-299265916Nessuna valutazione finora
- Chapter 3 - Determinants and DiagonalizationDocumento70 pagineChapter 3 - Determinants and DiagonalizationNguyen Tuan Hiep (K14HL)Nessuna valutazione finora
- 254 - Algebraic Function Fields and Codes - 2ed - Henning Stichtenoth 3540768777 PDFDocumento363 pagine254 - Algebraic Function Fields and Codes - 2ed - Henning Stichtenoth 3540768777 PDFVishakh Kumar100% (2)
- Solving Logarithmic Equations: General MathematicsDocumento40 pagineSolving Logarithmic Equations: General MathematicsDamDamNessuna valutazione finora
- NumPy For MATLAB UsersDocumento16 pagineNumPy For MATLAB Usersvladadj_1603Nessuna valutazione finora
- Where, Is A Complex Exponential Magnitude & Angle: X (Z) X N ZDocumento26 pagineWhere, Is A Complex Exponential Magnitude & Angle: X (Z) X N Zanil kadleNessuna valutazione finora
- Partial DifferentiationDocumento8 paginePartial DifferentiationAmirah NasirNessuna valutazione finora
- Laplace Transform: Properties of Lapace Transform LinearityDocumento7 pagineLaplace Transform: Properties of Lapace Transform LinearityjohnNessuna valutazione finora
- DSP Unit 2Documento13 pagineDSP Unit 220-403 TejashwiniNessuna valutazione finora
- Probability Generating FunctionsDocumento3 pagineProbability Generating FunctionsxkarebearNessuna valutazione finora
- Existence and Multiplicity Results For Some Nonlinear Elliptic Equations: A SurveyDocumento32 pagineExistence and Multiplicity Results For Some Nonlinear Elliptic Equations: A SurveyChris00Nessuna valutazione finora
- Practice MidtermDocumento1 paginaPractice Midterm3dd2ef652ed6f7Nessuna valutazione finora
- Basic Simulation Lab ManualDocumento97 pagineBasic Simulation Lab Manualshiva4105100% (1)
- Math 2280 - Practice Final Exam: University of Utah Spring 2013Documento24 pagineMath 2280 - Practice Final Exam: University of Utah Spring 2013Bree ElaineNessuna valutazione finora
- Trig Functions EssayDocumento11 pagineTrig Functions Essayapi-250366197Nessuna valutazione finora
- AGM For Elliptic Curves: DTU (Copenhagen) September 2005Documento40 pagineAGM For Elliptic Curves: DTU (Copenhagen) September 2005sushmapalimarNessuna valutazione finora
- Chapter 3-Applications of DifferentiationDocumento20 pagineChapter 3-Applications of Differentiationdiktatorimhotep8800Nessuna valutazione finora
- Concave Functions of Two Variables: X XX XDocumento4 pagineConcave Functions of Two Variables: X XX Xaskazy007Nessuna valutazione finora
- MathHL QB3 T2Documento25 pagineMathHL QB3 T2Nikola PetrovicNessuna valutazione finora
- The Inverse of A 2 × 2 Matrix 5 - 4Documento2 pagineThe Inverse of A 2 × 2 Matrix 5 - 4ZacNessuna valutazione finora
- Homework (2) - ME5701Documento6 pagineHomework (2) - ME5701Reinaldy MaslimNessuna valutazione finora
- Chapter Ii: Affine and Euclidean GeometryDocumento34 pagineChapter Ii: Affine and Euclidean GeometryFiaz Ahmad FrazNessuna valutazione finora
- Csir Gate Previous Quetion PapersDocumento506 pagineCsir Gate Previous Quetion Paperseimc2Nessuna valutazione finora
- Maa 2.10 Exponential EquationsDocumento28 pagineMaa 2.10 Exponential EquationsMuborakNessuna valutazione finora
- J2 Solutions LatexDocumento6 pagineJ2 Solutions LatexBobNessuna valutazione finora
- Module 5Documento51 pagineModule 5prasidhNessuna valutazione finora
- Cain J. Ordinary and PDE. An Introduction To Dynamical Systems 2010Documento416 pagineCain J. Ordinary and PDE. An Introduction To Dynamical Systems 2010uuyyttrdf21Nessuna valutazione finora
- Fourier Integrals and Fourier TransformsDocumento7 pagineFourier Integrals and Fourier TransformsVraj MehtaNessuna valutazione finora
- Calculus For Economics2021VMUDocumento154 pagineCalculus For Economics2021VMUMinh LươngNessuna valutazione finora
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Da EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Nessuna valutazione finora
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsDa EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsValutazione: 4.5 su 5 stelle4.5/5 (3)
- Images of Mathematics Viewed Through Number, Algebra, and GeometryDa EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryNessuna valutazione finora
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeDa EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeValutazione: 4 su 5 stelle4/5 (2)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Da EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Valutazione: 5 su 5 stelle5/5 (1)
- Interactive Math Notebook Resource Book, Grade 6Da EverandInteractive Math Notebook Resource Book, Grade 6Nessuna valutazione finora
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormDa EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormValutazione: 5 su 5 stelle5/5 (5)
- Math Workshop, Grade K: A Framework for Guided Math and Independent PracticeDa EverandMath Workshop, Grade K: A Framework for Guided Math and Independent PracticeValutazione: 5 su 5 stelle5/5 (1)
- Limitless Mind: Learn, Lead, and Live Without BarriersDa EverandLimitless Mind: Learn, Lead, and Live Without BarriersValutazione: 4 su 5 stelle4/5 (6)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingDa EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingValutazione: 4.5 su 5 stelle4.5/5 (21)
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathDa EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathValutazione: 5 su 5 stelle5/5 (1)